🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
[Assistants API] Code Interpreter, Retrieval, Functions 활용법
OpenAI의 새로운 Assistants API는 대화와 더불어 강력한 도구 접근성을 제공합니다. 본 튜토리얼은 OpenAI Assistants API를 활용하는 내용을 다룹니다. 특히, Assistant API 가 제공하는 도구인 Code Interpreter, Retrieval, Functions 를 활용하는 방법에 대해 다룹니다. 이와 더불어 파일을 업로드 하는 내용과 사용자의 피드백을 제출하는 내용도 튜토리얼 말미에 포함하고 있습니다.
주요내용
- 🚀 Assistants API 개요: 상태 유지 대화를 가능하게 하는 새로운 API 소개
- 💻 설정 방법: Python 라이브러리 설정 및 사용 방법 안내
- 🧠 흐름 이해: Assistant, Thread, Message, Run의 개념과 사용법 설명
- 🔧 도구 사용: Code Interpreter, Retrieval, Functions 등 강력한 기능
- 📁 파일 업로드: API 를 사용한 파일 업로드 및 File ID 획득 방법
- 📝 실용적인 예시: 실제 코드를 통한 Assistants API 활용 예시 제공
Assistants API 개요
새로운 Assistants API는 Chat Completions API를 발전시킨 것으로, 개발자가 어시스턴트와 유사한 경험을 간편하게 만들고 코드 해석기 및 검색과 같은 강력한 도구에 액세스할 수 있도록 하기 위한 것입니다.
Assistants API 의 탄생 배경
Chat Completions API의 기본 요소는 Message 이며, 여기에 Model(gpt-3.5-turbo, gpt-4-turbo-preview 등)을 사용하여 Completion을 수행합니다.
Chat Completions API 는 메시지를 주고 받는데에는 가볍게 잘 동작하지만, 상태를 관리할 수는 없습니다. 우리는 이것을 Stateless 하다는 표현을 사용합니다.
여기서 상태란, ChatGPT 와 플러그인 형식으로 동작하는 도구의 개념으로 이해하셔도 좋습니다.
예를 들면, ‘검색(search)’, ‘문서 검색(retrieval)’, ‘코드 실행(code interpreter)’ 등의 기능이 부재하기 때문에, 이에 대한 보완책으로 Assistants API 가 탄생하게 되었습니다.
Assistants API의 기본 요소
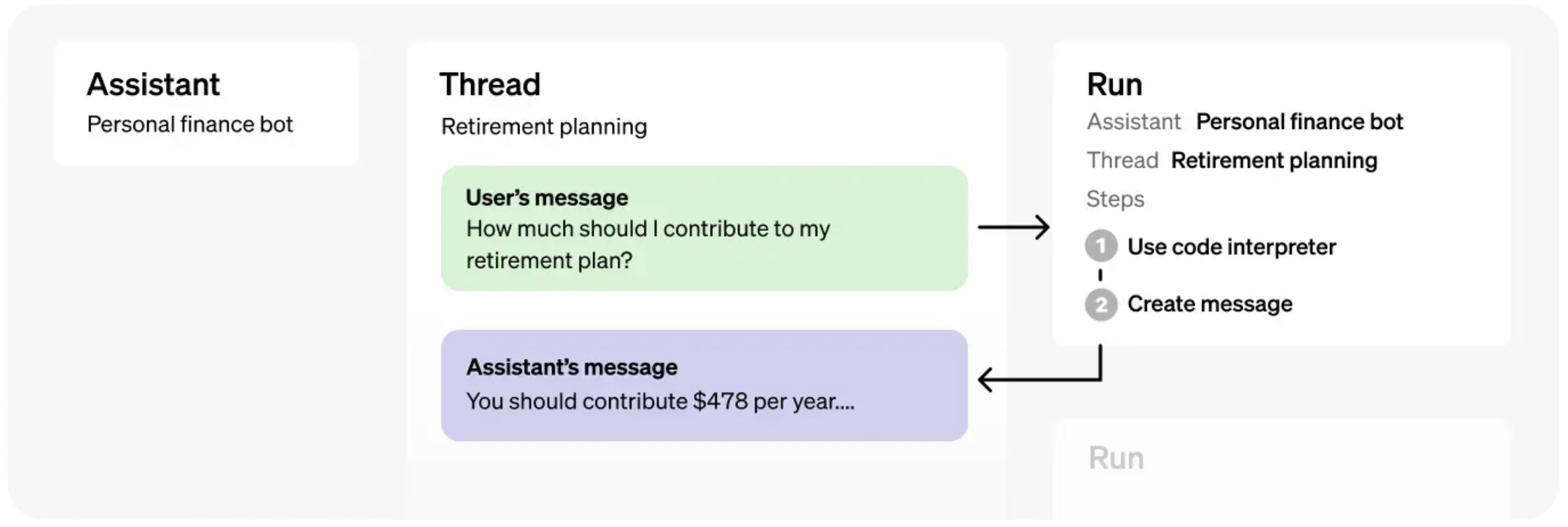
-
Assistants: 모델(GPT-3.5, GPT-4, etc), instruction(지시문/프롬프트), tools(도구), files(업로드한 파일)를 캡슐화하는 역할입니다. -
Threads: 하나의 대화 채널입니다. 메시지(Message)를 담을 수 있으며, ChatGPT 기준 하나의 대화 스레드의 개념으로 생각하면 됩니다. -
Runs:Assistant+Thread에서의 실행을 구동합니다.Run단계에서tools(도구)의 활용 여부가 결정되기도 합니다. 또한,Run을 수행한 후 Assistant 가 응답한 결과를 처리할 때도 사용할 수 있습니다.
위의 요소들이 유기적으로 동작하면서 결국 상태가 있는(stateful) 사용자 경험을 제공하게 됩니다.
아래의 튜토리얼에서는 각각의 요소들의 역할과 동작 원리에 대해 차례대로 알아보겠습니다.
환경설정
Python 라이브러리 설정
OpenAI는 Assistants API를 지원하기 위해 Python 라이브러리를 업데이트했습니다. 따라서 최신 버전으로 업데이트 한 뒤 튜토리얼을 진행할 것을 권장합니다.
이 문서는 openai 라이브러리를 최신 버전으로 업그레이드하고 설치하는 방법을 설명합니다. pip 명령어를 사용하여 Python 환경에 openai 라이브러리를 설치하며, 이는 OpenAI의 API를 활용하는 데 필요한 기본적인 단계입니다.
# openai 라이브러리를 최신 버전으로 업그레이드하여 설치합니다.
!pip install --upgrade openai -q
그리고 다음을 실행하여 최신 상태인지 확인하세요.
openai 패키지의 버전 정보를 확인 합니다.
# openai 패키지의 버전 정보를 확인합니다.
!pip show openai | grep Version
Version: 1.12.0
Helper 함수
show_json 함수는 인자로 받은 객체의 모델을 JSON 형태로 변환하여 출력합니다.
Assistant 가 응답한 결과를 분석할 때 답변을 출력(print)할 목적으로 활용하는 함수입니다.
import json
def show_json(obj):
# obj의 모델을 JSON 형태로 변환한 후 출력합니다.
display(json.loads(obj.model_dump_json()))
API KEY 설정
API KEY 발급은 아래 링크를 참고해 주세요
# API KEY 정보를 불러옵니다
from dotenv import load_dotenv
load_dotenv()
True
api_key 에 OPENAI_API_KEY 를 설정합니다.
필요에 따라서는 주석을 해제 후 API KEY 를 직업 입력해 주세요
import os
# os.environ["OPENAI_API_KEY"] = "API KEY를 입력해 주세요"
# OPENAI_API_KEY 를 설정합니다.
api_key = os.environ.get("OPENAI_API_KEY")
Assistants API
Playground 에서 Assistants 생성
Assistants를 활용해보기 가장 쉬운 방법은 Assistants Playground를 통하는 것입니다.
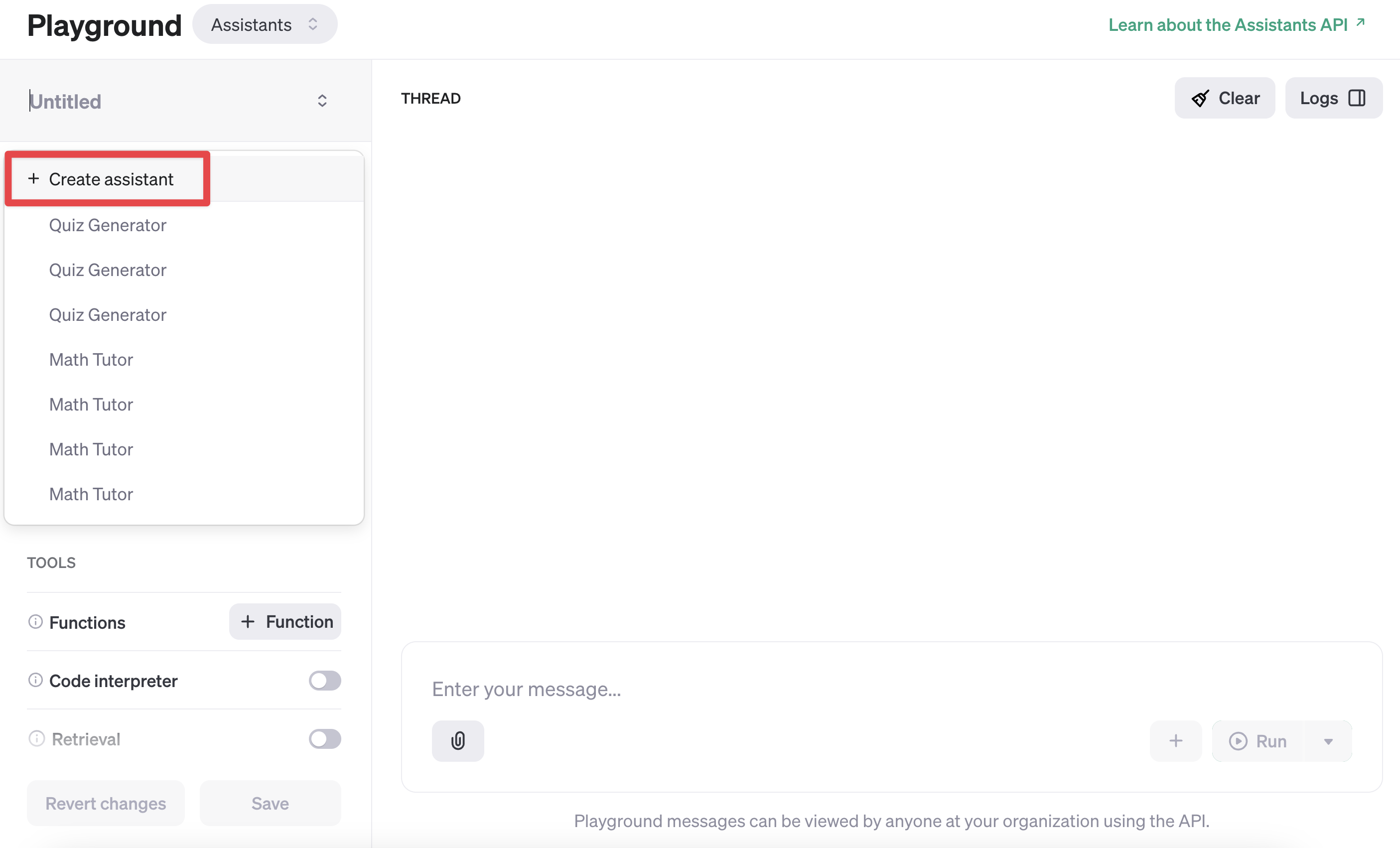
Assistants 를 한 번 생성해 보겠습니다.
문서 에서와 같이 Math Tutor 라는 수학 문제 풀이 과외선생님을 만들어 보겠습니다.
