🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
LangGraph Retrieval Agent를 활용한 동적 문서 검색 및 처리
LangGraph Retrieval Agent는 언어 처리, AI 모델 통합, 데이터베이스 관리, 그래프 기반 데이터 처리 등 다양한 기능을 제공하여 언어 기반 AI 애플리케이션 개발에 필수적인 도구입니다.
본 블로그에서는 LangGraph와 Retrieval Agent의 통합 과정, 구현 방법, 그리고 실제 사용 예시를 통해 이러한 도구들의 효과적인 활용 방법을 탐구합니다.
Python 코드를 중심으로 설명을 진행하며, 실제 구현 예시를 통해 문서 검색 및 처리의 전체 흐름을 이해할 수 있도록 구성되어 있습니다.
주요 내용
- 📚 LangGraph와 Retrieval Agent 소개: 언어 기반 AI 애플리케이션 개발에 필수적인 도구들의 기능과 중요성을 설명합니다.
- 🛠️ 구현 방법: Python을 활용한 LangGraph Retrieval Agent의 구현 과정을 단계별로 설명합니다.
- 🌐 실제 사용 예시: 동적 문서 검색 및 처리의 실제 사용 예시를 통해 LangGraph와 Retrieval Agent의 통합 사용 방법을 탐구합니다.
- 📝 고급 기능과 활용: 검색 에이전트의 고급 기능과 다양한 활용 방안을 소개합니다.
- 🔄 상태 기반 그래프 작업 흐름: 상태 기반 그래프를 사용하여 복잡한 결정과 작업의 흐름을 관리하는 방법을 설명합니다.
설치
다양한 언어 처리 및 AI 관련 라이브러리를 설치하는 명령어입니다. langchain_community, tiktoken, langchain-openai, langchainhub, chromadb, langchain, langgraph 등의 패키지를 포함합니다.
!pip install -qU langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph
API KEY를 로드합니다.
# api key
from dotenv import load_dotenv
load_dotenv()
True
LangGraph Retrieval Agent
검색 에이전트는 인덱스에서 검색할지 여부에 대한 결정을 내리고 싶을 때 유용합니다.
검색 에이전트를 구현하기 위해서는 LLM에 검색 도구에 대한 접근 권한을 제공하기만 하면 됩니다. 이를 LangGraph로 구현해 봅시다!
Retriever
첫 번째로, 3개의 블로그 게시물을 인덱싱합니다.
WebBaseLoader를 사용하여 주어진 URL 목록에서 문서를 로드합니다.RecursiveCharacterTextSplitter는 문서를 특정 크기의 청크로 분할하는 데 사용됩니다.- 분할된 문서는
Chroma벡터 저장소에 저장되며,OpenAIEmbeddings를 사용하여 임베딩됩니다. - 이후, 저장된 문서는 검색을 위해 검색기(
retriever)로 변환됩니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
# 벡터 데이터베이스에 문서 추가
vectorstore = Chroma.from_documents(
documents=doc_splits,
collection_name="rag-chroma",
embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()
LangChain의 create_retriever_tool 함수를 사용하여 특정 주제에 대한 블로그 게시물을 검색하고 정보를 반환하는 도구를 생성합니다. 이 예제에서는 Lilian Weng의 블로그 게시물 중 LLM 에이전트, 프롬프트 엔지니어링, LLM에 대한 적대적 공격에 관한 정보를 검색합니다.
생성된 도구는 ToolExecutor 클래스의 인스턴스에 등록되어 실행될 준비가 됩니다. ToolExecutor는 등록된 모든 도구를 관리하고 실행하는 역할을 담당합니다.
from langgraph.prebuilt import ToolExecutor
from langchain.tools.retriever import create_retriever_tool
# 릴리안 웡의 블로그 게시물에 대한 정보를 검색하고 반환하는 도구를 생성합니다.
tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"Search and return information about Lilian Weng blog posts on LLM agents, prompt engineering, and adversarial attacks on LLMs.",
)
tools = [tool]
# 도구들을 실행할 ToolExecutor 객체를 생성합니다.
tool_executor = ToolExecutor(tools)
Agent state
그래프를 정의해야 합니다.
