🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
LLMs를 활용한 문서 요약 가이드: Stuff, Map-Reduce, Refine 방법 총정리
이번 글은 LangChain 을 활용하여 문서를 요약하는 방법에 대하여 다룹니다. 특히, 문서 요약의 3가지 방식은 Stuff, Map-Reduce, Refine 방식에 대하여 알아보고, 각각의 방식 간의 차이점에 대하여 다룹니다.
개요
문서 집합(PDF, Notion 페이지, 고객 질문 등)을 가지고 있고, 내용을 요약하고 싶다고 가정해 보세요.LLMs는 텍스트를 이해하고 종합하는 데 능숙하기 때문에 이를 위한 훌륭한 도구입니다.
이 안내서에서는 LLMs를 사용하여 문서 요약을 수행하는 방법에 대해 살펴보겠습니다.
요약기를 구축할 때 중심적인 질문은 문서를 LLM의 컨텍스트 창에 어떻게 전달할 것인가입니다. 이를 위한 두 가지 일반적인 접근 방식은 다음과 같습니다:
-
Stuff: 단순히 모든 문서를 단일 프롬프트로 “넣는” 방식입니다. 이는 가장 간단한 접근 방식입니다. -
Map-reduce: 각 문서를 “map” 단계에서 개별적으로 요약한 다음, “reduce” 단계에서 요약본들을 최종 요약본으로 합치는 방식입니다. -
Refine: 입력 문서를 순회하며 반복적으로 답변을 업데이트하여 응답을 구성합니다. 각 문서에 대해, 모든 비문서 입력, 현재 문서, 그리고 최신 중간 답변을 LLM chain에 전달하여 새로운 답변을 얻습니다.
load_summarize_chain
미리보기를 제공하기 위해, 어떤 파이프라인도 단일 객체로 래핑될 수 있습니다: load_summarize_chain.
블로그 포스트를 요약하고 싶다고 가정해 봅시다. 몇 줄의 코드로 이를 생성할 수 있습니다.
먼저 환경 변수를 설정하고 패키지를 설치하세요:
# API KEY를 환경변수로 관리하기 위한 설정 파일
from dotenv import load_dotenv
# API KEY 정보로드
load_dotenv()
True
chain_type="stuff"를 사용할 수 있습니다.
chain_type="map_reduce" 또는 chain_type="refine"도 제공할 수 있습니다.
이 코드는 웹에서 문서를 로드하고, 이를 요약하기 위해 langchain 라이브러리와 OpenAI의 GPT 모델을 사용합니다.
먼저, WebBaseLoader를 사용하여 지정된 URL에서 문서를 로드합니다. 그 다음, ChatOpenAI를 사용하여 GPT-3.5 모델을 초기화합니다.
load_summarize_chain 함수를 통해 요약 작업을 위한 체인을 로드합니다.
마지막으로, 로드된 문서에 대해 요약 체인을 실행합니다. 이 과정은 AI를 활용하여 웹 문서를 요약하는 효율적인 방법을 제시합니다.
from langchain.chains.summarize import load_summarize_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
from langchain.callbacks.base import BaseCallbackHandler
# 웹 기반 문서 로더를 초기화합니다.
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
# 문서를 로드합니다.
docs = loader.load()
class StreamCallback(BaseCallbackHandler):
def on_llm_new_token(self, token, **kwargs):
print(f"{token}", end="", flush=True)
# OpenAI의 Chat 모델을 초기화합니다. 여기서는 온도를 0으로 설정하고 모델 이름을 지정합니다.
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo-16k",
streaming=True,
callbacks=[StreamCallback()],
)
# 요약 체인을 로드합니다. 체인 타입을 'stuff'로 지정합니다.
chain = load_summarize_chain(llm, chain_type="stuff")
# 문서에 대해 요약 체인을 실행합니다.
answer = chain.invoke({"input_documents": docs})
print(answer["output_text"])
The article discusses the concept of building autonomous agents powered by large language models (LLMs). It explores the components of such agents, including planning, memory, and tool use. The article provides case studies and examples of proof-of-concept demos, highlighting the challenges and limitations of LLM-powered agents. The author also provides citations and references for further reading.The article discusses the concept of building autonomous agents powered by large language models (LLMs). It explores the components of such agents, including planning, memory, and tool use. The article provides case studies and examples of proof-of-concept demos, highlighting the challenges and limitations of LLM-powered agents. The author also provides citations and references for further reading.
방법1. Stuff
chain_type="stuff"로 load_summarize_chain을 사용할 때, StuffDocumentsChain 을 사용합니다.
체인은 문서 목록을 가져와서 모두 프롬프트에 삽입한 후, 그 프롬프트를 LLM에 전달합니다:
-
먼저,
PromptTemplate를 사용하여 요약문 작성을 위한 프롬프트를 정의합니다. -
그 다음,
LLMChain을 사용하여 지정된 모델(gpt-3.5-turbo-16k)과 온도 설정(0)을 사용하는 언어 모델 체인을 생성합니다. -
이 체인은 입력된 텍스트에 대한 요약문을 생성하는 데 사용됩니다.
-
마지막으로,
StuffDocumentsChain을 사용하여 문서들을 결합하고, 이를LLMChain을 통해 요약합니다. -
이 과정은
loader.load()로 로드된 문서들에 대해 실행되며, 결과는 실시간 출력됩니다.
[참고]
load_summarize_chain대신StuffDocumentsChain을 사용하는 이점은 사용자 정의 프롬프트 입니다.