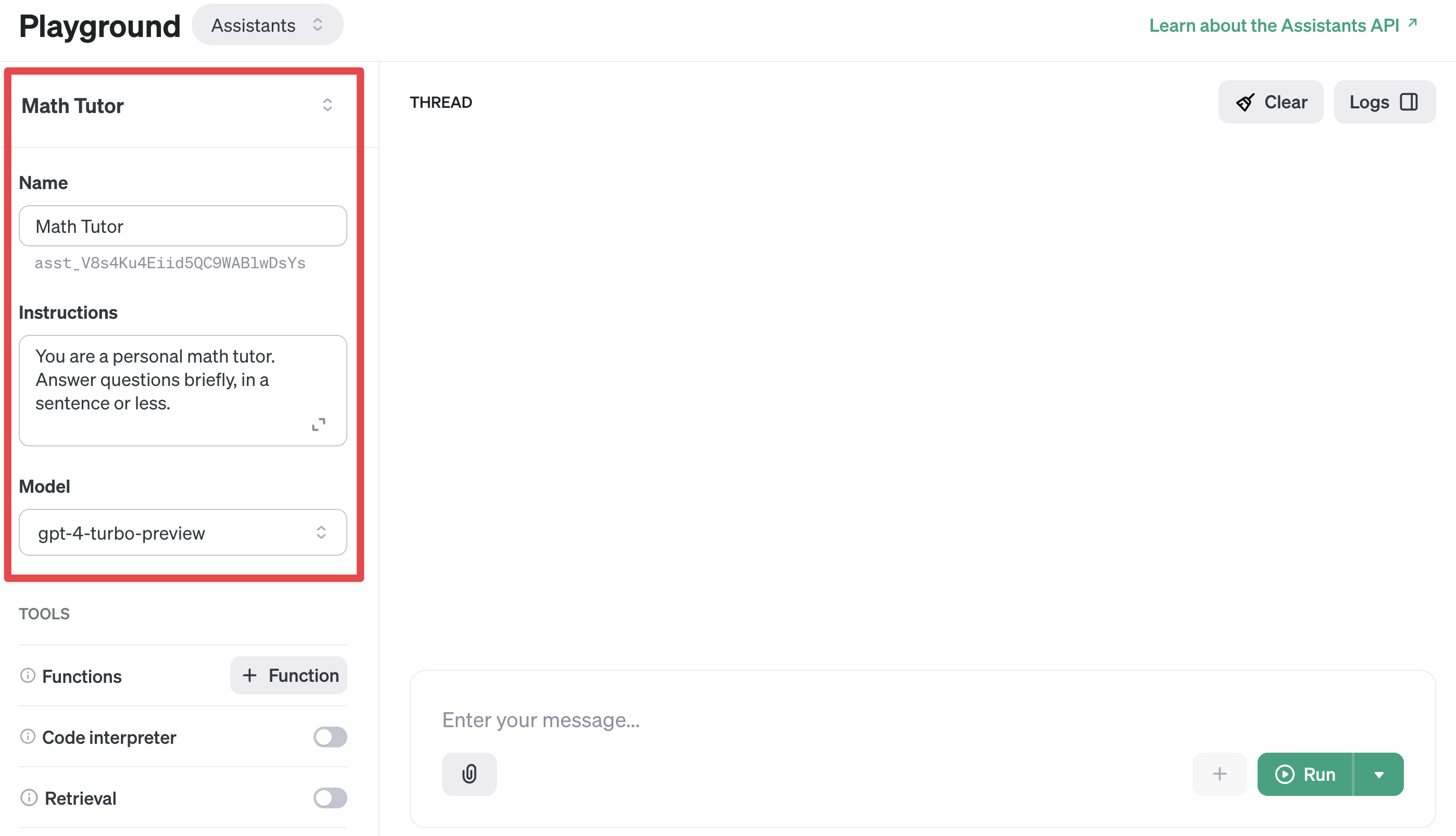
생성한 Assistant를 Assistants Dashboard 에서 볼 수 있습니다.
아주 간단하게 Playground 에서 Assistants 생성이 끝났습니다!
Assistants API 로 생성
Assistants API를 통해 직접 Assistant를 생성할 수도 있습니다.
from openai import OpenAI
# OpenAI API를 사용하기 위한 클라이언트 객체를 생성합니다.
client = OpenAI(api_key=api_key)
# 수학 과외 선생님 역할을 하는 챗봇을 생성합니다.
# 이 챗봇은 간단한 문장이나 한 문장으로 질문에 답변합니다.
assistant = client.beta.assistants.create(
name="Math Tutor",
instructions="You are a personal math tutor. Answer questions briefly, in a sentence or less.",
model="gpt-4-turbo-preview",
)
# 생성된 챗봇의 정보를 JSON 형태로 출력합니다.
show_json(assistant)
{'id': 'asst_XmP42ogdnVKbkuaXdWSe2zor',
'created_at': 1707833904,
'description': None,
'file_ids': [],
'instructions': 'You are a personal math tutor. Answer questions briefly, in a sentence or less.',
'metadata': {},
'model': 'gpt-4-turbo-preview',
'name': 'Math Tutor',
'object': 'assistant',
'tools': []}
Playground Dashboard 에서 생성하든 Python API 로 생성하든 차이는 없습니다. 하지만, 생성한 ASSISTANT ID 를 기억해야 합니다.
ASSISTANT_ID 를 계속 추적하여 튜토리얼을 진행할 예정입니다. 따라서, 별도의 변수에 담아 저장하도록 하겠습니다.
(대시보드에서 직접 생성한 ASSISTANT_ID 를 기입해도 좋습니다.)
ASSISTANT_ID = assistant.id
print(f"[생성한 Assistants ID]\n{ASSISTANT_ID}")
[생성한 Assistants ID] asst_XmP42ogdnVKbkuaXdWSe2zor
Threads(스레드)
다음으로, 새로운 Thread를 생성하고 그 안에 Message를 추가합니다.
Thread 는 우리 대화의 상태를 유지해 주는 역할을 합니다.
이전 까지의 대화내용을 기억하고 있기 때문에, 매번 전체 메시지 기록을 다시 보내지 않아도 됩니다.
정리
-
Threads: Message 풀을 관리하는 집합체. Message 의 상태 관리도 포함입니다.
-
Message: 단일 메시지 이며, 각 Message 는 역할(role) 과 컨텐츠(content) 로 구성되어 있습니다.
즉, 1개의 Thread 는 여러 개의 순차적으로 연결된 Message 들을 가지고 있습니다. Thread 에 새로운 Message 를 추가할 수 있습니다.
새로운 대화 스레드를 생성해 보겠습니다.
# 새로운 스레드를 생성합니다.
thread = client.beta.threads.create()
# 생성된 스레드의 정보를 JSON 형식으로 출력합니다.
show_json(thread)
{'id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu',
'created_at': 1707833966,
'metadata': {},
'object': 'thread'}
다음은 스레드에 메시지를 추가해 보도록 하겠습니다.
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="다음의 방정식을 풀고 싶습니다. `3x + 11 = 14`. 수학선생님 도와주실 수 있나요?",
)
show_json(message)
{'id': 'msg_RVM4HX8I7YpdRNcYmls1V5U0',
'assistant_id': None,
'content': [{'text': {'annotations': [],
'value': '다음의 방정식을 풀고 싶습니다. `3x + 11 = 14`. 수학선생님 도와주실 수 있나요?'},
'type': 'text'}],
'created_at': 1707833967,
'file_ids': [],
'metadata': {},
'object': 'thread.message',
'role': 'user',
'run_id': None,
'thread_id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu'}
참고: 전체 대화 기록을 매번 보내지 않더라도, 각 실행마다 전체 대화 기록의 토큰에 대해 여전히 요금이 부과됩니다.
Run(실행)
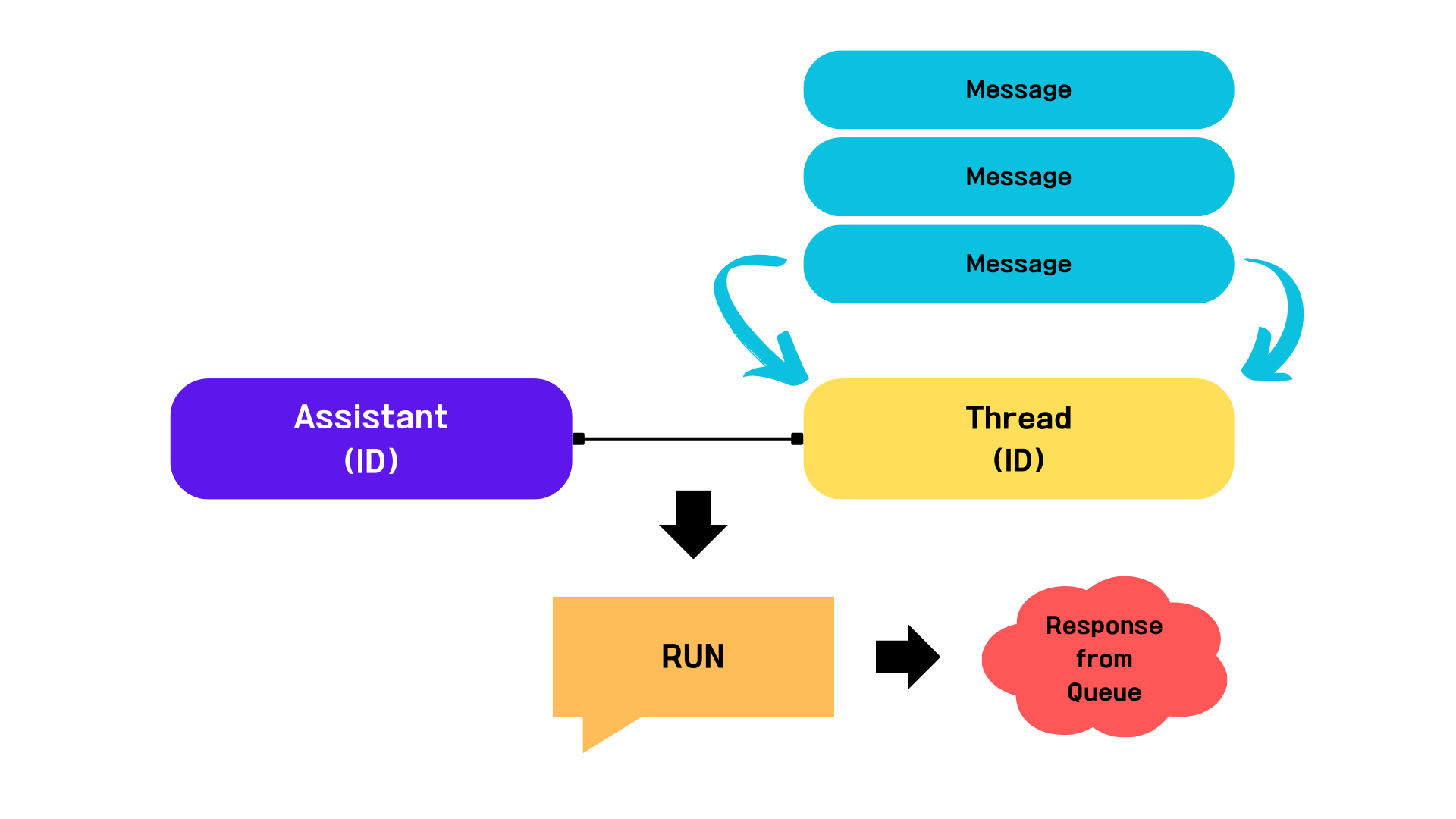
우리가 만든 Thread가 이전에 만든 Assistant와 연결되어 있지 않다는 것을 꼭 알아두세요!
Thread는Assistant와 독립적으로 존재 합니다.
Run 이 수행되기 위해서는 2가지 전제 조건이 존재합니다.
- 누가(
Assistant), 어떤 대화(Thread) 를 실행할 것인가! 입니다.
즉, Run 이 수행되기 위한 조건에는 Assistant ID 와 Thread ID 가 지정되어야 합니다.
다시 정리하면,
Run을 생성하면 Assistant 에게 Thread 에 들어있는 Message 목록을 살펴보고 조치를 취하라는 지시를 합니다. 여기서 조치는 단일 텍스트 응답(일반 채팅) 일 수도 있고, tools(도구) 사용일 수도 있습니다.
Run은 Assistants API와 Chat Completions API 사이의 주요 차이점입니다. Chat Completions에서는 모델이 단일 메시지로만 응답하지만, Assistants API에서는 Run이 하나 또는 여러 도구를 사용하고, Thread에 여러 메시지를 추가할 수 있습니다.
사용자에게 응답하도록 Assistant를 활성화하려면 Run을 생성합시다.
앞서 언급했듯이, Assistant 와 Thread 둘 다 지정 해야 합니다.
# 실행할 Run 을 생성합니다.
# Thread ID 와 Assistant ID 를 지정합니다.
run = client.beta.threads.runs.create(
thread_id=thread.id, # 생성한 스레드 ID
assistant_id=assistant.id, # 적용할 Assistant ID
)
show_json(run)
{'id': 'run_fjr0Gv0jfDsdIyNzHGSqT5xq',
'assistant_id': 'asst_XmP42ogdnVKbkuaXdWSe2zor',
'cancelled_at': None,
'completed_at': None,
'created_at': 1707833969,
'expires_at': 1707834569,
'failed_at': None,
'file_ids': [],
'instructions': 'You are a personal math tutor. Answer questions briefly, in a sentence or less.',
'last_error': None,
'metadata': {},
'model': 'gpt-4-turbo-preview',
'object': 'thread.run',
'required_action': None,
'started_at': None,
'status': 'queued',
'thread_id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu',
'tools': [],
'usage': None}
Chat Completions API에서 완성을 생성하는 것과 달리, Run을 생성하는 것은 비동기 작업입니다.
이는 Run의 메타데이터와 함께 즉시 반환되며, status 는 queued(대기중) 으로 표기됩니다.
status는 Assistant가 작업을 수행함에 따라(도구 사용 및 메시지 추가와 같은) 업데이트될 것입니다. 상태 값은 아래의 목록을 참고하세요.
status 목록
-
queued: 아직 실행이 되지 않고 대기중인 상태 -
in_progress: 처리중 -
requires_action: 사용자 입력 대기중 -
cancelling: 작업 취소중 -
cancelled: 작업 취소 완료 -
failed: 실패(오류) -
completed: 작업 완료 -
expired: 작업 만료
Assistant가 처리를 완료했는지 알기 위해서는 Run을 반복해서 폴링할 수 있습니다. (OpenAI 는 곧 실시간 스트리밍 지원이 곧 제공될 예정이라고 합니다!)
아래는 Run 의 status(상태) 를 폴링하면서 주기적으로 확인하는 코드입니다.
이렇게 주기적으로 확인하면서 status 가 completed 될 때까지 기다립니다.
import time
def wait_on_run(run, thread):
# 주어진 실행(run)이 완료될 때까지 대기합니다.
# status 가 "queued" 또는 "in_progress" 인 경우에는 계속 polling 하며 대기합니다.
while run.status == "queued" or run.status == "in_progress":
# run.status 를 업데이트합니다.
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id,
)
# API 요청 사이에 잠깐의 대기 시간을 두어 서버 부하를 줄입니다.
time.sleep(0.5)
return run
# run 객체를 대기 상태로 설정하고, 해당 스레드에서 실행을 완료할 때까지 기다립니다.
run = wait_on_run(run, thread)
# status 가 "complete" 인 경우에는 결과를 출력합니다.
show_json(run)
{'id': 'run_fjr0Gv0jfDsdIyNzHGSqT5xq',
'assistant_id': 'asst_XmP42ogdnVKbkuaXdWSe2zor',
'cancelled_at': None,
'completed_at': 1707833970,
'created_at': 1707833969,
'expires_at': None,
'failed_at': None,
'file_ids': [],
'instructions': 'You are a personal math tutor. Answer questions briefly, in a sentence or less.',
'last_error': None,
'metadata': {},
'model': 'gpt-4-turbo-preview',
'object': 'thread.run',
'required_action': None,
'started_at': 1707833969,
'status': 'completed',
'thread_id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu',
'tools': [],
'usage': {'completion_tokens': 23, 'prompt_tokens': 80, 'total_tokens': 103}}
Message(메시지)
Run이 완료되었으므로, Assistant에 의해 처리된 결과를 보기 위해 Thread에서 Messages를 확인할 수 있습니다.