AgentState는 각 노드에 전달하는state객체입니다.AgentState는messages의 리스트로 담깁니다.- 그런 다음 그래프의 각 노드는
AgentState를 추가합니다.
import operator
from typing import Annotated, Sequence, TypedDict
from langchain_core.messages import BaseMessage
class AgentState(TypedDict):
# AgentState 클래스는 메시지 시퀀스를 포함하는 타입 딕셔너리입니다.
messages: Annotated[Sequence[BaseMessage], operator.add]
노드와 엣지(Nodes and Edges)
우리는 agentic RAG 그래프를 다음과 같이 구성할 수 있습니다
-
상태는 메시지의 집합입니다
-
각 노드는 상태를 업데이트(추가)합니다
-
조건부 엣지는 다음에 방문할 노드를 결정합니다
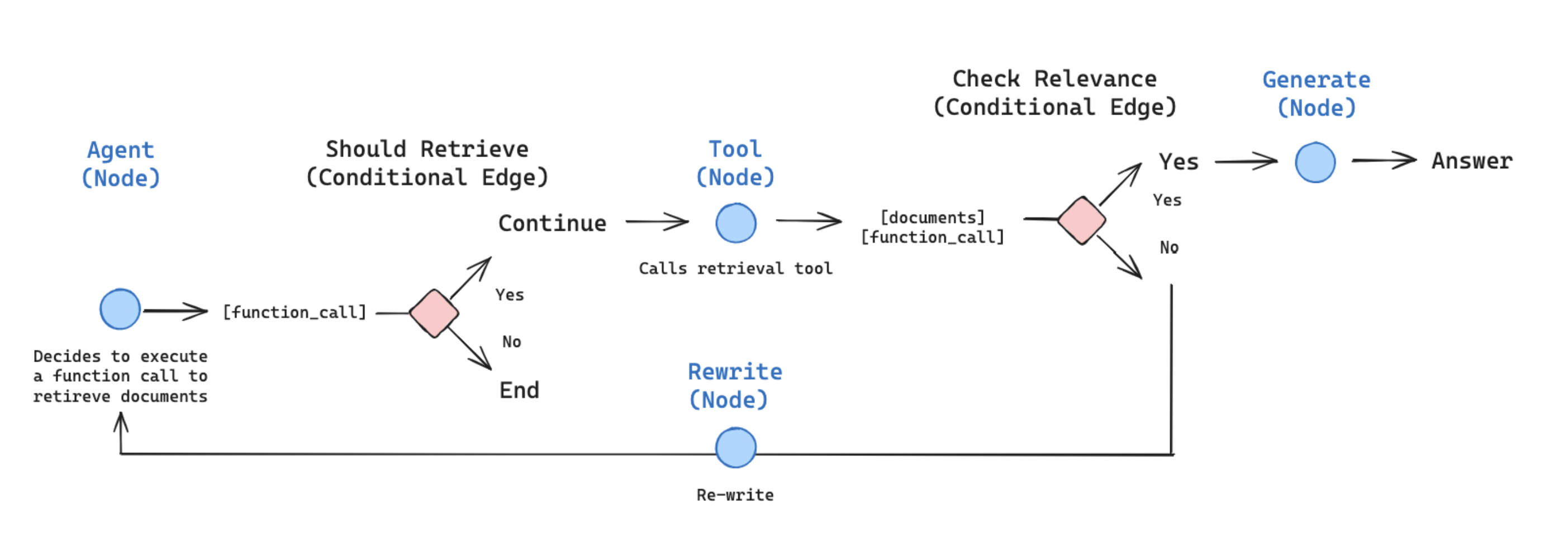
문서 검색, 관련성 평가, 질문 재구성, 그리고 답변 생성을 포함하는 정보 검색 및 처리 프로세스를 구현합니다.
- 첫 단계에서는 에이전트가 추가 정보를 검색해야 하는지 결정합니다(
should_retrieve). - 다음으로, 검색된 문서가 주어진 질문과 관련이 있는지 평가합니다(
grade_documents). - 이후, 질문을 재구성하여 더 나은 질문을 생성합니다(
rewrite). - 마지막으로, 최종적으로 검색된 문서를 바탕으로 답변을 생성합니다(
generate).