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
from langchain import hub
# 요약문을 작성하기 위한 프롬프트 정의 (직접 프롬프트를 작성하는 경우)
# prompt_template = """Please summarize the sentence according to the following REQUEST.
# REQUEST:
# 1. Summarize the main points in bullet points in KOREAN.
# 2. Each summarized sentence must start with an emoji that fits the meaning of the each sentence.
# 3. Use various emojis to make the summary more interesting.
# 4. Translate the summary into Korean if it is written in English.
# 5. DO NOT translate any technical terms.
# 6. DO NOT include any unnecessary information.
# CONTEXT:
# {context}
# SUMMARY:"
# """
# prompt = PromptTemplate.from_template(prompt_template)
# 원격 저장소에서 프롬프트를 가져오는 경우
prompt = hub.pull("teddynote/summary-stuff-documents-korean")
# LLM 체인 정의
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo-16k",
streaming=True,
callbacks=[StreamCallback()],
)
# LLMChain 정의
llm_chain = LLMChain(llm=llm, prompt=prompt)
# StuffDocumentsChain 정의
stuff_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="context")
docs = loader.load()
response = stuff_chain.invoke({"input_documents": docs})
🤖 LLM을 사용한 자율 에이전트 시스템은 LLM을 에이전트의 뇌로 사용하고 계획, 메모리, 도구 사용과 같은 여러 구성 요소로 보완됩니다. 📝 계획 구성 요소는 큰 작업을 작은 하위 목표로 분해하고 에이전트가 과거 행동을 자가 비판하고 반영하여 최종 결과의 품질을 향상시킵니다. 🧠 메모리 구성 요소는 감각 메모리, 단기 메모리, 장기 메모리로 구성되며, 외부 벡터 저장소와 빠른 검색을 통해 정보를 보존하고 검색할 수 있습니다. 🔧 도구 사용 구성 요소는 외부 API를 호출하여 모델 가중치에 없는 추가 정보를 얻을 수 있습니다. 🔍 이러한 구성 요소를 사용하여 과학적 발견 에이전트, 생성 에이전트 시뮬레이션, 개념 증명 예제 등을 구축할 수 있습니다. 🚀 그러나 유한한 컨텍스트 길이, 장기적인 계획 및 작업 분해의 어려움, 자연어 인터페이스의 신뢰성 등 몇 가지 제한 사항이 있습니다.
좋습니다! 우리는 load_summarize_chain을 사용하여 이전 결과를 재현할 수 있음을 확인할 수 있습니다.
방법2. Map-Reduce
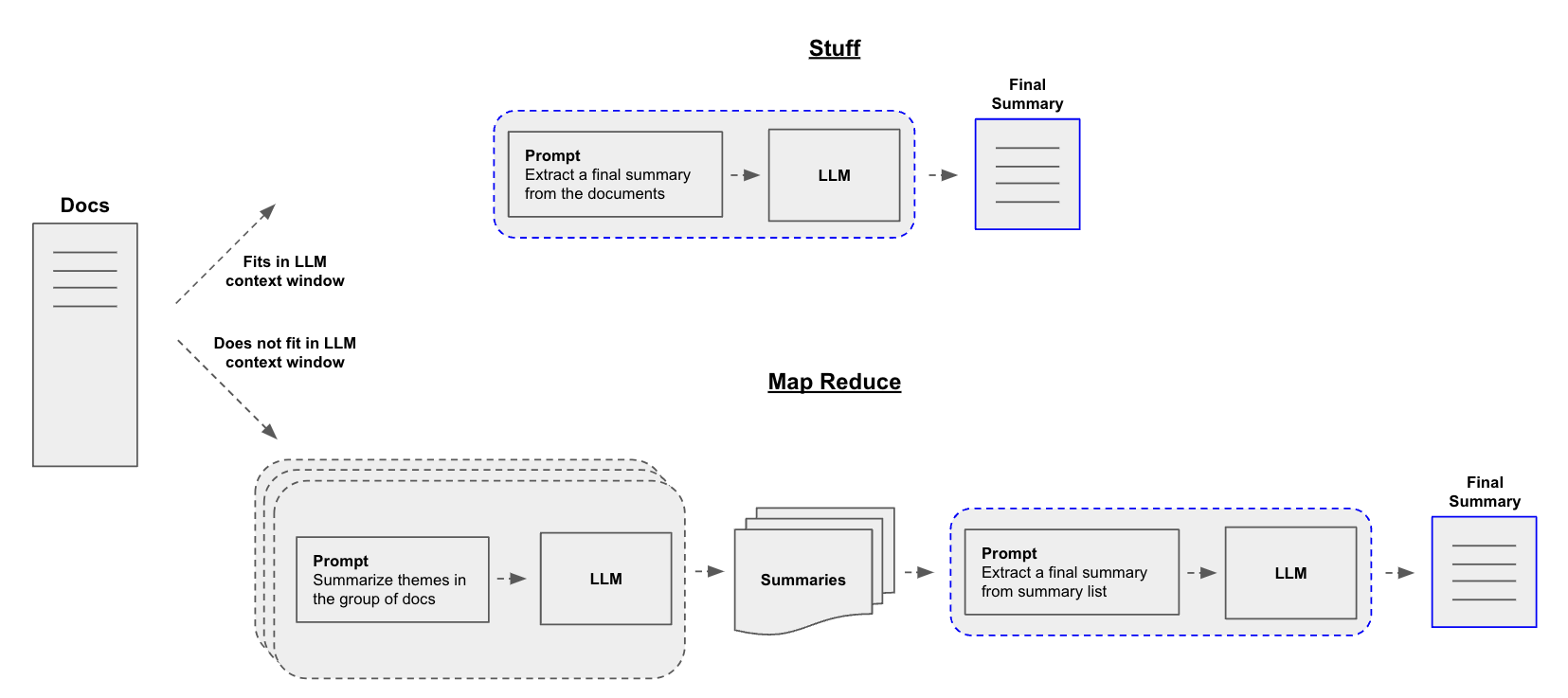
출처: https://python.langchain.com/docs/use_cases/summarization
Map reduce 접근 방식을 자세히 살펴보겠습니다. 이를 위해, 우리는 먼저 각 문서를 개별 요약으로 매핑하기 위해 LLMChain을 사용할 것입니다. 그런 다음 ReduceDocumentsChain을 사용하여 그 요약들을 하나의 전역 요약으로 결합할 것입니다.