# thread.id를 사용하여 메시지 목록을 가져옵니다.
messages = client.beta.threads.messages.list(thread_id=thread.id)
# 결과를 출력합니다.
show_json(messages)
{'data': [{'id': 'msg_aysDdJAjR3nVlw8VUCQR9wd1',
'assistant_id': 'asst_XmP42ogdnVKbkuaXdWSe2zor',
'content': [{'text': {'annotations': [],
'value': '네, 물론입니다. 이 방정식에서 x = 1입니다.'},
'type': 'text'}],
'created_at': 1707833969,
'file_ids': [],
'metadata': {},
'object': 'thread.message',
'role': 'assistant',
'run_id': 'run_fjr0Gv0jfDsdIyNzHGSqT5xq',
'thread_id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu'},
{'id': 'msg_RVM4HX8I7YpdRNcYmls1V5U0',
'assistant_id': None,
'content': [{'text': {'annotations': [],
'value': '다음의 방정식을 풀고 싶습니다. `3x + 11 = 14`. 수학선생님 도와주실 수 있나요?'},
'type': 'text'}],
'created_at': 1707833967,
'file_ids': [],
'metadata': {},
'object': 'thread.message',
'role': 'user',
'run_id': None,
'thread_id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu'}],
'object': 'list',
'first_id': 'msg_aysDdJAjR3nVlw8VUCQR9wd1',
'last_id': 'msg_RVM4HX8I7YpdRNcYmls1V5U0',
'has_more': False}
보시다시피, 메시지는 역순으로 정렬됩니다.
이는 가장 최근의 결과가 항상 최상단에 있도록 하기 위해서입니다(결과는 page 별로 나누어 확인할 수 있습니다).
따라서, Chat Completions API 에서 메시지의 순서와 반대이기 때문에 혼란을 야기할 수도 있습니다.
이전에 받은 답변이 단답형 답변이라서, 조금 더 자세히 설명해 달라고 요청해 보겠습니다(이전의 대화내용을 기억하고 있는지 확인해 보기 위함입니다).
# 스레드에 추가할 메시지 생성
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="설명이 잘 이해가 가지 않습니다. 좀 더 자세히 설명해 주실 수 있나요?",
)
# 실행을 시작함
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
# 완료될 때까지 대기
wait_on_run(run, thread)
# 마지막 사용자 메시지 이후에 추가된 모든 메시지를 검색
messages = client.beta.threads.messages.list(
thread_id=thread.id, order="asc", after=message.id
)
show_json(messages)
{'data': [{'id': 'msg_Cvx9FNAEA37IMdTvnNDVDxBE',
'assistant_id': 'asst_XmP42ogdnVKbkuaXdWSe2zor',
'content': [{'text': {'annotations': [],
'value': '물론이죠. 우선 방정식 `3x + 11 = 14`에서 양변에서 11을 빼줍니다. 그러면 `3x = 3`이 되고, 여기서 양변을 3으로 나누면 `x = 1`이 됩니다.'},
'type': 'text'}],
'created_at': 1707834075,
'file_ids': [],
'metadata': {},
'object': 'thread.message',
'role': 'assistant',
'run_id': 'run_DnKlKBRDx5yEOmkKDylFaeo6',
'thread_id': 'thread_REn8R3a6YeuIQCAP2RLZjiLu'}],
'object': 'list',
'first_id': 'msg_Cvx9FNAEA37IMdTvnNDVDxBE',
'last_id': 'msg_Cvx9FNAEA37IMdTvnNDVDxBE',
'has_more': False}
지금까지 다음의 순서에 따라 기본 요소들의 동작 방식을 확인했습니다.
다시 한 번 정리 하자면 다음과 같습니다.
-
Asssitant 생성. Assistant 의 역할 부여.
-
새로운 Thread 생성. 해당 Thread 에 Message 추가.
-
Message 생성. Message 생성시 Thread 의 ID 를 입력하여 Message 추가
-
Run 생성. Run을 수행할 Assistant 와 실행할 Thread ID 를 지정 후 Run 실행
함수화
이전에 나열한 코드는 흩어져 있기 때문에, 코드를 한 번에 이해하고 실행하기에 어려움이 있습니다.
따라서, 아래는 내용을 묶어 함수 형태로 만들어 실행이 편리하게 이루어 질 수 있도록 만들어 보겠습니다.
import time
from openai import OpenAI
# 이전에 설정한 Assistant ID 를 기입합니다.
ASSISTANT_ID = assistant.id
# OpenAI API를 사용하기 위한 클라이언트 객체를 생성합니다.
client = OpenAI(api_key=api_key)
def submit_message(assistant_id, thread, user_message):
# 사용자 입력 메시지를 스레드에 추가합니다.
client.beta.threads.messages.create(
# Thread ID가 필요합니다.
# 사용자 입력 메시지 이므로 role은 "user"로 설정합니다.
# 사용자 입력 메시지를 content에 지정합니다.
thread_id=thread.id,
role="user",
content=user_message,
)
# 스레드에 메시지가 입력이 완료되었다면,
# Assistant ID와 Thread ID를 사용하여 실행을 준비합니다.
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant_id,
)
return run
def wait_on_run(run, thread):
# 주어진 실행(run)이 완료될 때까지 대기합니다.
# status 가 "queued" 또는 "in_progress" 인 경우에는 계속 polling 하며 대기합니다.
while run.status == "queued" or run.status == "in_progress":
# run.status 를 업데이트합니다.
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id,
)
# API 요청 사이에 잠깐의 대기 시간을 두어 서버 부하를 줄입니다.
time.sleep(0.5)
return run
def get_response(thread):
# 스레드에서 메시지 목록을 가져옵니다.
# 메시지를 오름차순으로 정렬할 수 있습니다. order="asc"로 지정합니다.
return client.beta.threads.messages.list(thread_id=thread.id, order="asc")
재사용할 수 있는 create_thread_and_run 함수를 정의했습니다(사실상 우리 API의 client.beta.threads.create_and_run 복합 함수와 거의 동일합니다)
create_thread_and_run 함수는 새로운 스레드를 생성하고 실행하기 위한 준비단계(status 가 queued 된 상태) 까지 진행합니다.
이러한 API 호출이 모두 비동기 작업인 점을 알아두시면 좋습니다.
# 새로운 스레드를 생성하고 메시지를 제출하는 함수를 정의합니다.
def create_thread_and_run(user_input):
# 사용자 입력을 받아 새로운 스레드를 생성하고, Assistant 에게 메시지를 제출합니다.
thread = client.beta.threads.create()
run = submit_message(ASSISTANT_ID, thread, user_input)
return thread, run
비동기로 queued 상태인 Run 을 생성했습니다.
아직 실행이 시작된 것은 아니라는 점을 주의해 주세요.
# 동시에 여러 요청을 처리하기 위해 스레드를 생성합니다.
thread1, run1 = create_thread_and_run(
"다음 방정식을 풀고 싶습니다. `3x + 11 = 14`. 좀 도와주실 수 있나요?"
)
thread2, run2 = create_thread_and_run("선형대수에 대해 간략히 설명해 주실 수 있나요?")
thread3, run3 = create_thread_and_run(
"수학에 정말 소질이 없는 것 같아요. 어떻게 하면 수학을 잘할 수 있을까요?"
)
모든 실행이 진행되고 나면, 각각을 기다린 후 응답을 받을 수 있습니다.
import time
# 메시지 출력용 함수
def print_message(response):
for res in response:
print(f"[{res.role.upper()}]\n{res.content[0].text.value}\n")
print("---" * 20)
# 반복문에서 대기하는 함수
def wait_on_run(run, thread):
while run.status == "queued" or run.status == "in_progress":
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id,
)
time.sleep(0.5)
return run
# 첫 번째 실행을 위해 대기
run1 = wait_on_run(run1, thread1)
print_message(get_response(thread1))
# 두 번째 실행을 위해 대기
run2 = wait_on_run(run2, thread2)
print_message(get_response(thread2))
# 세 번째 실행을 위해 대기
run3 = wait_on_run(run3, thread3)
# 세 번째 스레드를 마치면 감사 인사를 전하고 종료합니다 :)
run4 = submit_message(ASSISTANT_ID, thread3, "도와주셔서 감사합니다!")
run4 = wait_on_run(run4, thread3)
print_message(get_response(thread3))
[USER] 다음 방정식을 풀고 싶습니다. `3x + 11 = 14`. 좀 도와주실 수 있나요? [ASSISTANT] 네, 먼저 공식에서 11을 뺀 다음 3으로 나누세요: `x = (14 - 11) / 3` 그래서 `x = 1` 입니다. ------------------------------------------------------------ [USER] 선형대수에 대해 간략히 설명해 주실 수 있나요? [ASSISTANT] 선형대수는 벡터, 벡터 공간, 선형 변환, 행렬 등을 연구하는 수학의 한 분야입니다. ------------------------------------------------------------ [USER] 수학에 정말 소질이 없는 것 같아요. 어떻게 하면 수학을 잘할 수 있을까요? [ASSISTANT] 수학을 잘하기 위해서는 꾸준한 연습과 이해를 바탕으로 한 반복 학습이 중요합니다. [USER] 도와주셔서 감사합니다! [ASSISTANT] 언제든지 도움이 필요하면 말씀해주세요! ------------------------------------------------------------
전체코드(템플릿 코드)
API KEY를 설정하고, helper 함수를 정의합니다.
# API KEY 정보를 불러옵니다
from dotenv import load_dotenv
load_dotenv()
True
import os
import json
# os.environ["OPENAI_API_KEY"] = "API KEY를 입력해 주세요"
# OPENAI_API_KEY 를 설정합니다.
api_key = os.environ.get("OPENAI_API_KEY")
def show_json(obj):
# obj의 모델을 JSON 형태로 변환한 후 출력합니다.
display(json.loads(obj.model_dump_json()))
-
Assistant 생성
-
Assistants Playground 에서 이미 Assistant 를 생성한 경우
-
Assistant 를 생성하지 않은 경우
-
# 1-1. Assistant ID를 불러옵니다(Playground에서 생성한 Assistant ID)
ASSISTANT_ID = "asst_V8s4Ku4Eiid5QC9WABlwDsYs"
# 1-2. Assistant 를 생성합니다.
from openai import OpenAI
# OpenAI API를 사용하기 위한 클라이언트 객체를 생성합니다.
client = OpenAI(api_key=api_key)
# Assistant 를 생성합니다.
assistant = client.beta.assistants.create(
name="Math Tutor", # 챗봇의 이름을 지정합니다.
# 챗봇의 역할을 설명합니다.
instructions="You are a personal math tutor. Answer questions briefly, in a sentence or less.",
model="gpt-4-turbo-preview", # 사용할 모델을 지정합니다.
)
# 생성된 챗봇의 정보를 JSON 형태로 출력합니다.
show_json(assistant)
ASSISTANT_ID = assistant.id
{'id': 'asst_CHAaVuTolIlBCPAmnJOvRkK5',
'created_at': 1707835540,
'description': None,
'file_ids': [],
'instructions': 'You are a personal math tutor. Answer questions briefly, in a sentence or less.',
'metadata': {},
'model': 'gpt-4-turbo-preview',
'name': 'Math Tutor',
'object': 'assistant',
'tools': []}
-
스레드(Thread) 생성하기
-
스레드를 이미 생성한 경우
-
스레드를 새롭게 생성하는 경우
-
# 2-1. 스레드를 이미 생성한 경우
THREAD_ID = "thread_6We5fHvb5NBuacPfZYkqUWlO"
# 2-2. 스레드를 새롭게 생성합니다.
def create_new_thread():
# 새로운 스레드를 생성합니다.
thread = client.beta.threads.create()
return thread
thread = create_new_thread()
# 새로운 스레드를 생성합니다.
show_json(thread)
# 새롭게 생성한 스레드 ID를 저장합니다.
THREAD_ID = thread.id
{'id': 'thread_rKx2vWlLAwtWxHqW1uuZas4g',
'created_at': 1707835638,
'metadata': {},
'object': 'thread'}
-
스레드에 메시지 생성
-
스레드에 새로운 메시지를 추가 합니다.
-
스레드를 실행(run) 합니다.
-
스레드의 상태를 확인합니다.(대기중, 작업중, 완료, etc)
-
스레드에서 최신 메시지를 조회한 뒤 결과를 확인합니다.