각 단계는 특정 입력에 따라 동작하며, 이 과정은 대화형 에이전트나 정보 검색 시스템에서 유용하게 사용될 수 있습니다.
import json
import operator
from typing import Annotated, Sequence, TypedDict
from langchain import hub
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.tools.render import format_tool_to_openai_function
from langchain_core.utils.function_calling import convert_to_openai_tool
from langchain_core.messages import BaseMessage, FunctionMessage
from langchain.output_parsers.openai_tools import PydanticToolsParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import ToolInvocation
from langchain_core.output_parsers import StrOutputParser
# Edges
def should_retrieve(state):
"""
에이전트가 더 많은 정보를 검색해야 하는지 또는 프로세스를 종료해야 하는지 결정합니다.
이 함수는 상태의 마지막 메시지에서 함수 호출을 확인합니다. 함수 호출이 있으면 정보 검색 프로세스를 계속합니다. 그렇지 않으면 프로세스를 종료합니다.
Args:
state (messages): 현재 상태
Returns:
str: 검색 프로세스를 "계속"하거나 "종료"하는 결정
"""
print("---DECIDE TO RETRIEVE---")
messages = state["messages"]
last_message = messages[-1]
# 함수 호출이 없으면 종료합니다.
if "function_call" not in last_message.additional_kwargs:
print("---DECISION: DO NOT RETRIEVE / DONE---")
return "end"
# 그렇지 않으면 함수 호출이 있으므로 계속합니다.
else:
print("---DECISION: RETRIEVE---")
return "continue"
def grade_documents(state):
"""
검색된 문서가 질문과 관련이 있는지 여부를 결정합니다.
Args:
state (messages): 현재 상태
Returns:
str: 문서가 관련이 있는지 여부에 대한 결정
"""
print("---CHECK RELEVANCE---")
# 데이터 모델
class grade(BaseModel):
"""관련성 검사를 위한 이진 점수."""
binary_score: str = Field(description="'yes' 또는 'no'의 관련성 점수")
# LLM
model = ChatOpenAI(
temperature=0, model="gpt-4-0125-preview", streaming=True)
# 도구
grade_tool_oai = convert_to_openai_tool(grade)
# 도구와 강제 호출을 사용한 LLM
llm_with_tool = model.bind(
tools=[convert_to_openai_tool(grade_tool_oai)],
tool_choice={"type": "function", "function": {"name": "grade"}},
)
# 파서
parser_tool = PydanticToolsParser(tools=[grade])
# 프롬프트
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
# 체인
chain = prompt | llm_with_tool | parser_tool
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
score = chain.invoke({"question": question, "context": docs})
grade = score[0].binary_score
if grade == "yes":
print("---DECISION: DOCS RELEVANT---")
return "yes"
else:
print("---DECISION: DOCS NOT RELEVANT---")
print(grade)
return "no"
# Nodes
def agent(state):
"""
현재 상태를 기반으로 에이전트 모델을 호출하여 응답을 생성합니다. 질문에 따라 검색 도구를 사용하여 검색을 결정하거나 단순히 종료합니다.
Args:
state (messages): 현재 상태
Returns:
dict: 메시지에 에이전트 응답이 추가된 업데이트된 상태
"""
print("---CALL AGENT---")
messages = state["messages"]
model = ChatOpenAI(temperature=0, streaming=True,
model="gpt-4-0125-preview")
functions = [format_tool_to_openai_function(t) for t in tools]
model = model.bind_functions(functions)
response = model.invoke(messages)
# 이것은 기존 목록에 추가될 것이므로 리스트를 반환합니다.
return {"messages": [response]}
def retrieve(state):
"""
도구를 사용하여 검색을 실행합니다.
Args:
state (messages): 현재 상태
Returns:
dict: 검색된 문서가 추가된 업데이트된 상태
"""
print("---EXECUTE RETRIEVAL---")
messages = state["messages"]
# 계속 조건을 기반으로 마지막 메시지가 함수 호출을 포함하고 있음을 알 수 있습니다.
last_message = messages[-1]
# 함수 호출에서 ToolInvocation을 구성합니다.
action = ToolInvocation(
tool=last_message.additional_kwargs["function_call"]["name"],
tool_input=json.loads(
last_message.additional_kwargs["function_call"]["arguments"]
),
)
# 도구 실행자를 호출하고 응답을 받습니다.
response = tool_executor.invoke(action)
function_message = FunctionMessage(content=str(response), name=action.tool)
# 이것은 기존 목록에 추가될 것이므로 리스트를 반환합니다.
return {"messages": [function_message]}
def rewrite(state):
"""
질문을 변형하여 더 나은 질문을 생성합니다.