먼저, 각 문서를 개별 요약으로 매핑하기 위해 사용할 LLMChain을 지정합니다.
-
ChatOpenAI인스턴스를 생성하고, 이를 사용하여 문서 집합에 대한 주요 테마를 식별하는 맵(map) 작업을 정의합니다. -
맵 작업은
map_template을 사용하여 정의되며, 이 템플릿은 문서 집합을 입력으로 받아 주요 테마를 식별하도록 요청합니다. -
PromptTemplate.from_template메서드를 사용하여map_template에서 프롬프트 템플릿을 생성하고,LLMChain을 사용하여 맵 작업을 실행합니다.
Prompt Hub를 사용하여 프롬프트를 저장하고 가져올 수도 있습니다.
예를 들어, 여기에서 맵 프롬프트를 확인하세요 여기.
langchain 라이브러리를 사용하여 특정 자원을 가져오고, 이를 활용해 LLMChain 인스턴스를 생성하는 과정을 설명합니다. hub.pull 메소드를 통해 ‘rlm/map-prompt’ 자원을 가져오고, 이를 LLMChain의 생성자에 전달하여 인스턴스를 초기화합니다. 이 과정에서 llm 변수는 사전에 정의되어 있어야 합니다.
from langchain.chains import MapReduceDocumentsChain, ReduceDocumentsChain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import hub
llm = ChatOpenAI(
temperature=0,
model_name="gpt-3.5-turbo",
streaming=True,
callbacks=[StreamCallback()],
)
# # map-prompt 를 직접 정의하는 경우 다음의 예시를 참고하세요.
# map_template = """The following is a set of documents
# {docs}
# Based on this list of docs, please identify the main themes
# Helpful Answer:"""
# map_prompt = PromptTemplate.from_template(map_template)
# langchain 허브에서 'rlm/map-prompt'를 가져옵니다.
map_prompt = hub.pull("teddynote/map-prompt")
map_prompt
PromptTemplate(input_variables=['documents'], template='You are a helpful expert journalist in extracting the main themes from a GIVEN DOCUMENTS below.\nPlease provide a comprehensive summary of the GIVEN DOCUMENTS in numbered list format. \nThe summary should cover all the key points and main ideas presented in the original text, while also condensing the information into a concise and easy-to-understand format. \nPlease ensure that the summary includes relevant details and examples that support the main ideas, while avoiding any unnecessary information or repetition. \nThe length of the summary should be appropriate for the length and complexity of the original text, providing a clear and accurate overview without omitting any important information.\n\nGIVEN DOCUMENTS:\n{documents}\n\nFORMAT:\n1. main theme 1\n2. main theme 2\n3. main theme 3\n...\n\nCAUTION:\n- DO NOT list more than 5 main themes.\n\nHelpful Answer:\n')
# LLMChain 인스턴스를 생성하며, 이때 LLM과 프롬프트로 'map_prompt'를 사용합니다.
map_chain = LLMChain(llm=llm, prompt=map_prompt)
ReduceDocumentsChain은 문서 매핑 결과를 가져와 단일 출력으로 축소하는 역할을 합니다. 일반적인 CombineDocumentsChain (예: StuffDocumentsChain)을 감싸지만, 누적 크기가 token_max를 초과하는 경우 문서를 축소하여 CombineDocumentsChain에 전달할 수 있는 기능을 추가합니다. 이 예에서, 우리는 문서를 결합하기 위해 사용한 체인을 문서를 축소하는 데에도 재사용할 수 있습니다.
따라서 우리가 매핑한 문서의 누적 토큰 수가 4000 토큰을 초과하는 경우, 우리는 4000 토큰 미만의 배치로 문서를 재귀적으로 StuffDocumentsChain에 전달하여 배치 요약을 생성합니다. 그리고 이러한 배치 요약이 누적으로 4000 토큰 미만이 되면, 마지막으로 모든 문서를 StuffDocumentsChain에 한 번 더 전달하여 최종 요약을 생성합니다.
이 코드는 요약들을 통합하여 주요 테마의 최종 요약을 생성하는 과정을 정의합니다. reduce_template 변수는 요약들의 집합을 입력으로 받아, 이를 하나의 통합된 요약으로 축약하는 템플릿 문자열을 저장합니다. 이 템플릿은 {docs}를 요약들의 자리 표시자로 사용하며, 최종적으로 PromptTemplate.from_template 함수를 사용하여 reduce_prompt 변수에 템플릿을 초기화합니다.
# reduce-prompt 를 직접 정의하는 경우 다음의 예시를 참고하세요.
# reduce_template = """The following is set of summaries:
# {docs}
# Take these and distill it into a final, consolidated summary of the main themes.
# Helpful Answer:"""
# reduce_prompt = PromptTemplate.from_template(reduce_template)
이 코드는 hub.pull 함수를 사용하여 rlm/map-prompt라는 리소스를 prompt hub에서 가져오는 과정을 보여줍니다. hub.pull 메소드는 지정된 리소스를 로컬 환경으로 가져오는 데 사용됩니다. 여기서 reduce_prompt 변수는 가져온 리소스를 저장하는 데 사용됩니다.