-
import time
# 반복문에서 대기하는 함수
def wait_on_run(run, thread_id):
while run.status == "queued" or run.status == "in_progress":
# 3-3. 실행 상태를 최신 정보로 업데이트합니다.
run = client.beta.threads.runs.retrieve(
thread_id=thread_id,
run_id=run.id,
)
time.sleep(0.5)
return run
def submit_message(assistant_id, thread_id, user_message):
# 3-1. 스레드에 종속된 메시지를 '추가' 합니다.
client.beta.threads.messages.create(
thread_id=thread_id, role="user", content=user_message
)
# 3-2. 스레드를 실행합니다.
run = client.beta.threads.runs.create(
thread_id=thread_id,
assistant_id=assistant_id,
)
return run
def get_response(thread_id):
# 3-4. 스레드에 종속된 메시지를 '조회' 합니다.
return client.beta.threads.messages.list(thread_id=thread_id, order="asc")
def print_message(response):
for res in response:
print(f"[{res.role.upper()}]\n{res.content[0].text.value}\n")
def ask(assistant_id, thread_id, user_message):
run = submit_message(
assistant_id,
thread_id,
user_message,
)
# 실행이 완료될 때까지 대기합니다.
run = wait_on_run(run, thread_id)
print_message(get_response(thread_id).data[-2:])
return run
# thread_id = "기존 스레드 ID를 입력해 주세요"
thread_id = create_new_thread().id # 새로운 스레드를 생성합니다.
run = ask(ASSISTANT_ID, thread_id,
"I need to solve `1 + 20`. Can you help me?")
[USER] I need to solve `1 + 20`. Can you help me? [ASSISTANT] Yes, `1 + 20` equals `21`.
# 전체 대화내용 출력
print_message(get_response(thread_id).data[:])
[USER] I need to solve `1 + 20`. Can you help me? [ASSISTANT] Yes, `1 + 20` equals `21`.
Assistant + tools(도구)
Assistants API의 핵심 기능 중 하나는 Code Interpreter, Retrieval, 그리고 사용자 정의 함수(OpenAI Functions)와 같은 도구로 우리가 만든 Assistants가 이러한 도구들을 활용할 수 있도록 설정할 수 있습니다.
아래의 튜토리얼은 각각의 도구가 가지는 역할과 설정하는 방법에 대해 자세히 알아보도록 하겠습니다.
도구1: Code Interpreter(코드 인터프리터)
개요
-
Code Interpreter를 사용하면 어시스턴트 API가 샌드박스가 적용된 실행 환경에서 Python 코드를 작성하고 실행할 수 있습니다.
-
이 도구는 다양한 데이터와 형식의 파일을 처리하고 데이터와 그래프 이미지가 포함된 파일을 생성할 수 있습니다.
-
코드 인터프리터를 사용하면 어시스턴트가 코드를 반복적으로 실행하여 까다로운 코드 및 수학 문제를 해결할 수 있습니다.
요금
-
코드 인터프리터는 세션당 $0.03의 요금이 부과됩니다. Assistant 가 두 개의 서로 다른 스레드(예: 최종 사용자당 하나의 스레드)에서 동시에 코드 인터프리터를 호출하는 경우 두 개의 코드 인터프리터 세션이 생성됩니다.
-
각 세션은 기본적으로 1시간 동안 활성화되므로 사용자가 동일한 스레드에서 코드 인터프리터와 최대 1시간 동안 상호 작용하는 경우 한 세션당 하나의 요금만 지불하면 됩니다.
우리의 Math Tutor에 Code Interpreter 도구를 장착해 보겠습니다.
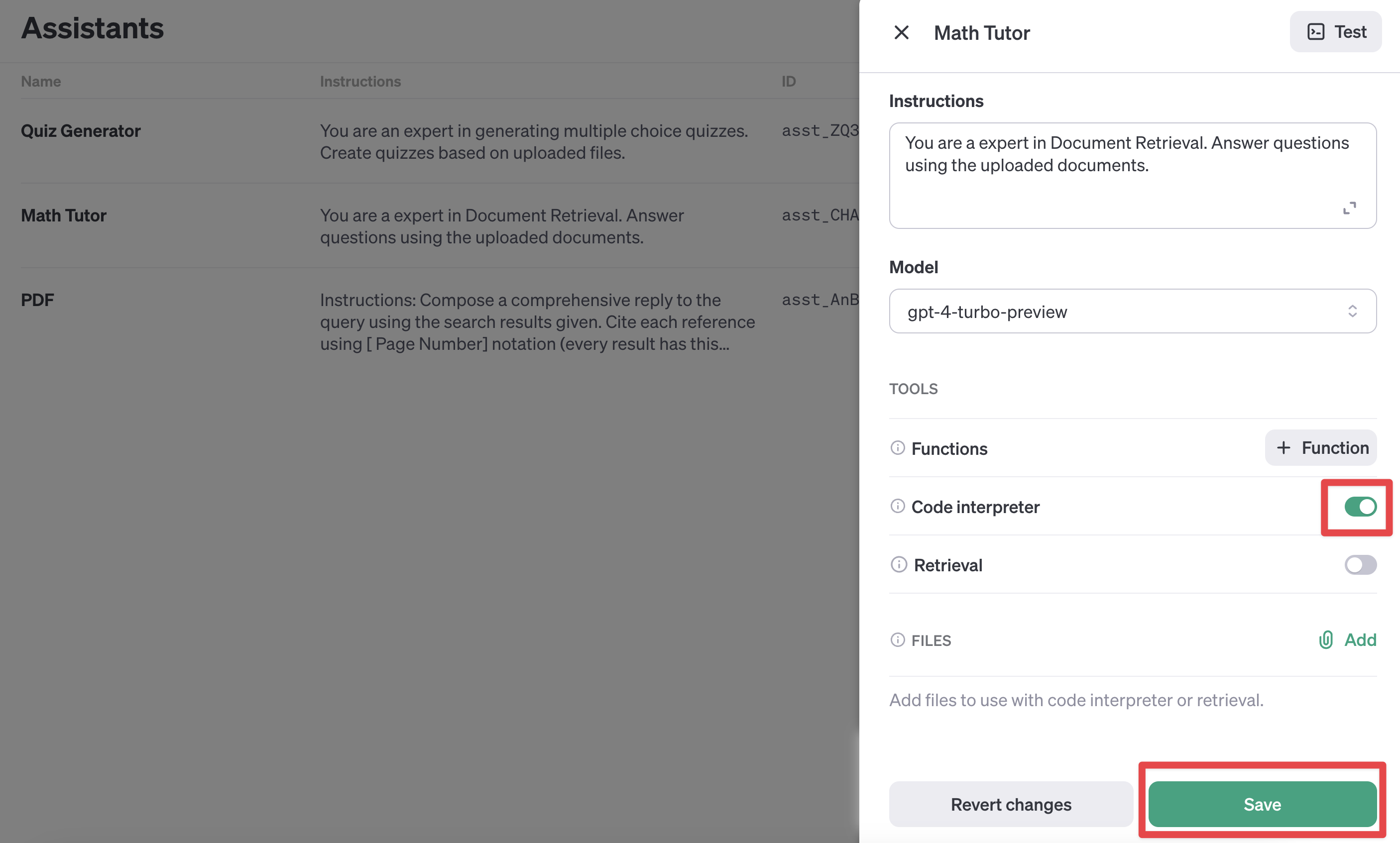
이는 대시보드에서 할 수 있기도 하고 또는 Assistant API 를 사용해서 추가할 수도 있습니다.
assistant = client.beta.assistants.update(
ASSISTANT_ID,
tools=[{"type": "code_interpreter"}], # code_interpreter 도구를 추가합니다.
)
show_json(assistant)
{'id': 'asst_CHAaVuTolIlBCPAmnJOvRkK5',
'created_at': 1707835540,
'description': None,
'file_ids': [],
'instructions': 'You are a personal math tutor. Answer questions briefly, in a sentence or less.',
'metadata': {},
'model': 'gpt-4-turbo-preview',
'name': 'Math Tutor',
'object': 'assistant',
'tools': [{'type': 'code_interpreter'}]}
이제, Assistant에게 새로운 도구를 사용하도록 요청해보겠습니다.
아래는 피보나치 수열의 첫 20개 숫자를 생성하는 요청입니다. 수열의 첫 20개 숫자를 생성하는 과정에서 code_interpreter 도구를 활용하여 코드를 생성한 뒤 실행합니다.
thread_id = create_new_thread().id # 새로운 스레드를 생성합니다.
run = ask(ASSISTANT_ID, thread_id,
"Generate the first 20 fibbonaci numbers with code.")
[USER] Generate the first 20 fibbonaci numbers with code. [ASSISTANT] The first 20 Fibonacci numbers are: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181.
겉으로 보기에는 일반 채팅과 다를바 없어 보입니다.
하지만, 자세한 내막을 들여다보면, Assistant 는 code_interpreter 를 사용하여 코드를 생성한 뒤, 실행한 결과를 토대로 우리에게 최종 응답을 주었습니다.
이러한 과정을 눈으로 확인해 보기 위해는 아래를 참고하면 됩니다.
실행단계(steps)
Run은 하나 이상의 Step으로 구성됩니다. Run과 마찬가지로, 각 Step은 조회할 수 있는 status를 가지고 있습니다. 이는 사용자에게 Step의 진행 상황을 표면화하는 데 유용합니다 (예: Assistant가 코드를 작성하거나 검색을 수행하는 동안 스피너 역할).
# 모든 단계목록을 조회합니다.
run_steps = client.beta.threads.runs.steps.list(
thread_id=thread_id, run_id=run.id, order="asc"
)
각 단계의 step_details를 살펴 보도록 하겠습니다.
다음은 단계별 세부 정보를 출력하는 코드입니다.
for step in run_steps.data:
# 각 단계의 세부 정보를 가져옵니다.
step_details = step.step_details
# 세부 정보를 JSON 형식으로 출력합니다.
show_json(step_details)
{'tool_calls': [{'id': 'call_HcY7D3hfiECMA9SY5X5i2CY9',
'code_interpreter': {'input': 'def fibonacci(n):\r\n a, b = 0, 1\r\n fib_sequence = []\r\n for _ in range(n):\r\n fib_sequence.append(a)\r\n a, b = b, a + b\r\n return fib_sequence\r\n\r\n# Generate the first 20 Fibonacci numbers\r\nfibonacci_20 = fibonacci(20)\r\nfibonacci_20',
'outputs': [{'logs': '[0,\n 1,\n 1,\n 2,\n 3,\n 5,\n 8,\n 13,\n 21,\n 34,\n 55,\n 89,\n 144,\n 233,\n 377,\n 610,\n 987,\n 1597,\n 2584,\n 4181]',
'type': 'logs'}]},
'type': 'code_interpreter'}],
'type': 'tool_calls'}
{'message_creation': {'message_id': 'msg_eywQomLGzvxdzbvxG2dRgaq6'},
'type': 'message_creation'}
두 단계의 step_details를 볼 수 있습니다:
-
tool_calls(단수가 아닌 복수형이며, 하나의 단계에서 하나 이상이 될 수 있습니다) -
message_creation
첫 번째 단계
tool_calls이며, 특히 code_interpreter를 사용하고, 다음의 내용을 포함합니다.
-
input: 도구가 호출되기 전에 생성된 Python 코드였으며, -
output: Code Interpreter를 실행한 결과였습니다.
두 번째 단계
message_creation이며, 사용자에게 결과를 전달하기 위해 스레드에 추가된 message를 포함합니다.
도구2: Retrieval(검색)
Assistants API에서 또 다른 강력한 도구는 검색입니다.
주요 기능
-
질문에 답변할 때 Assistant가 제공된 문서나 지식 기반으로 답변할 수 있게하는 기능입니다.
-
검색은 독점적인 제품 정보나 사용자가 제공한 문서 등 모델 외부의 지식으로 Assistant 의 답변을 보강합니다.
-
파일을 업로드하여 어시스턴트에 전달하면 OpenAI가 자동으로 문서를 청크 처리(분할)하고, 임베딩을 색인화 및 저장하며, 벡터 검색을 구현하여 관련 콘텐츠를 검색하여 사용자 쿼리에 답변합니다.
이 기능 역시 대시보드에서 업데이트할 수 있거나 API에서도 활성화할 수 있으며, 방법은 아래에서 다룹니다.
파일 업로드
실습을 위해 활용한 파일을 미리 준비합니다.
참고
-
지원되는 파일 목록은 지원파일 목록 에서 확인할 수 있습니다(대부분의 문서 형식은 지원합니다).
-
단, 최대 파일 크기는 512MB, 토큰 수는 2,000,000개 이하입니다(파일 첨부 시 자동으로 계산됨).
준비된 파일을 대시보드에서 업로드할 수 있고, 또는 API 로 업로드도 가능합니다.
검색에 활용하고자 하는 파일을 직접 Assistant Files 링크에서 업로드하거나, 이전과 마찬가지로 API로 파일을 업로드하여 FILE ID 를 얻을 수 있습니다.
우측 Upload 버튼을 클릭한 후 파일을 업로드 할 수 있습니다.