Args:
state (messages): 현재 상태
Returns:
dict: 재구성된 질문이 추가된 업데이트된 상태
"""
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
# 평가자
model = ChatOpenAI(
temperature=0, model="gpt-4-0125-preview", streaming=True)
response = model.invoke(msg)
return {"messages": [response]}
def generate(state):
"""
답변 생성
Args:
state (messages): 현재 상태
Returns:
dict: 재구성된 질문이 추가된 업데이트된 상태
"""
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
# 프롬프트
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-4-turbo-preview",
temperature=0, streaming=True)
# 후처리
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 체인
rag_chain = prompt | llm | StrOutputParser()
# 실행
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
Graph
-
에이전트로 시작하며,
call_model -
에이전트는 함수를 호출할지 결정합니다
-
만약 호출한다면, 도구(검색기)를 호출하는
action을 수행합니다 -
그 다음 메시지(
state)에 도구의 출력을 추가하여 에이전트를 호출합니다
StateGraph 클래스는 상태 기반 그래프를 정의하고 관리하는 데 사용됩니다.
from langgraph.graph import END, StateGraph
# langgraph.graph에서 StateGraph와 END를 가져옵니다.
workflow = StateGraph(AgentState)
# 순환할 노드들을 정의합니다.
workflow.add_node("agent", agent) # 에이전트 노드를 추가합니다.
workflow.add_node("retrieve", retrieve) # 정보 검색 노드를 추가합니다.
workflow.add_node("rewrite", rewrite) # 정보 재작성 노드를 추가합니다.
workflow.add_node("generate", generate) # 정보 생성 노드를 추가합니다.
주어진 코드는 워크플로우를 설정하여 에이전트의 결정에 따라 문서를 검색하거나 다른 작업을 수행하는 과정을 정의합니다.
처음에는 agent 노드를 시작점으로 설정하고, 에이전트의 결정(should_retrieve)에 따라 retrieve 노드를 호출하거나 작업을 종료합니다.
retrieve 노드 이후에는 문서의 평가(grade_documents)를 통해 generate 또는 rewrite 작업을 결정하고, 각각의 경로를 따라 최종적으로 작업을 마무리하거나 에이전트로 돌아가는 과정을 포함합니다.
이 과정은 복잡한 결정과 작업의 흐름을 관리하는 데 사용될 수 있으며, 최종적으로 워크플로우를 컴파일하여 실행 가능한 애플리케이션을 생성합니다.
# 에이전트 노드 호출하여 검색 여부 결정
workflow.set_entry_point("agent")
# 검색 여부 결정
workflow.add_conditional_edges(
"agent",
# 에이전트 결정 평가
should_retrieve,
{
# 도구 노드 호출
"continue": "retrieve",
"end": END,
},
)
# `action` 노드 호출 후 진행될 경로
workflow.add_conditional_edges(
"retrieve",
# 에이전트 결정 평가
grade_documents,
{
"yes": "generate",
"no": "rewrite",
},
)
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# 컴파일
app = workflow.compile()
다음은 langchain_core.messages 모듈의 HumanMessage 클래스를 활용하여 사용자의 질문을 정의하고, app.stream 메소드를 통해 이 질문에 대한 응답을 스트리밍하는 과정을 보여줍니다.
import pprint
from langchain_core.messages import HumanMessage
# HumanMessage 객체를 사용하여 질문 메시지를 정의합니다.
inputs = {
"messages": [
HumanMessage(
content="What does Lilian Weng say about the types of agent memory?"
)
]
}
# app.stream을 통해 입력된 메시지에 대한 출력을 스트리밍합니다.
for output in app.stream(inputs):
# 출력된 결과에서 키와 값을 순회합니다.
for key, value in output.items():