# prompt hub에서도 얻을 수 있음을 위에서 언급했듯이
reduce_prompt = hub.pull("teddynote/reduce-prompt-korean")
reduce_prompt
PromptTemplate(input_variables=['doc_summaries'], template='You are a helpful expert in summary writing.\nYou are given numbered lists of summaries.\nExtract top 10 most important insights from the summaries.\nThen, write a summary of the insights in KOREAN.\n\nLIST OF SUMMARIES:\n{doc_summaries}\n\nHelpful Answer:\n')
이 문서는 LLMChain, StuffDocumentsChain, ReduceDocumentsChain 클래스를 사용하여 문서 처리 파이프라인을 구성하는 방법을 보여줍니다. LLMChain은 초기 처리 단계로, 특정 프롬프트를 사용하여 언어 모델(llm)을 실행합니다. StuffDocumentsChain은 여러 문서를 하나의 문자열로 결합하여 LLMChain에 전달하는 역할을 합니다. 마지막으로, ReduceDocumentsChain은 문서들을 결합하고, 지정된 토큰 수(token_max)를 초과하지 않도록 반복적으로 축소하는 과정을 담당합니다. 이 과정에서, 문서들이 StuffDocumentsChain의 컨텍스트를 초과할 경우, 동일한 체인(collapse_documents_chain)을 사용하여 처리합니다.
# 연쇄 실행
reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt)
# 문서 리스트를 받아 하나의 문자열로 결합한 후 LLMChain에 전달
combine_documents_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="doc_summaries"
)
# 매핑된 문서들을 결합하고 반복적으로 축소
reduce_documents_chain = ReduceDocumentsChain(
# 최종적으로 호출되는 체인입니다.
combine_documents_chain=combine_documents_chain,
# `StuffDocumentsChain`의 컨텍스트를 초과하는 문서들을 처리
collapse_documents_chain=combine_documents_chain,
# 문서들을 그룹화할 최대 토큰 수.
token_max=4096,
)
우리의 map과 reduce 체인을 하나로 결합해 봅시다.
이 코드는 문서들을 매핑하고 리듀스하는 과정을 통해 결합하는 MapReduceDocumentsChain 객체를 생성하고, 문자 기반으로 텍스트를 분할하는 CharacterTextSplitter 객체를 사용하여 문서들을 분할합니다. MapReduceDocumentsChain은 매핑 체인(llm_chain), 리듀스 체인(reduce_documents_chain), 문서를 저장할 변수 이름(document_variable_name), 그리고 매핑 단계의 중간 결과를 반환할지 여부(return_intermediate_steps)를 설정하여 초기화됩니다. CharacterTextSplitter는 from_tiktoken_encoder 메소드를 통해 초기화되며, 이는 분할할 청크의 크기(chunk_size)와 청크 간 겹침(chunk_overlap)을 설정합니다.
# 문서들을 매핑하여 체인을 거친 후 결과를 결합하는 과정
map_reduce_chain = MapReduceDocumentsChain(
# 매핑 체인
llm_chain=map_chain,
# 리듀스 체인
reduce_documents_chain=reduce_documents_chain,
# llm_chain에서 문서들을 넣을 변수 이름
document_variable_name="documents",
# 매핑 단계의 결과를 출력에 포함시킴
return_intermediate_steps=False,
)
# 문자를 기준으로 텍스트를 분할하는 객체 생성
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=50,
separators=["\n\n", "\n", "(?<=\. )", " ", ""],
length_function=len,
)
# 문서들을 분할
split_docs = text_splitter.split_documents(docs)
map_reduce_chain.run(split_docs)는 split_docs를 인자로 받아 map_reduce_chain의 run 메서드를 실행하고, 그 결과를 출력합니다. 이는 MapReduce 패턴을 활용하여 데이터를 처리하는 과정을 간략하게 보여줍니다. 여기서 split_docs는 처리할 데이터를 나타내며, map_reduce_chain은 해당 데이터에 적용할 MapReduce 연산의 체인을 나타냅니다.
# split_docs를 map_reduce_chain의 run 메서드에 전달하여 실행한 결과를 출력합니다.
summary_result = map_reduce_chain.invoke({"input_documents": split_docs})
1. The document discusses LLM Powered Autonomous Agents, providing an overview of the agent system and its components. 2. The first component discussed is planning, which involves task decomposition and self-reflection. 3. The second component is memory, which includes different types of memory and the use of Maximum Inner Product Search (MIPS). 4. The third component is tool use, with case studies on a scientific discovery agent and generative agents simulation, as well as proof-of-concept examples. 5. The document also highlights the challenges associated with LLM Powered Autonomous Agents and provides citations and references for further reading.1. Building agents with LLM as the core controller is a concept that has been demonstrated through proof-of-concept demos like AutoGPT, GPT-Engineer, and BabyAGI. 2. LLM has the potential to go beyond generating well-written copies, stories, essays, and programs and can be used as a powerful general problem solver. 3. In a LLM-powered autonomous agent system, LLM functions as the agent's brain and is complemented by key components such as planning and memory. 4. Planning involves breaking down large tasks into smaller subgoals to efficiently handle complex tasks. 5. Memory allows the agent to engage in self-criticism, self-reflection, and learning from past actions to improve the quality of future results.1. The use of short-term memory in machine learning models allows for in-context learning and quick acquisition of new information. 2. Long-term memory enables machine learning models to retain and recall vast amounts of information over extended periods of time, often by utilizing external storage and efficient retrieval methods. 3. External APIs are utilized by machine learning models to access additional information that may be missing from the model's pre-trained weights, such as real-time data, code execution capabilities, and proprietary information sources. (중략...) 요약: LLM에 대한 적대적 공격은 LLM의 입력을 조작하여 오도하는 출력을 생성하는 것을 의미합니다. Prompt 엔지니어링은 LLM의 행동을 안내하고 편견이나 유해한 응답을 피하기 위해 중요합니다. NLP와 언어 모델은 다양한 응용 분야에서 중요한 역할을 합니다. 언어 모델은 인간과 유사한 텍스트를 생성하는 알고리즘입니다. LLM의 에이전트는 특정 목표나 의도와 일치하는 텍스트를 생성하는 능력을 의미합니다. 스티어러빌리티는 에이전트가 원하는 출력으로 제어되거나 안내될 수 있는 정도를 나타냅니다. LLM의 스티어러빌리티를 향상시키기 위한 기술에 대해 논의되었습니다. LLM은 보다 넓은 영향과 미래 방향을 가지고 있습니다. LLM의 사용에는 잠재적인 위험과 윤리적 고려 사항이 있습니다. 이러한 도전에 대응하기 위해 추가적인 연구와 개발이 필요합니다.