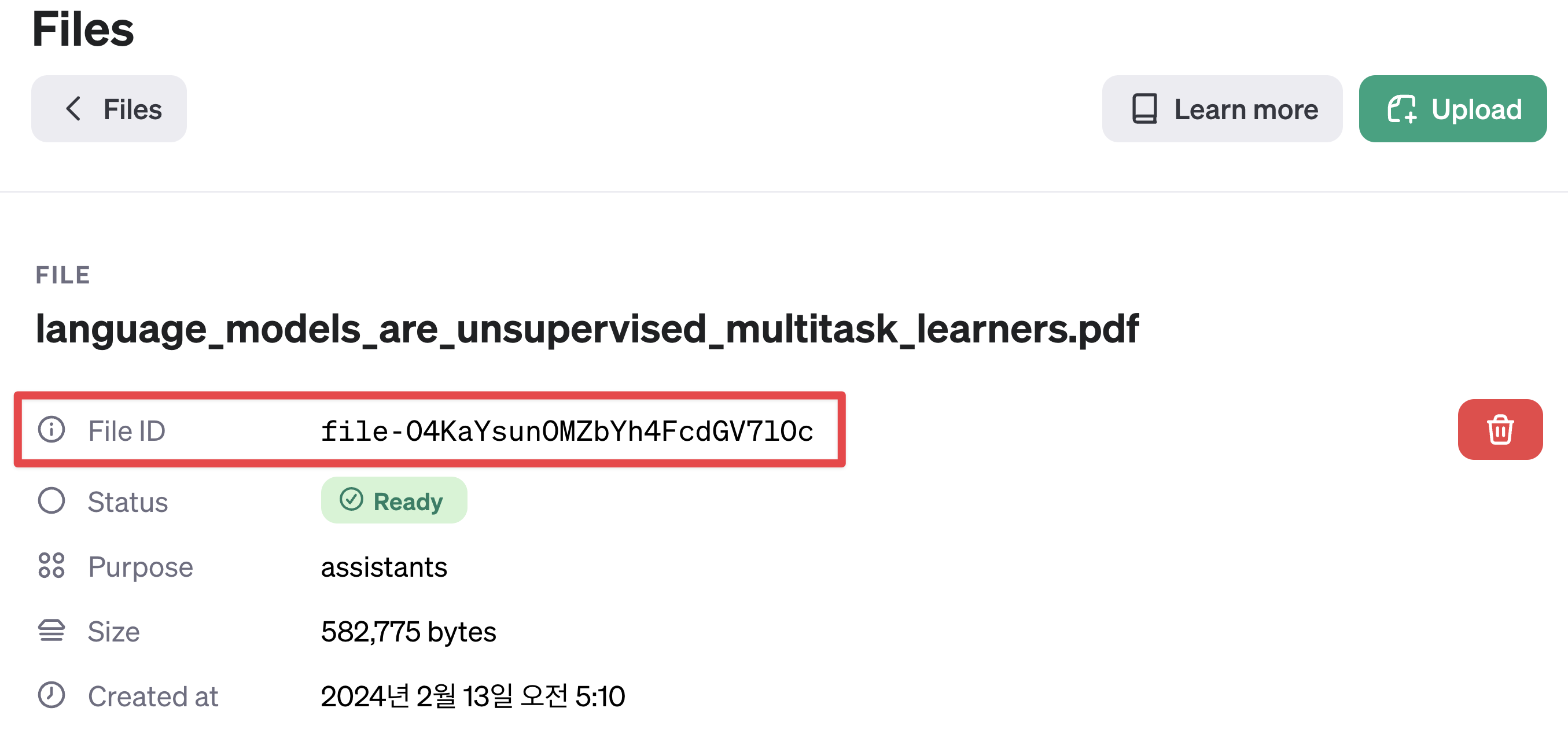
업로드한 File ID 를 조회합니다.
# 파일 ID를 불러옵니다
file_ids = [
"file-ywTSPKuBSAZD9HliWEBo1LHc", # ML 논문
"file-pXvkeNqOoMakeFYE9czPcHTL", # 2023년 경제 전망 보고서
]
다음은 API 로 파일을 업로드 하는 코드입니다.
# 파일 업로드를 위한 함수를 정의합니다.
def upload_files(files):
uploaded_files = []
for filepath in files:
file = client.files.create(
file=open(
# 업로드할 파일의 경로를 지정합니다.
filepath, # 파일경로. (예시) data/sample.pdf
"rb",
),
purpose="assistants",
)
uploaded_files.append(file)
print(f"[업로드한 파일 ID]\n{file.id}")
return uploaded_files
# 업로드할 파일들의 경로를 지정합니다.
files_to_upload = [
"data/language_models_are_unsupervised_multitask_learners.pdf",
"data/SPRI_AI_Brief_2023년12월호.pdf",
]
# 파일을 업로드합니다.
file_ids = upload_files(files_to_upload)
[업로드한 파일 ID] file-ywTSPKuBSAZD9HliWEBo1LHc [업로드한 파일 ID] file-pXvkeNqOoMakeFYE9czPcHTL
업로드한 FILE ID 를 잘 기록해 두세요. 이 FILE ID 를 사용하여 Assistant 에게 파일을 제공할 수 있습니다.
Assistant 설정 업데이트(도구 추가)
아래는 Assistant 대시보드에서 Retrieval 기능을 추가하는 방법입니다.
-
Assistant 대시보드에 접속합니다.
-
나열된 Assistant 중 변경하고자 하는 Assistant 를 클릭하여 설정을 엽니다.
-
TOOLS 밑에 있는
Retrieval토글 버튼을 클릭하여 활성화하면 설정이 완료됩니다. -
언제든 도구는 활성화/비활성화 할 수 있습니다.
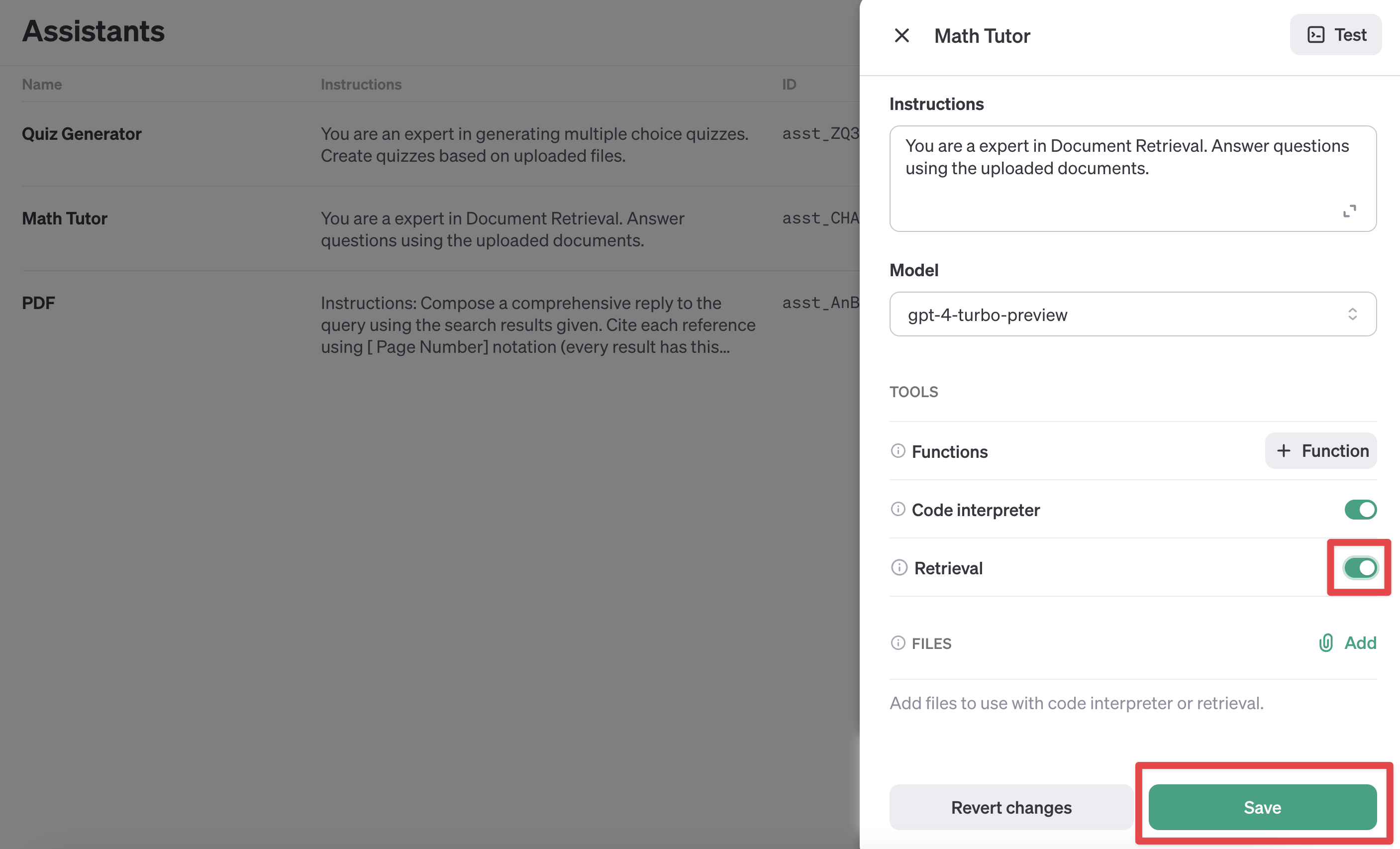
다음은 코드로 Retrieval 도구를 추가하는 코드입니다.
(이전에 대시보드에서 이미 활성화 했다면, 본 단계는 건너 뛰어도 좋습니다!)
아래의 코드를 실행하여 업로드한 파일의 목록을 확인할 수 있습니다.
# 업로드한 모든 파일 ID 와 파일명을 출력합니다.
for file in client.files.list():
print(f"[파일 ID] {file.id} [파일명] {file.filename}")
[파일 ID] file-pXvkeNqOoMakeFYE9czPcHTL [파일명] SPRI_AI_Brief_2023년12월호.pdf [파일 ID] file-ywTSPKuBSAZD9HliWEBo1LHc [파일명] language_models_are_unsupervised_multitask_learners.pdf [파일 ID] file-kLr0kzRn5csryaMgeKmzYc7t [파일명] step_metrics.csv [파일 ID] file-N7dVCOHLcw5BiGCTX8tsYgof [파일명] faq_data.jsonl [파일 ID] file-f23erd9JTeBCtiq9MvqDeURV [파일명] 20231020bitumen.pdf [파일 ID] file-LCkqG3WPBCBwfy14jNPlvckm [파일명] 황순원-소나기.pdf [파일 ID] file-JPNbRJacb6StlOpHNZNJANic [파일명] 2023년_8월_경제전망보고서.pdf [파일 ID] file-6vZ6tOG3YOxdKBXbnrPOFQYI [파일명] pdfapi.py
# Assistant 의 설정을 업데이트합니다.
assistant = client.beta.assistants.update(
ASSISTANT_ID,
# retrieval 도구를 추가합니다.
tools=[
{"type": "code_interpreter"},
{"type": "retrieval"},
],
file_ids=file_ids, # 업로드한 파일 ID를 지정합니다.
# Assistant 의 역할을 설명합니다.
instructions="You are a expert in Document Retrieval. Answer questions using the uploaded documents.",
)
# 업데이트된 Assistant 정보를 출력합니다.
show_json(assistant)
{'id': 'asst_CHAaVuTolIlBCPAmnJOvRkK5',
'created_at': 1707835540,
'description': None,
'file_ids': ['file-ywTSPKuBSAZD9HliWEBo1LHc',
'file-pXvkeNqOoMakeFYE9czPcHTL'],
'instructions': 'You are a expert in Document Retrieval. Answer questions using the uploaded documents.',
'metadata': {},
'model': 'gpt-4-turbo-preview',
'name': 'Math Tutor',
'object': 'assistant',
'tools': [{'type': 'code_interpreter'}, {'type': 'retrieval'}]}
기존의 Assistant 에 검색 도구(Retrieval Tools) 를 추가 하고, 업로드한 파일을 연결 까지 완료했다면, 이제 Assistant 를 사용하여 검색을 수행할 수 있습니다.
수행하는 방식은 기존과 동일합니다.
질문의 내용을 이해하고, Assistant 에게 질문을 제출하면 됩니다.
다만, “파일로부터 검색해줘” 라는 명령어를 사용하여 Assistant 에게 파일로부터 검색을 수행하도록 지시 해야 합니다.
ASSISTANT_ID = assistant.id # 업데이트된 Assistant ID를 지정합니다.
thread_id = create_new_thread().id # 새로운 스레드를 생성합니다.
# 질문을 던집니다.
run = ask(
ASSISTANT_ID,
thread_id,
"빌게이츠의 AI 에이전트에 대한 견해를 SPRI_AI_Brief_2023년12월호 파일에서 검색하여 알려주세요. "
"200~300 단어로 자세히 설명해 주세요.",
)
[USER] 빌게이츠의 AI 에이전트에 대한 견해를 SPRI_AI_Brief_2023년12월호 파일에서 검색하여 알려줘. 200~300단어로 자세히 설명해줘. [ASSISTANT] 빌 게이츠는 AI 에이전트가 컴퓨터 사용방식과 소프트웨어 산업에 막대한 변화를 가져올 것으로 보고 있습니다. 그는 AI 에이전트가 일상언어로 모든 작업을 처리할 수 있게 되며, 이로 인해 컴퓨터를 사용하는 방식이 혁명적으로 변화할 것으로 예상합니다. 특정 작업에 대해 다양한 앱을 사용해야 하는 현재의 방식에서 벗어나, 일상언어로 기기에 말하기만 하면 되는 미래가 도래할 것이라고 합니다. 이 AI 에이전트의 보급은 컴퓨터 분야뿐만 아니라, 의료, 교육, 생산성, 엔터테인먼트 및 쇼핑 등 다양한 산업 영역에 영향을 미칠 것으로 예상됩니다. 예를 들어, 여행 계획 수립 시 AI 챗봇이 예산에 맞는 호텔을 제안하는 것에서 한 단계 더 나아가, AI 에이전트는 사용자의 이전 여행 패턴을 분석해 여행지를 제안하고, 선호하는 레스토랑 예약까지 가능할 것입니다. 게이츠는 AI 에이전트가 의료 분야에서 환자 분류, 건강 문제에 대한 조언 제공, 교육 분야에서 개인화된 교육 경험 제공, 생산성 증대와 엔터테인먼트 및 쇼핑 분야에서 사용자의 관심사에 맞는 맞춤형 정보 제공 등에 있어 획기적인 변화를 가져올 것으로 전망합니다. 결론적으로, 빌 게이츠는 AI 에이전트가 고비용의 서비스를 대중화하고, 사용자에게 맞춤화된 대응을 가능하게 하는 등 다양한 분야에서 사용자 경험을 대폭 개선할 것으로 기대합니다【11†source】.