# 노드의 이름과 해당 노드에서 나온 출력을 출력합니다.
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
# 출력 값을 예쁘게 출력합니다.
pprint.pprint(value, indent=2, width=80, depth=None)
# 각 출력 사이에 구분선을 추가합니다.
pprint.pprint("\n---\n")
---CALL AGENT---
"Output from node 'agent':"
'---'
{ 'messages': [ AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{"query":"types of agent memory"}', 'name': 'retrieve_blog_posts'}})]}
'\n---\n'
---DECIDE TO RETRIEVE---
---DECISION: RETRIEVE---
---EXECUTE RETRIEVAL---
"Output from node 'retrieve':"
'---'
{ 'messages': [ FunctionMessage(content='Table of Contents\n\n\n\nAgent System Overview\n\nComponent One: Planning\n\nTask Decomposition\n\nSelf-Reflection\n\n\nComponent Two: Memory\n\nTypes of Memory\n\nMaximum Inner Product Search (MIPS)\n\n\nComponent Three: Tool Use\n\nCase Studies\n\nScientific Discovery Agent\n\nGenerative Agents Simulation\n\nProof-of-Concept Examples\n\n\nChallenges\n\nCitation\n\nReferences\n\nPlanning\n\nSubgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.\nReflection and refinement: The agent can do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.\n\n\nMemory\n\nMemory\n\nShort-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe design of generative agents combines LLM with memory, planning and reflection mechanisms to enable agents to behave conditioned on past experience, as well as to interact with other agents.', name='retrieve_blog_posts')]}
'\n---\n'
---CHECK RELEVANCE---
---DECISION: DOCS RELEVANT---
---GENERATE---
"Output from node 'generate':"
'---'
{ 'messages': [ 'Lilian Weng discusses two types of agent memory: short-term '
'memory, which involves in-context learning and utilizes the '
"model's immediate memory to learn, and long-term memory, "
'which allows an agent to retain and recall information over '
'extended periods, often through the use of an external vector '
'store for fast retrieval.']}
'\n---\n'
"Output from node '__end__':"
'---'
{ 'messages': [ HumanMessage(content='What does Lilian Weng say about the types of agent memory?'),
AIMessage(content='', additional_kwargs={'function_call': {'arguments': '{"query":"types of agent memory"}', 'name': 'retrieve_blog_posts'}}),
FunctionMessage(content='Table of Contents\n\n\n\nAgent System Overview\n\nComponent One: Planning\n\nTask Decomposition\n\nSelf-Reflection\n\n\nComponent Two: Memory\n\nTypes of Memory\n\nMaximum Inner Product Search (MIPS)\n\n\nComponent Three: Tool Use\n\nCase Studies\n\nScientific Discovery Agent\n\nGenerative Agents Simulation\n\nProof-of-Concept Examples\n\n\nChallenges\n\nCitation\n\nReferences\n\nPlanning\n\nSubgoal and decomposition: The agent breaks down large tasks into smaller, manageable subgoals, enabling efficient handling of complex tasks.\nReflection and refinement: The agent can do self-criticism and self-reflection over past actions, learn from mistakes and refine them for future steps, thereby improving the quality of final results.\n\n\nMemory\n\nMemory\n\nShort-term memory: I would consider all the in-context learning (See Prompt Engineering) as utilizing short-term memory of the model to learn.\nLong-term memory: This provides the agent with the capability to retain and recall (infinite) information over extended periods, often by leveraging an external vector store and fast retrieval.\n\n\nTool use\n\nThe design of generative agents combines LLM with memory, planning and reflection mechanisms to enable agents to behave conditioned on past experience, as well as to interact with other agents.', name='retrieve_blog_posts'),
'Lilian Weng discusses two types of agent memory: short-term '
'memory, which involves in-context learning and utilizes the '
"model's immediate memory to learn, and long-term memory, "
'which allows an agent to retain and recall information over '
'extended periods, often through the use of an external vector '
'store for fast retrieval.']}
'\n---\n'
Reference
본 튜토리얼은 langchain-ai 튜토리얼 노트북 파일을 참조하여 작성하였습니다.
본 내용의 저작권은 2024년 테디노트(https://teddylee777.github.io)에 있습니다. 모든 권리는 저작권자에게 있으며, teddylee777@gmail.com으로 문의할 수 있습니다.
본 내용의 무단 전재 및 재배포를 금지합니다. 본 내용의 전체 혹은 일부를 인용할 경우, 출처를 명확히 밝혀주시기 바랍니다.
본 문서는 다른 문서의 내용을 참고하여 작성되었을 수 있습니다. 참고 자료는 본 문서 하단의 출처 목록에서 확인하실 수 있습니다.
- 본 문서의 원 저작권자는 langchain-ai 이며, 코드는
MIT License에 따라 사용이 허가된 파일입니다. - 원문 바로가기
댓글남기기