print(summary_result["output_text"])
요약: LLM에 대한 적대적 공격은 LLM의 입력을 조작하여 오도하는 출력을 생성하는 것을 의미합니다. Prompt 엔지니어링은 LLM의 행동을 안내하고 편견이나 유해한 응답을 피하기 위해 중요합니다. NLP와 언어 모델은 다양한 응용 분야에서 중요한 역할을 합니다. 언어 모델은 인간과 유사한 텍스트를 생성하는 알고리즘입니다. LLM의 에이전트는 특정 목표나 의도와 일치하는 텍스트를 생성하는 능력을 의미합니다. 스티어러빌리티는 에이전트가 원하는 출력으로 제어되거나 안내될 수 있는 정도를 나타냅니다. LLM의 스티어러빌리티를 향상시키기 위한 기술에 대해 논의되었습니다. LLM은 보다 넓은 영향과 미래 방향을 가지고 있습니다. LLM의 사용에는 잠재적인 위험과 윤리적 고려 사항이 있습니다. 이러한 도전에 대응하기 위해 추가적인 연구와 개발이 필요합니다.
더 깊이 들어가기
맞춤 설정
- 위에서 보여진 것처럼, map과 reduce 단계에 대한 LLMs와 프롬프트를 맞춤 설정할 수 있습니다.
실제 사용 사례
-
LangChain 문서에 대한 질문(사용자 상호작용 분석)에 대한 사례 연구로 이 블로그 포스트를 참조하세요!
-
블로그 포스트와 관련된 repo는 요약 수단으로 클러스터링을 도입합니다.
-
이는
stuff또는map-reduce접근 방식을 넘어서 고려할 가치가 있는 세 번째 경로를 열어줍니다.
방법3. Refine
출처: https://python.langchain.com/docs/use_cases/summarization
RefineDocumentsChain은 map-reduce와 유사합니다:
Refine documents chain은 입력 문서를 순회하며 반복적으로 답변을 업데이트하여 응답을 구성합니다. 각 문서에 대해, 모든 비문서 입력, 현재 문서, 그리고 최신 중간 답변을 LLM chain에 전달하여 새로운 답변을 얻습니다.
이는 chain_type="refine"이 지정되어 있으면 쉽게 실행할 수 있습니다.
이 함수는 load_summarize_chain을 사용하여 특정 유형의 요약 체인을 로드하고, 이를 run 메소드를 통해 실행합니다. 여기서 llm은 언어 모델을 나타내며, chain_type="refine"은 요약 과정에서 세부 조정을 위한 체인 유형을 지정합니다. split_docs는 처리할 문서들을 나타냅니다.
# llm을 사용하여 'refine' 유형의 요약 체인을 로드합니다.
chain = load_summarize_chain(llm, chain_type="refine")
# split_docs를 처리하기 위해 체인을 실행합니다.
chain.run(split_docs)
This text discusses various aspects of using Databricks, including its benefits, partnerships, and solutions in different industries. It highlights features such as data integration, governance, real-time analysis, AI, and open marketplaces. The text also mentions the pricing and cost estimation for using Databricks in different cloud environments.This text discusses various aspects of using Databricks, including its benefits, partnerships, and solutions in different industries. It highlights features such as data integration, governance, real-time analysis, AI, and open marketplaces. The text also mentions the pricing and cost estimation for using Databricks in different cloud environments. Additionally, it provides information on professional services, education and certification, events, and customer support offered by Databricks. (중략...) It includes figures showing Model Bandwidth Utilization (MBU) and Model Flop Utilization (MFU) in different hardware configurations and provides insights into token generation time, GPU parallel processing, and batch size's impact on latency. The text further discusses batching inference requests, the use of Grouped Query Attention (GQA) and Multi-Query Attention (MQA) in LLM models, and the quantization of KV cache memory. It concludes by mentioning the importance of measuring end-to-end server performance and the availability of Databricks for LLM inference deployment.
프롬프트를 제공하고 중간 단계를 반환하는 것도 가능합니다.
Refine 방법으로 텍스트 요약 작업을 위한 프로세스를 설정합니다.
PromptTemplate.from_template 메소드를 사용하여 요약 및 요약 다듬기 작업에 사용될 템플릿을 생성합니다.
load_summarize_chain 함수는 요약 생성 및 다듬기 과정을 관리하는 체인을 로드합니다. 이 체인은 초기 요약 생성(prompt)과 기존 요약의 개선(refine_prompt) 단계를 포함합니다.
마지막으로, chain 함수는 주어진 문서(input_documents)에 대한 최종 요약 결과를 반환합니다.
prompt_template = """Write a concise summary of the following:
{text}
CONCISE SUMMARY:"""
prompt = PromptTemplate.from_template(prompt_template)
refine_template = (
"Your job is to produce a final summary\n"
"We have provided an existing summary up to a certain point: {existing_answer}\n"
"We have the opportunity to refine the existing summary"
"(only if needed) with some more context below.\n"
"------------\n"
"{text}\n"
"------------\n"
"Given the new context, refine the original summary in Korean"
"If the context isn't useful, return the original summary."