아래는 이전에 도출한 답변을 얻기까지 Assistant 가 수행한 단계를 출력한 결과입니다.
단계
-
tool_calls: 먼저,retrieval도구를 사용하여 파일에서 정보를 검색합니다. -
message_createion: 그런다음, 검색된 정보를 사용하여 답변을 생성합니다.
run_steps = client.beta.threads.runs.steps.list(
thread_id=thread_id, run_id=run.id, order="asc"
)
for step in run_steps.data:
# 각 단계의 세부 정보를 가져옵니다.
step_details = step.step_details
# 세부 정보를 JSON 형식으로 출력합니다.
show_json(step_details)
{'tool_calls': [{'id': 'call_izCUdQH9TyMxT6VqAeXfPUu0',
'retrieval': {},
'type': 'retrieval'}],
'type': 'tool_calls'}
{'message_creation': {'message_id': 'msg_wbdKc3hWYnCPoxu5zASdA1UG'},
'type': 'message_creation'}
run = ask(
ASSISTANT_ID,
THREAD_ID,
"Language Models are Unsupervised Multitask Learners 논문에서 가장 크게 기여한 연구 성과는 무엇인가요? "
"200~300 단어로 자세히 한글로 설명해 주세요. 단, 기술적인 용어는 번역하지 마세요.",
)
[USER] Language Models are Unsupervised Multitask Learners 논문에서 가장 크게 기여한 연구 성과는 무엇인가요? 200~300단어로 자세히 한글로 설명해 주세요. 단, 기술적인 용어는 번역하지 마세요. [ASSISTANT] "Language Models are Unsupervised Multitask Learners" 논문은 자연어 처리(NLP) 및 인공지능(AI) 분야에 중대한 기여를 하였습니다. 이 연구의 핵심 기여는 언어 모델이 파라미터나 구조의 변경 없이 다양한 다운스트림 작업을 zero-shot 상황에서 효과적으로 수행할 수 있음을 보여준 것입니다. 이는 특정 작업을 위해 설계된 모델에 도전하는 것으로, 보다 일반적이고 다재다능한 모델을 향한 패러다임 전환을 시사합니다. 이러한 모델은 다양한 작업에 자연스럽게 적응할 수 있는 능력을 가지고 있습니다. 연구자들은 언어 모델이 대량의 텍스트 데이터에서 얻은 문맥적 이해를 활용하여 명시적으로 학습하지 않은 작업을 처리할 수 있음을 보여주었습니다. 이 접근법은 언어 모델이 일관성 있고 문맥에 맞는 텍스트를 생성하는 도구로서뿐만 아니라 다양한 도메인에서 추론, 결정, 학습을 할 수 있는 다기능 에이전트로서의 잠재력을 강조합니다. 이러한 발견은 AI가 전이 학습과 비지도 학습으로 향하는 더 넓은 추세와 일치합니다. 한 작업에서 다른 작업으로 일반화하는 능력과 레이블이 지정되지 않은 데이터로부터 학습하는 능력은 더 지능적이고 유연한 시스템을 구축하는 것에 있어 핵심으로 여겨집니다. 연구에서 언어 모델이 zero-shot 설정에서 다양한 작업에서 경쟁력있고, 일부 경우에는 최신 기술 수준의 결과를 달성할 수 있음을 보여줌으로써, 언어 이해와 작업 수행이 비지도 다작업 학습 전략으로부터 크게 혜택을 받을 수 있음을 입증합니다. 이는 인간 활동의 광범위한 스펙트럼에서 적응력 있고 지능적인 AI 시스템을 개발하는 새로운 방향을 여는 것입니다.
끝으로, 검색에는 Annotations와 같은 더 많은 복잡한 부분이 있으며, 이는 다른 쿡북에서 다룰 수 있습니다.
도구3: Functions(함수)
가장 마지막으로 살펴본 도구는 Functions(함수) 입니다.
개요
-
가장 강력한 도구로서, Assistant에게 사용자 정의 함수를 지정할 수 있습니다. 이는 Chat Completions API에서의 함수 호출과 매우 유사합니다.
-
Function calling(함수 호출) 도구를 사용하면 Assistant 에게 사용자 정의 함수 를 설명하여 호출해야 하는 함수를 인자와 함께 지능적으로 반환하도록 할 수 있습니다.
-
Assistant API는 실행 중에 함수를 호출할 때 실행을 일시 중지하며, 함수 호출 결과를 다시 제공하여 Run 실행을 계속할 수 있습니다. (이는 사용자 피드백을 받아 재게할 수 있는 의미이기도 합니다. 아래 튜토리얼에서 상세히 다룹니다).
이번에 진행할 예제는 퀴즈문제 출제 챗봇입니다.
우리의 수학 튜터를 위한 display_quiz() 함수를 생성하였습니다(사실 이 함수는 퀴즈 문제에 대한 사용자 입력을 받는 함수라 역할이 중요하지는 않습니다).
이 함수는 title과 question의 배열을 받아 퀴즈를 표시하고 사용자로부터 각각에 대한 입력을 받습니다.
-
title -
questions-
question_text -
choices: [“선택지 1”, “선택지 2”, “선택지 3”, “선택지 4”]
-
def display_quiz(title, questions, show_numeric=False):
print(f"제목: {title}\n")
responses = []
for q in questions:
# 질문을 출력합니다.
print(q["question_text"])
response = ""
# 각 선택지를 출력합니다.
for i, choice in enumerate(q["choices"]):
if show_numeric:
print(f"{i+1} {choice}")
else:
print(f"{choice}")
response = input("정답을 선택해 주세요: ")
responses.append(response)
print()
return responses
다음은 샘플 퀴즈의 출력 예시입니다.
responses = display_quiz(
"Sample Quiz",
[
{
"question_text": "제일 좋아하는 색상은 무엇입니까?",
"choices": ["빨강", "파랑", "초록", "노랑"],
},
{
"question_text": "제일 좋아하는 동물은 무엇입니까?",
"choices": ["강아지", "고양이", "햄스터", "토끼"],
},
],
show_numeric=True,
)
print("Responses:", responses)
제목: Sample Quiz 제일 좋아하는 색상은 무엇입니까? 1 빨강 2 파랑 3 초록 4 노랑 제일 좋아하는 동물은 무엇입니까? 1 강아지 2 고양이 3 햄스터 4 토끼 Responses: ['1', '2']
이제, 이 함수의 인터페이스를 JSON 형식으로 정의해 보겠습니다.
아래는 Assistant 가 호출할 수 있는 Functions 로 정의하기 위하 우리가 정의해야하는 schema 의 예시입니다.
다음과 같이 schema 에 따라 정의해야 Functions 를 Assistant 가 올바르게 활용할 수 있습니다.
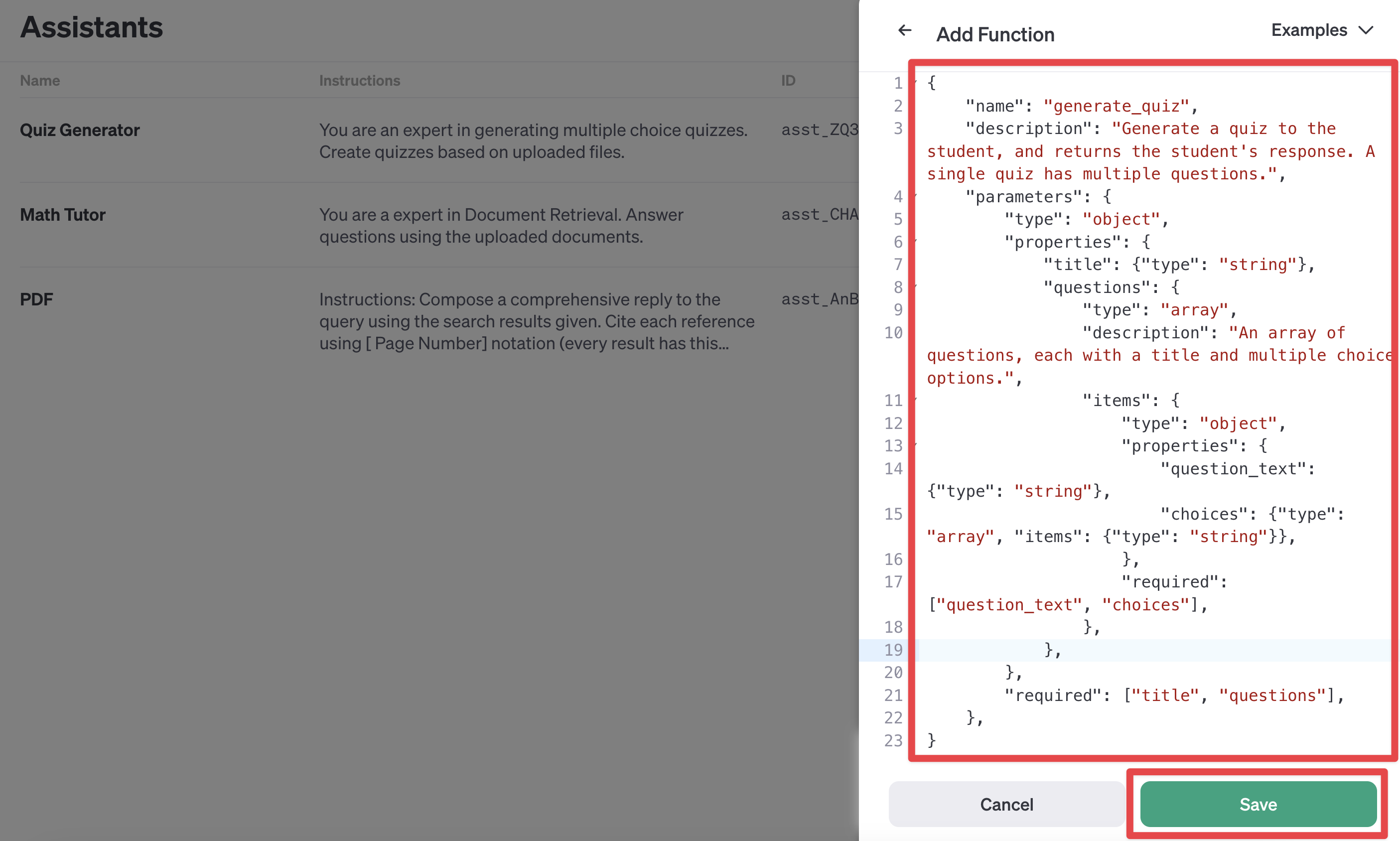
function_schema = {
"name": "generate_quiz",
"description": "Generate a quiz to the student, and returns the student's response. A single quiz has multiple questions.",
"parameters": {
"type": "object",
"properties": {
"title": {"type": "string"},
"questions": {
"type": "array",
"description": "An array of questions, each with a title and multiple choice options.",
"items": {
"type": "object",
"properties": {
"question_text": {"type": "string"},
"choices": {"type": "array", "items": {"type": "string"}},
},
"required": ["question_text", "choices"],
},
},
},
"required": ["title", "questions"],
},
}
다시 한번, 대시보드나 API를 통해 우리의 Assistant를 업데이트합시다.
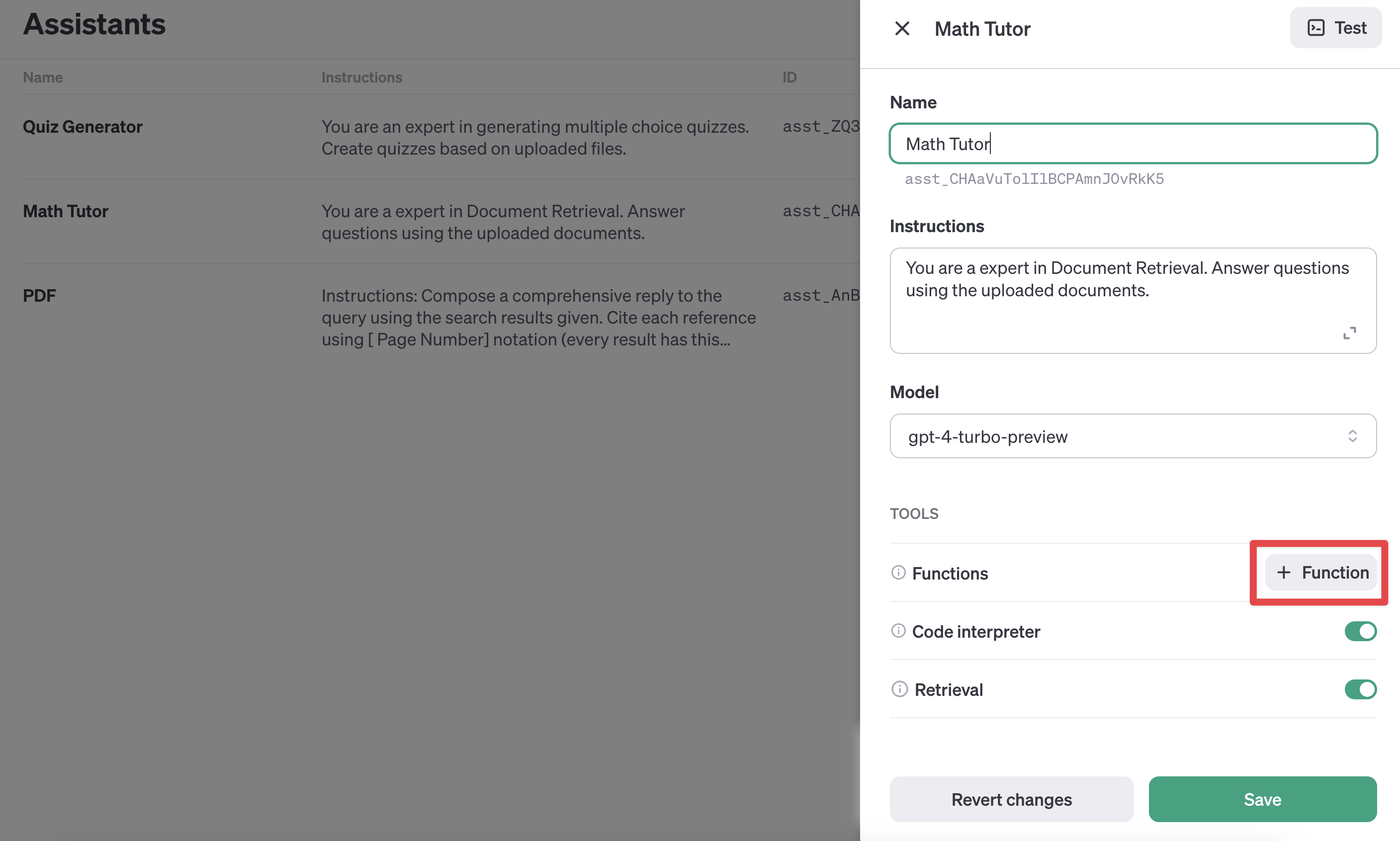
참고
-
대시보드에 함수 JSON을 붙여넣는 것이 들여쓰기 등으로 인해 조금 까다로웠습니다.