)
refine_prompt = PromptTemplate.from_template(refine_template)
chain = load_summarize_chain(
llm=llm,
chain_type="refine",
question_prompt=prompt,
refine_prompt=refine_prompt,
return_intermediate_steps=True,
input_key="input_documents",
output_key="output_text",
)
result = chain.invoke({"input_documents": split_docs}, return_only_outputs=True)
이 기사는 인간의 개입 없이 작업을 수행할 수 있는 지능형 시스템인 LLM 기반 자율 에이전트에 대해 논의한다. 에이전트는 계획, 기억 및 도구 사용이라는 세 가지 주요 구성 요소로 구성된다. 계획 구성 요소는 작업 분해와 자기 반성을 포함한다. 기억 구성 요소에는 다양한 유형의 기억과 최대 내적 제품 검색(MIPS)의 사용이 포함된다. 도구 사용 구성 요소는 과학적 발견 에이전트 및 생성 에이전트 시뮬레이션과 같은 사례 연구를 통해 시연된다. 이 기사는 또한 LLM 기반 자율 에이전트를 구현하는 데 직면하는 도전과제를 강조한다.이 기사는 인간의 개입 없이 작업을 수행할 수 있는 지능형 시스템인 LLM 기반 자율 에이전트에 대해 논의한다. 에이전트는 계획, 기억 및 도구 사용이라는 세 가지 주요 구성 요소로 구성된다. 계획 구성 요소는 작업 분해와 자기 반성을 포함한다. 기억 구성 요소에는 다양한 유형의 기억과 최대 내적 제품 검색(MIPS)의 사용이 포함된다. 도구 사용 구성 요소는 과학적 발견 에이전트 및 생성 에이전트 시뮬레이션과 같은 사례 연구를 통해 시연된다. (중략) 이 기사는 LLM 기반 자율 에이전트의 아키텍처를 코드로 구현하는 방법에 대한 설명을 포함하고 있으며, 추가적인 컨텍스트와 함께 제공됩니다. 이외에도 참고할만한 자료로는 Joon Sung Park 등의 논문 [16]과 AutoGPT [17], GPT-Engineer [18]의 GitHub 링크가 있습니다.이 기사는 LLM 기반 자율 에이전트의 아키텍처를 코드로 구현하는 방법에 대한 설명을 포함하고 있으며, 대화 샘플을 통해 추가적인 컨텍스트를 제공합니다. 또한, Joon Sung Park 등의 논문 [16]과 AutoGPT [17], GPT-Engineer [18]의 GitHub 링크를 참고할 수 있습니다. LLM-centered agents의 주요 아이디어와 데모를 통해 나타나는 몇 가지 공통적인 제한 사항에 대해 설명하고 있습니다. 이 기사에서는 LLM 기반 자율 에이전트의 제한된 컨텍스트 용량과 관련된 도전과 문제점을 다루고 있습니다. 또한, LLM과 메모리, 도구 등 외부 구성 요소 간의 자연어 인터페이스에 의존하는 현재의 에이전트 시스템의 한계와 신뢰성 문제를 다루고 있습니다. 이 기사는 LLM 기반 자율 에이전트의 아키텍처를 코드로 구현하는 방법에 대한 설명을 포함하고 있으며, 추가적인 컨텍스트와 함께 제공됩니다.
print(result["output_text"])는 결과 딕셔너리 result에서 'output_text' 키에 해당하는 값을 출력합니다. 이 구문은 딕셔너리 내 특정 키의 값을 검색하고, 그 값을 콘솔에 출력하는 기본적인 Python 코드 예시입니다.
print(
result["output_text"]
) # 결과 딕셔너리에서 'output_text' 키에 해당하는 값을 출력합니다.
이 기사는 LLM 기반 자율 에이전트의 아키텍처를 코드로 구현하는 방법에 대한 설명을 포함하고 있으며, 대화 샘플을 통해 추가적인 컨텍스트를 제공합니다. 또한, Joon Sung Park 등의 논문 [16]과 AutoGPT [17], GPT-Engineer [18]의 GitHub 링크를 참고할 수 있습니다. LLM-centered agents의 주요 아이디어와 데모를 통해 나타나는 몇 가지 공통적인 제한 사항에 대해 설명하고 있습니다. 이 기사에서는 LLM 기반 자율 에이전트의 제한된 컨텍스트 용량과 관련된 도전과 문제점을 다루고 있습니다. 또한, LLM과 메모리, 도구 등 외부 구성 요소 간의 자연어 인터페이스에 의존하는 현재의 에이전트 시스템의 한계와 신뢰성 문제를 다루고 있습니다. 이 기사는 LLM 기반 자율 에이전트의 아키텍처를 코드로 구현하는 방법에 대한 설명을 포함하고 있으며, 추가적인 컨텍스트와 함께 제공됩니다.
이 함수는 result 딕셔너리의 'intermediate_steps' 키에 저장된 리스트에서 처음 세 요소를 선택하고, 이들 사이에 두 줄바꿈(\n\n)을 삽입하여 연결한 문자열을 출력합니다. 이는 중간 계산 단계나 결과를 시각적으로 구분하여 표시할 때 유용합니다.
print("\n\n".join(result["intermediate_steps"][:3]))
This article discusses LLM powered autonomous agents, which are intelligent systems that can perform tasks without human intervention. The agents consist of three main components: planning, memory, and tool use. The planning component involves task decomposition and self-reflection. The memory component includes different types of memory and the use of Maximum Inner Product Search (MIPS). The tool use component is demonstrated through case studies, such as a scientific discovery agent and generative agents simulation. The article also highlights the challenges of implementing LLM powered autonomous agents. 이 기사는 인간의 개입 없이 작업을 수행할 수 있는 지능형 시스템인 LLM 기반 자율 에이전트에 대해 논의한다. 에이전트는 계획, 기억 및 도구 사용이라는 세 가지 주요 구성 요소로 구성된다. 계획 구성 요소는 작업 분해와 자기 반성을 포함한다. 기억 구성 요소에는 다양한 유형의 기억과 최대 내적 제품 검색(MIPS)의 사용이 포함된다. 도구 사용 구성 요소는 과학적 발견 에이전트 및 생성 에이전트 시뮬레이션과 같은 사례 연구를 통해 시연된다. 이 기사는 또한 LLM 기반 자율 에이전트를 구현하는 데 직면하는 도전과제를 강조한다. 이 기사는 인간의 개입 없이 작업을 수행할 수 있는 지능형 시스템인 LLM 기반 자율 에이전트에 대해 논의한다. 에이전트는 계획, 기억 및 도구 사용이라는 세 가지 주요 구성 요소로 구성된다. 계획 구성 요소는 작업 분해와 자기 반성을 포함한다. 기억 구성 요소에는 다양한 유형의 기억과 최대 내적 제품 검색(MIPS)의 사용이 포함된다. 도구 사용 구성 요소는 과학적 발견 에이전트 및 생성 에이전트 시뮬레이션과 같은 사례 연구를 통해 시연된다. 이 기사는 또한 LLM 기반 자율 에이전트를 구현하는 데 직면하는 도전과제를 강조한다. 에이전트는 단기 기억과 장기 기억을 활용하여 학습하며, 외부 API를 호출하여 추가 정보를 얻고, 모델 가중치 이후에 변경하기 어려운 현재 정보, 코드 실행 능력, 독점 정보 소스에 접근하는 등의 기능을 갖추게 된다.
AnalyzeDocumentChain: 한 번의 체인으로 분할 및 요약
편의를 위해, 우리는 긴 문서의 텍스트 분할과 요약을 단일 AnalyzeDocumentsChain으로 묶을 수 있습니다.
AnalyzeDocumentChain 클래스는 문서 분석 및 요약 작업을 위한 체인을 생성합니다. 이 예제에서는 AnalyzeDocumentChain 인스턴스를 생성하고, combine_docs_chain과 text_splitter를 인자로 전달하여 초기화합니다. 이후, 첫 번째 문서(docs[0])의 page_content를 사용하여 문서 요약 프로세스를 실행합니다. 이 과정은 문서의 내용을 분석하고 요약하는 데 사용됩니다.
from langchain.chains import AnalyzeDocumentChain
# AnalyzeDocumentChain 인스턴스를 생성합니다. 이때, combine_docs_chain과 text_splitter를 인자로 전달합니다.
summarize_document_chain = AnalyzeDocumentChain(
combine_docs_chain=chain, text_splitter=text_splitter
)
# 첫 번째 문서의 페이지 내용을 사용하여 문서 요약 프로세스를 실행합니다.
summarized_result = summarize_document_chain.invoke(
{"input_document": docs[0].page_content}
)
이 기사는 인간의 개입 없이 작업을 수행할 수 있는 지능형 시스템인 LLM 기반 자율 에이전트에 대해 논의한다. 에이전트는 계획, 기억 및 도구 사용이라는 세 가지 주요 구성 요소로 구성된다. 계획 구성 요소는 작업 분해와 자기 반성을 포함한다. 기억 구성 요소에는 다양한 유형의 기억과 최대 내적 제품 검색(MIPS)의 사용이 포함된다. 도구 사용 구성 요소는 과학적 발견 에이전트 및 생성 에이전트 시뮬레이션과 같은 사례 연구를 통해 시연된다. (중략...) 그런 다음 필요한 경우 도구를 사용하여 사용자가 제공한 프롬프트에 답변하도록 지시됩니다. 지시는 ReAct 형식을 따르도록 모델에게 알려줍니다 - 생각, 동작, 동작 입력, 관찰. 하지만 LLM을 사용하여 도메인 전문성이 필요한 작업의 성능을 평가할 때, LLM 기반 평가와 전문가 평가의 결과가 다를 수 있습니다. 이는 LLM이 자체적으로 도메인 전문성을 갖지 않기 때문에 발생하는 문제일 수 있습니다. 따라서 LLM을 사용하여 작업 결과의 정확성을 평가할 때는 주의가 필요합니다. 또한, 새로운 context에 따라서 "improve_code", "write_tests", "execute_python_file", "generate_image" 등의 작업을 수행할 수 있습니다. 이러한 작업은 LLM의 다양한 도구 사용 능력을 보여주는 예시입니다. 또한, Joon Sung Park 등은 "Generative Agents: Interactive Simulacra of Human Behavior"에서 인간 행동의 상호작용적인 시뮬라크인 생성 에이전트에 대해 연구하였습니다. AutoGPT와 GPT-Engineer는 ChatGPT를 개선하기 위한 프로젝트입니다. Prompt Engineering은 LLM의 성능을 향상시키기 위한 방법 중 하나입니다.