-
저는 ChatGPT에게 대시보드의 예시 중 하나와 동일하게 내 함수를 포맷하도록 요청했습니다!
새로운 Assistant 를 생성하고, retrieval 그리고 function 도구를 추가합니다.
-
retrieval도구는 문서에서 내용을 검색할 때 활용합니다. -
function도구는 사용자 정의 함수를 사용할 때 활용합니다.
# 퀴즈를 출제하는 역할을 하는 챗봇을 생성합니다.
assistant = client.beta.assistants.create(
name="Quiz Generator",
instructions="You are an expert in generating multiple choice quizzes. Create quizzes based on uploaded files.",
model="gpt-4-turbo-preview",
tools=[
{"type": "retrieval"},
{"type": "function", "function": function_schema},
],
file_ids=file_ids,
)
ASSISTANT_ID = assistant.id
# 생성된 챗봇의 정보를 JSON 형태로 출력합니다.
show_json(assistant)
{'id': 'asst_xYv3UyJDkYnpL1wI3gOMzSn6',
'created_at': 1707844939,
'description': None,
'file_ids': ['file-ywTSPKuBSAZD9HliWEBo1LHc',
'file-pXvkeNqOoMakeFYE9czPcHTL'],
'instructions': 'You are an expert in generating multiple choice quizzes. Create quizzes based on uploaded files.',
'metadata': {},
'model': 'gpt-4-turbo-preview',
'name': 'Quiz Generator',
'object': 'assistant',
'tools': [{'type': 'retrieval'},
{'function': {'name': 'generate_quiz',
'description': "Generate a quiz to the student, and returns the student's response. A single quiz has multiple questions.",
'parameters': {'type': 'object',
'properties': {'title': {'type': 'string'},
'questions': {'type': 'array',
'description': 'An array of questions, each with a title and multiple choice options.',
'items': {'type': 'object',
'properties': {'question_text': {'type': 'string'},
'choices': {'type': 'array', 'items': {'type': 'string'}}},
'required': ['question_text', 'choices']}}},
'required': ['title', 'questions']}},
'type': 'function'}]}
이제, 퀴즈 생성을 요청할 차례입니다!! (요청에 시간이 1분 이상 소요될 수 있습니다)
# 새로운 스레드를 생성한 뒤 진행합니다.
thread_id = create_new_thread().id
# 퀴즈를 만들도록 요청합니다.
run = ask(
ASSISTANT_ID,
thread_id,
# 객관식 퀴즈에 대한 구체적인 지시사항을 기입합니다.
"3개의 객관식 퀴즈(multiple choice questions)를 만들어 주세요. "
"객관식 퀴즈의 선택지에 번호를 표기해주세요. 1~4까지 숫자로 시작하여야 합니다. "
"퀴즈는 내가 업로드한 파일에 관한 내용이어야 합니다. "
"내가 제출한 responses에 대한 피드백을 주세요. "
"내가 기입한 답, 정답, 제출한 답이 오답이라면 오답에 대한 피드백을 모두 포함해야 합니다. "
"모든 내용은 한글로 작성해 주세요. ",
)
[USER] 3개의 객관식 퀴즈(multiple choice questions)를 만들어 주세요. 객관식 퀴즈의 선택지에 번호를 표기해주세요. 1~4까지 숫자로 시작하여야 합니다. 퀴즈는 내가 업로드한 파일에 관한 내용이어야 합니다. 내가 제출한 responses에 대한 피드백을 주세요. 내가 기입한 답, 정답, 제출한 답이 오답이라면 오답에 대한 피드백을 모두 포함해야 합니다. 모든 내용은 한글로 작성해 주세요.
# requires_action 이 출력되는 것을 확인합니다.
print(run.status)
requires_action
이제, Run의 status를 확인할 때 requires_action이라고 출력되는 것을 확인합니다.
required_action
required_action 필드는 도구가 우리가 실행하고 그 출력을 어시스턴트에게 다시 제출하기를 기다리고 있음을 나타냅니다.
required_action 는 여러 가지 상황에서 출력될 수 있습니다.
(예시1) 함수의 argument 가 필요할 때 입니다.
예를 들어, def get_weather(location) 함수를 정의했다면, get_weather 함수가 호출될 때 location 이 필요합니다.
이렇게 location 이 꼭 필요한 argument 인데, 누락되었다면, requires_action 이 status 로 반환되고, 우리가 argument 인 location 에 ‘서울’ 과 같은 형식으로 지정해야 합니다.
(예시2) 이번 예시의 퀴즈 생성기가 또 다른 좋은 예시 입니다.
퀴즈 생성기가 퀴즈 문제를 만들고 난 다음에 사용자의 정답 제출을 기다리고 있습니다. 이때도 required_action 이 호출될 수 있습니다.
비록, 함수의 argument 입력은 필요 없지만 프롬프트(prompt) 에서 제출한 정답에 대한 피드백 을 요청했기 때문에 required_action 이 호출된 것입니다.
그럼, 실행한 Run 의 required_action 을 출력하여 세부 정보를 확인해 보겠습니다.
# tool_calls를 출력합니다.
tool_call = run.required_action.submit_tool_outputs.tool_calls[0]
name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
# tool_calls 정보를 출력합니다.
print(f"[Function]\n{name}\n")
print(f"[Arguments]")
arguments
[Function] generate_quiz [Arguments]
{'title': 'AI와 머신러닝 관련 퀴즈',
'questions': [{'question_text': '자연어 처리에서 전통적으로 어떤 방식으로 접근해왔나요?',
'choices': ['1. 무작위 선택을 통한 학습',
'2. 지도학습을 통한 특정 데이터셋 학습',
'3. 사용자 가이드에 따른 직접적인 명령',
'4. 일반적인 AI 모델의 자체 학습']},
{'question_text': '음성인식, 문장 생성과 같은 언어 모델링 작업에서 GPT-2 모델은 어떤 접근 방식을 사용했나요?',
'choices': ['1. 고정된 사전 포함으로 제한된 언어 모델링',
'2. 바이트 수준에서 동작, 손실있는 전처리 불필요',
'3. 최소한의 토큰화만 사용, 대부분의 데이터 원문 유지',
'4. 전통적인 텍스트 처리를 통한 모든 언어 학습']},
{'question_text': '삼성전자가 공개한 자체 개발 생성 AI의 이름은 무엇인가요?',
'choices': ['1. 삼성 뉴럴', '2. 삼성 브레인', '3. 삼성 가우스', '4. 삼성 인텔리']}]}
이제 Assistant가 제공한 Function arguments 정보로 display_quiz 함수를 실행하여 정답을 기입해 봅시다.
responses = display_quiz(arguments["title"], arguments["questions"])
print("기입한 답(순서대로)")
print(responses)
제목: AI와 머신러닝 관련 퀴즈 자연어 처리에서 전통적으로 어떤 방식으로 접근해왔나요? 1. 무작위 선택을 통한 학습 2. 지도학습을 통한 특정 데이터셋 학습 3. 사용자 가이드에 따른 직접적인 명령 4. 일반적인 AI 모델의 자체 학습 음성인식, 문장 생성과 같은 언어 모델링 작업에서 GPT-2 모델은 어떤 접근 방식을 사용했나요? 1. 고정된 사전 포함으로 제한된 언어 모델링 2. 바이트 수준에서 동작, 손실있는 전처리 불필요 3. 최소한의 토큰화만 사용, 대부분의 데이터 원문 유지 4. 전통적인 텍스트 처리를 통한 모든 언어 학습 삼성전자가 공개한 자체 개발 생성 AI의 이름은 무엇인가요? 1. 삼성 뉴럴 2. 삼성 브레인 3. 삼성 가우스 4. 삼성 인텔리 기입한 답(순서대로) ['2', '3', '3']
자 그럼 Run 을 새롭게 생성하여 정답을 제출해 볼 차례입니다.
client.beta.threads.runs.submit_tool_outputs 함수는 우리의 입력을 다시 제출할 수 있도록 해줍니다.
참고
-
tool_call_id: 대기중인tool_call의id를 입력합니다. -
output: 사용자가 입력할 내용을json.dumps로 json 형식으로 변환하여 제출합니다.
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread_id,
run_id=run.id,
tool_outputs=[
{
"tool_call_id": tool_call.id,
"output": json.dumps(responses),
}
],
)
show_json(run)
{'id': 'run_zZrJL12DCVL8TYaHtvLG3LZk',
'assistant_id': 'asst_xYv3UyJDkYnpL1wI3gOMzSn6',
'cancelled_at': None,
'completed_at': None,
'created_at': 1707846505,
'expires_at': 1707847105,
'failed_at': None,
'file_ids': ['file-ywTSPKuBSAZD9HliWEBo1LHc',
'file-pXvkeNqOoMakeFYE9czPcHTL'],
'instructions': 'You are an expert in generating multiple choice quizzes. Create quizzes based on uploaded files.',
'last_error': None,
'metadata': {},
'model': 'gpt-4-turbo-preview',
'object': 'thread.run',
'required_action': None,
'started_at': 1707846505,
'status': 'queued',
'thread_id': 'thread_N0C9cTv9FBtUcmQfo2jbNgFg',
'tools': [{'type': 'retrieval'},
{'function': {'name': 'generate_quiz',
'description': "Generate a quiz to the student, and returns the student's response. A single quiz has multiple questions.",
'parameters': {'type': 'object',
'properties': {'title': {'type': 'string'},
'questions': {'type': 'array',
'description': 'An array of questions, each with a title and multiple choice options.',
'items': {'type': 'object',
'properties': {'question_text': {'type': 'string'},
'choices': {'type': 'array', 'items': {'type': 'string'}}},
'required': ['question_text', 'choices']}}},
'required': ['title', 'questions']}},
'type': 'function'}],
'usage': None}
아직 Run 만 생성했기 때문에 실제로 제출이 된 것은 아닙니다. 아래의 코드를 실행하여 제출하고 피드백을 받아보도록 합시다.
# 스레드에서 실행을 기다립니다.
run = wait_on_run(run, thread_id)
# 실행이 완료되면, 실행의 상태를 출력합니다.
if run.status == "completed":
print("퀴즈를 제출했습니다.")
# 전체 대화내용 출력
print_message(get_response(thread_id).data[-2:])
퀴즈를 제출했습니다. [USER] 3개의 객관식 퀴즈(multiple choice questions)를 만들어 주세요. 객관식 퀴즈의 선택지에 번호를 표기해주세요. 1~4까지 숫자로 시작하여야 합니다. 퀴즈는 내가 업로드한 파일에 관한 내용이어야 합니다. 내가 제출한 responses에 대한 피드백을 주세요. 내가 기입한 답, 정답, 제출한 답이 오답이라면 오답에 대한 피드백을 모두 포함해야 합니다. 모든 내용은 한글로 작성해 주세요. [ASSISTANT] 제출한 퀴즈의 결과는 다음과 같습니다: 1. 질문: 자연어 처리에서 전통적으로 어떤 방식으로 접근해왔나요? - 제출한 답: 2. 지도학습을 통한 특정 데이터셋 학습 - 정답: 2. 지도학습을 통한 특정 데이터셋 학습 - 피드백: 정확합니다! 전통적으로 자연어 처리 태스크는 대체로 지도학습과 특정 데이터셋에 대한 학습을 이용해 접근했습니다【8†source】. 2. 질문: 음성인식, 문장 생성과 같은 언어 모델링 작업에서 GPT-2 모델은 어떤 접근 방식을 사용했나요? - 제출한 답: 3. 최소한의 토큰화만 사용, 대부분의 데이터 원문 유지 - 정답: 2. 바이트 수준에서 동작, 손실있는 전처리 불필요 - 피드백: 제출한 답은 틀렸습니다. GPT-2 모델은 바이트 수준에서 동작하며, 데이터를 처리할 때 손실이 있는 전처리나 토큰화 과정을 필요로 하지 않습니다. 이 접근 방식 덕분에 언어 모델링 및 다양한 언어 태스크에서 높은 성능을 보였습니다【11†source】. 3. 질문: 삼성전자가 공개한 자체 개발 생성 AI의 이름은 무엇인가요? - 제출한 답: 3. 삼성 가우스 - 정답: 3. 삼성 가우스 - 피드백: 정확합니다! 삼성전자는 자체 개발한 생성 AI 기술인 '삼성 가우스'를 공개했습니다【15†source】. 전반적으로 1번과 3번 질문은 정확히 답해주셨으나, 2번 질문에서는 오답이었습니다. GPT-2 모델의 독특한 접근 방식과 작동 원리에 대해 더 깊이 이해할 수 있는 기회가 됐기를 바랍니다.