print(summarized_result["output_text"])
ChatGPT 플러그인과 OpenAI API 함수 호출은 실제로 작동하는 도구 사용 능력이 강화된 LLM의 좋은 예입니다. 도구 API의 컬렉션은 다른 개발자(플러그인의 경우) 또는 자체 정의(함수 호출의 경우)로 제공될 수 있습니다. HuggingGPT는 (Shen et al. 2023)에서 ChatGPT를 작업 계획자로 사용하여 HuggingFace 플랫폼에서 사용 가능한 모델을 선택하고 실행 결과에 기반하여 응답을 요약하는 프레임워크입니다. HuggingGPT 시스템은 4단계로 구성되어 있습니다. 첫 번째 단계는 작업 계획으로, LLM이 사용자 요청을 여러 작업으로 파싱합니다. 각 작업에는 작업 유형, ID, 종속성 및 인수와 관련된 네 가지 속성이 있습니다. LLM은 few-shot 예제를 사용하여 작업 파싱과 계획을 수행하는 데 도움을 받습니다. AI 어시스턴트는 사용자 입력을 여러 작업으로 파싱할 수 있으며, 작업은 작업 유형, ID, 종속성 및 인수와 관련된 속성을 가지고 있습니다. 작업 간에는 논리적인 관계가 있으며, 작업 순서를 유의해야 합니다. 사용자 입력을 파싱할 수 없는 경우 빈 JSON으로 응답해야 합니다. LLM은 모델 선택 단계에서 전문 모델에 작업을 분배하고, 요청을 다중 선택 질문으로 구성합니다. LLM은 선택할 수 있는 모델 목록을 제시받습니다. 제한된 문맥 길이로 인해 작업 유형에 기반한 필터링이 필요합니다. AI 어시스턴트는 사용자 요청을 처리하기 위해 모델 목록에서 적합한 모델을 선택하는 데 도움을 줍니다. AI 어시스턴트는 가장 적합한 모델의 모델 ID만 출력합니다. 출력은 엄격한 JSON 형식이어야 하며, "id": "id", "reason": "선택 이유에 대한 자세한 설명"과 같은 형식을 따라야 합니다. AI 어시스턴트는 사용자의 요청에 직접적으로 응답한 후, 작업 과정을 설명하고 분석 및 모델 추론 결과를 사용자에게 제시해야 합니다. 추론 결과에 파일 경로가 포함된 경우, 사용자에게 완전한 파일 경로를 알려주어야 합니다. HuggingGPT를 실제 환경에서 사용하기 위해서는 몇 가지 문제를 해결해야 합니다. 첫째, LLM 추론 라운드와 다른 모델과의 상호작용이 프로세스를 느리게 만드는 효율성 개선이 필요합니다. 둘째, 복잡한 작업 내용을 전달하기 위해 긴 문맥 창을 필요로 합니다. 셋째, LLM 출력과 외부 모델 서비스의 안정성을 개선해야 합니다. API-Bank (Li et al. 2023)은 도구 강화된 LLM의 성능을 평가하기 위한 벤치마크입니다. 이 벤치마크에는 53개의 일반적으로 사용되는 API 도구, 완전한 도구 강화된 LLM 워크플로우 및 568개의 API 호출이 포함된 264개의 주석이 달린 대화가 포함되어 있습니다. API의 선택은 검색 엔진, 계산기, 캘린더 쿼리, 스마트 홈 제어, 일정 관리, 건강 데이터 관리, 계정 인증 워크플로우 등 다양한 API를 포함하고 있습니다. 많은 수의 API가 있기 때문에, LLM은 먼저 API 검색 엔진에 접근하여 호출할 적절한 API를 찾은 다음 해당 문서를 사용하여 호출합니다. API-Bank 워크플로우에서 LLM은 몇 가지 결정을 내려야 합니다. 각 단계에서 결정의 정확성을 평가할 수 있습니다. 이 결정에는 다음이 포함됩니다: API 호출이 필요한지 여부, 호출할 적절한 API 식별, API 결과에 기반한 응답. 이 벤치마크는 에이전트의 도구 사용 능력을 세 가지 수준에서 평가합니다. Level-1은 API 호출 능력을 평가하며, Level-2는 API 검색 능력을, Level-3은 API 검색과 호출 이상의 계획 능력을 평가합니다. ChemCrow (Bran et al. 2023)는 LLM이 유기 합성, 약물 개발 및 재료 설계와 같은 작업을 수행하기 위해 13개의 전문가가 설계한 도구로 보강된 도메인 특정 예입니다. LangChain에서 구현된 워크플로우는 이전에 설명한 ReAct와 MRKLs를 결합한 CoT 추론과 작업에 관련된 도구를 결합합니다. LLM은 도구 이름 목록, 유틸리티 설명 및 예상 입력/출력에 대한 세부 정보를 제공받습니다. 그런 다음 필요한 경우 도구를 사용하여 사용자가 제공한 프롬프트에 답변하도록 지시됩니다. 지시는 ReAct 형식을 따르도록 모델에게 알려줍니다 - 생각, 동작, 동작 입력, 관찰. 하지만 LLM을 사용하여 도메인 전문성이 필요한 작업의 성능을 평가할 때, LLM 기반 평가와 전문가 평가의 결과가 다를 수 있습니다. 이는 LLM이 자체적으로 도메인 전문성을 갖지 않기 때문에 발생하는 문제일 수 있습니다. 따라서 LLM을 사용하여 작업 결과의 정확성을 평가할 때는 주의가 필요합니다. 또한, 새로운 context에 따라서 "improve_code", "write_tests", "execute_python_file", "generate_image" 등의 작업을 수행할 수 있습니다. 이러한 작업은 LLM의 다양한 도구 사용 능력을 보여주는 예시입니다. 또한, Joon Sung Park 등은 "Generative Agents: Interactive Simulacra of Human Behavior"에서 인간 행동의 상호작용적인 시뮬라크인 생성 에이전트에 대해 연구하였습니다. AutoGPT와 GPT-Engineer는 ChatGPT를 개선하기 위한 프로젝트입니다. Prompt Engineering은 LLM의 성능을 향상시키기 위한 방법 중 하나입니다.
Reference
본 튜토리얼은 LangChain 튜토리얼 노트북 파일을 참조하여 작성하였습니다.
- 본 문서의 원 저작권자는 langchain-ai 이며, 코드는
MIT License에 따라 사용이 허가된 파일입니다. - 원문 바로가기
댓글남기기