퀴즈 생성기 전체코드
1) 환경설정
.env 파일로부터 API KEY를 불러옵니다
# API KEY 정보를 불러옵니다
from dotenv import load_dotenv
load_dotenv()
True
import os
# os.environ["OPENAI_API_KEY"] = "API KEY를 입력해 주세요"
# OPENAI_API_KEY 를 설정합니다.
api_key = os.environ.get("OPENAI_API_KEY")
OpenAI 객체를 생성합니다.
# OpenAI API를 사용하기 위한 클라이언트 객체를 생성합니다.
client = OpenAI(api_key=api_key)
2) 파일 업로드
출제될 문제가 기반할 파일을 업로드합니다.
-
신규 파일 업로드
-
기존 업로드된 File ID 사용
신규 파일 업로드를 위한 코드입니다. 이미 업로드한 경우 건너 뛰어도 됩니다.
# 파일 업로드를 위한 함수를 정의합니다.
def upload_files(files):
uploaded_files = []
for filepath in files:
file = client.files.create(
file=open(
# 업로드할 파일의 경로를 지정합니다.
filepath, # 파일경로. (예시) data/sample.pdf
"rb",
),
purpose="assistants",
)
uploaded_files.append(file)
print(f"[업로드한 파일 ID]\n{file.id}")
return uploaded_files
# 필요에 따라서는 파일을 업로드 합니다.
# 파일 업로드시 아래 주석을 해제하고 업로드할 파일의 경로를 지정합니다.
# 업로드할 파일들의 경로를 지정합니다.
# files_to_upload = [
# "data/language_models_are_unsupervised_multitask_learners.pdf",
# "data/SPRI_AI_Brief_2023년12월호.pdf",
# ]
# 파일을 업로드합니다.
# file_ids = upload_files(files_to_upload)
이미 파일을 업로드 하였다면, 업로드한 파일 목록을 조회 합니다.
# 업로드한 모든 파일 ID 와 파일명을 출력합니다.
for file in client.files.list():
print(f"[파일 ID] {file.id} [파일명] {file.filename}")
[파일 ID] file-pXvkeNqOoMakeFYE9czPcHTL [파일명] SPRI_AI_Brief_2023년12월호.pdf [파일 ID] file-ywTSPKuBSAZD9HliWEBo1LHc [파일명] language_models_are_unsupervised_multitask_learners.pdf [파일 ID] file-kLr0kzRn5csryaMgeKmzYc7t [파일명] step_metrics.csv [파일 ID] file-N7dVCOHLcw5BiGCTX8tsYgof [파일명] faq_data.jsonl [파일 ID] file-f23erd9JTeBCtiq9MvqDeURV [파일명] 20231020bitumen.pdf [파일 ID] file-LCkqG3WPBCBwfy14jNPlvckm [파일명] 황순원-소나기.pdf [파일 ID] file-JPNbRJacb6StlOpHNZNJANic [파일명] 2023년_8월_경제전망보고서.pdf [파일 ID] file-6vZ6tOG3YOxdKBXbnrPOFQYI [파일명] pdfapi.py
# Assistant 가 참고할 파일 ID를 지정합니다.
file_ids = ["file-pXvkeNqOoMakeFYE9czPcHTL", "file-ywTSPKuBSAZD9HliWEBo1LHc"]
3) Function Schema 정의
다음으로는 Assistant 를 생성합니다. 생성시 tools에 function을 추가합니다.
# 스키마를 정의합니다.
function_schema = {
"name": "generate_quiz",
"description": "Generate a quiz to the student, and returns the student's response. A single quiz has multiple questions.",
"parameters": {
"type": "object",
"properties": {
"title": {"type": "string"},
"questions": {
"type": "array",
"description": "An array of questions, each with a title and multiple choice options.",
"items": {
"type": "object",
"properties": {
"question_text": {"type": "string"},
"choices": {"type": "array", "items": {"type": "string"}},
},
"required": ["question_text", "choices"],
},
},
},
"required": ["title", "questions"],
},
}
# 퀴즈를 출제하는 역할을 하는 챗봇을 생성합니다.
assistant = client.beta.assistants.create(
name="Quiz Generator",
instructions="You are an expert in generating multiple choice quizzes. Create quizzes based on uploaded files.",
model="gpt-4-turbo-preview",
tools=[
{"type": "retrieval"},
{"type": "function", "function": function_schema},
],
file_ids=file_ids,
)
ASSISTANT_ID = assistant.id
# 생성된 챗봇의 정보를 JSON 형태로 출력합니다.
show_json(assistant)
{'id': 'asst_ZQ3cikFTgBzN3EdRlRyADHKr',
'created_at': 1707848182,
'description': None,
'file_ids': ['file-pXvkeNqOoMakeFYE9czPcHTL',
'file-ywTSPKuBSAZD9HliWEBo1LHc'],
'instructions': 'You are an expert in generating multiple choice quizzes. Create quizzes based on uploaded files.',
'metadata': {},
'model': 'gpt-4-turbo-preview',
'name': 'Quiz Generator',
'object': 'assistant',
'tools': [{'type': 'retrieval'},
{'function': {'name': 'generate_quiz',
'description': "Generate a quiz to the student, and returns the student's response. A single quiz has multiple questions.",
'parameters': {'type': 'object',
'properties': {'title': {'type': 'string'},
'questions': {'type': 'array',
'description': 'An array of questions, each with a title and multiple choice options.',
'items': {'type': 'object',
'properties': {'question_text': {'type': 'string'},
'choices': {'type': 'array', 'items': {'type': 'string'}}},
'required': ['question_text', 'choices']}}},
'required': ['title', 'questions']}},
'type': 'function'}]}
4) 퀴즈 요청
-
새로운 스레드를 생성하고, Assistant 에게 상세한 지시사항과 함께 퀴즈를 출제를 요청합니다.
-
요청에 대한 답이 오면, 퀴즈를 출제하고 사용자로부터 정답 기입을 요청합니다.
# 새로운 스레드를 생성한 뒤 진행합니다.
thread_id = create_new_thread().id
# 퀴즈를 만들도록 요청합니다.
run = ask(
ASSISTANT_ID,
thread_id,
# 객관식 퀴즈에 대한 구체적인 지시사항을 기입합니다.
"3개의 객관식 퀴즈(multiple choice questions)를 만들어 주세요. "
"객관식 퀴즈의 선택지에 번호를 표기해주세요. 1~4까지 숫자로 시작하여야 합니다. "
"퀴즈는 내가 업로드한 파일에 관한 내용이어야 합니다. "
"내가 제출한 responses에 대한 피드백을 주세요. "
"내가 기입한 답, 정답, 제출한 답이 오답이라면 오답에 대한 피드백을 모두 포함해야 합니다. "
"모든 내용은 한글로 작성해 주세요. ",
)
[USER] 3개의 객관식 퀴즈(multiple choice questions)를 만들어 주세요. 객관식 퀴즈의 선택지에 번호를 표기해주세요. 1~4까지 숫자로 시작하여야 합니다. 퀴즈는 내가 업로드한 파일에 관한 내용이어야 합니다. 내가 제출한 responses에 대한 피드백을 주세요. 내가 기입한 답, 정답, 제출한 답이 오답이라면 오답에 대한 피드백을 모두 포함해야 합니다. 모든 내용은 한글로 작성해 주세요.
이제 생성된 퀴즈를 출력하고 사용자가 답변을 기입할 차례입니다.
# 퀴즈를 사용자에게 표시하는 함수를 정의합니다.
def display_quiz(title, questions, show_numeric=False):
print(f"제목: {title}\n")
responses = []
for q in questions:
# 질문을 출력합니다.
print(q["question_text"])
response = ""
# 각 선택지를 출력합니다.
for i, choice in enumerate(q["choices"]):
if show_numeric:
print(f"{i+1} {choice}")
else:
print(f"{choice}")
response = input("정답을 선택해 주세요: ")
responses.append(response)
print()
return responses
# requires_action 상태는 사용자의 응답 제출해야 합니다.
# 제출이 완료될 때까지 Assistant 는 최종 답변을 대기합니다.
# 늦게 제출시 만료(expired) 상태가 될 수 있습니다.
if run.status == "requires_action":
# 단일 도구 호출 추출
tool_call = run.required_action.submit_tool_outputs.tool_calls[0]
name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
responses = display_quiz(arguments["title"], arguments["questions"])
# 퀴즈를 표시하고 사용자의 응답을 반환합니다.
print("기입한 답(순서대로)")
print(responses)
제목: AI 관련 퀴즈 미국 바이든 대통령이 서명한 ‘안전하고 신뢰할 수 있는 AI 개발과 사용에 관한 행정명령’의 주요 골자는 무엇입니까? 1. AI의 개발과 사용에 있어 국제 협력 강화 2. AI 안전기준 마련 및 개인정보보호 3. AI 생성 콘텐츠에 대한 저작권 강화 4. AI를 이용한 사이버 보안 위협 감소 삼성전자가 공개한 자체 개발 생성 AI의 이름은 무엇입니까? 1. 삼성 가우스 2. 삼성 네오 3. 삼성 서플렉스 4. 삼성 마법사 Language Models are Unsupervised Multitask Learners 논문에서 언급된, 언어 모델이 자연어 처리 태스크에 접근하는 방법은 무엇입니까? 1. 각 태스크별 맞춤형 데이터셋을 이용한 supervised learning 2. 특정 도메인에 적합한 모델 설계 3. 다양한 웹페이지의 데이터셋인 WebText를 이용한 zero-shot learning 4. 고정된 알고리즘을 이용한 단일 태스크 학습 기입한 답(순서대로) ['2', '1', '1']
5) 피드백
-
마지막으로, 퀴즈를 제출하고 피드백을 받습니다.
-
결과를 출력하여 전체 내용을 확인합니다.
# 사용자 답변을 제출하기 위한 Run 을 생성합니다.
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread_id,
run_id=run.id,
tool_outputs=[
{
"tool_call_id": tool_call.id, # 대기중인 tool_call 의 ID
"output": json.dumps(responses), # 사용자 답변
}
],
)
# 스레드에서 실행을 기다립니다.
run = wait_on_run(run, thread_id)
# 실행이 완료되면, 실행의 상태를 출력합니다.
if run.status == "completed":
print("퀴즈를 제출했습니다.")
# 전체 대화내용 출력
print_message(get_response(thread_id).data[-2:])
퀴즈를 제출했습니다. [USER] 3개의 객관식 퀴즈(multiple choice questions)를 만들어 주세요. 객관식 퀴즈의 선택지에 번호를 표기해주세요. 1~4까지 숫자로 시작하여야 합니다. 퀴즈는 내가 업로드한 파일에 관한 내용이어야 합니다. 내가 제출한 responses에 대한 피드백을 주세요. 내가 기입한 답, 정답, 제출한 답이 오답이라면 오답에 대한 피드백을 모두 포함해야 합니다. 모든 내용은 한글로 작성해 주세요. [ASSISTANT] 퀴즈 결과 및 피드백입니다: ### 퀴즈 1: 미국 바이든 대통령이 서명한 ‘안전하고 신뢰할 수 있는 AI 개발과 사용에 관한 행정명령’의 주요 골자는 무엇입니까? - **당신의 답**: 2. AI 안전기준 마련 및 개인정보보호 - **정답**: 2. AI 안전기준 마련 및 개인정보보호 - **피드백**: 정답입니다! 해당 행정명령은 AI의 안전 및 보안 기준 마련, 개인정보보호, 형평성 및 시민권 향상, 소비자 보호, 노동자 지원, 혁신 및 경쟁 촉진, 그리고 국제 협력 등을 골자로 합니다【8†source】. ### 퀴즈 2: 삼성전자가 공개한 자체 개발 생성 AI의 이름은 무엇입니까? - **당신의 답**: 1. 삼성 가우스 - **정답**: 1. 삼성 가우스 - **피드백**: 정답입니다! 삼성전자는 자체 개발한 생성 AI '삼성 가우스'를 공개하였습니다【8†source】. ### 퀴즈 3: Language Models are Unsupervised Multitask Learners 논문에서 언급된, 언어 모델이 자연어 처리 태스크에 접근하는 방법은 무엇입니까? - **당신의 답**: 1. 각 태스크별 맞춤형 데이터셋을 이용한 supervised learning - **정답**: 3. 다양한 웹페이지의 데이터셋인 WebText를 이용한 zero-shot learning - **피드백**: 오답입니다. 본 논문에서는, 언어 모델이 WebText라는 수백만 웹페이지의 새로운 데이터셋에서 특정 자연어 처리 태스크에 대한 명시적인 감독 없이도 해당 태스크를 학습하기 시작할 수 있다고 언급되어 있습니다. 55 F1 점수로 CoQA 데이터셋에 대해 일치하거나 4가지 기준 시스템 중 3가지를 능가하는 성능을 달성하였으며 이는 zero-shot setting에서 논문의 접근 방식의 잠재력을 보여줍니다【9†source】.
끝으로
이번 튜토리얼은 Assistant 와 도구 3가지(Code Interpreter, Retrieval, Functions) 를 다뤘습니다.
Assistant 를 활용한 LLM 어플리케이션 제작에 많은 도움이 되었기를 바랍니다.
참고
-
Annotations: 파일 인용 구문 분석
-
Files: 스레드 범위 대비 어시스턴트 범위
-
Parallel Function Calls: 단일 단계에서 여러 도구를 호출하기
Reference
본 튜토리얼은 OpenAI Cookbook 노트북 파일을 참조하여 작성하였습니다.
- 본 문서의 원 저작권자는 openai 이며, 코드는
MIT License에 따라 사용이 허가된 파일입니다. - 원문 바로가기
댓글남기기