🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
캐글/데이콘 경진대회 Baseline을 잡기 위한 optuna + [xgboost, lightgbm, catboost] 패키지 소개
경진대회에서 모델의 Hyperparameter 튜닝에 드는 노력과 시간을 절약하기 위하여 xgboost, lightgbm, catboost 3개의 라이브러리에 대하여 optuna 튜닝을 적용하여 예측 값을 산출해 내는 로직을 라이브러리 형태로 패키징 했습니다.
경진대회 BASELINE을 잡기 위한 optuna + [xgboost, lightgbm, catboost]
지원하는 예측 종류는
- 회귀(regression)
- 이진분류(binary classification)
- 다중분류(multi-class classification)
입니다.
앞으로 라이브러리 개선작업을 통해 더 빠르게 최적화할 수 있도록 개선해 나갈 계획입니다.
설치
!pip install -U teddynote
# 모듈 import
from teddynote import models
샘플 데이터셋 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from sklearn.datasets import load_iris, load_boston, load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
import xgboost as xgb
import catboost as cb
from lightgbm import LGBMRegressor, LGBMClassifier
from xgboost import XGBRegressor, XGBClassifier
from catboost import CatBoostRegressor, CatBoostClassifier
warnings.filterwarnings('ignore')
SEED = 2021
# Binary Class Datasets
cancer = load_breast_cancer()
cancer_df = pd.DataFrame(cancer['data'], columns=cancer['feature_names'])
cancer_df['target'] = cancer['target']
cancer_df.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
5 rows × 31 columns
# Multi Class Datasets
iris = load_iris()
iris_df = pd.DataFrame(iris['data'], columns=iris['feature_names'])
iris_df['target'] = iris['target']
iris_df.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
# Regression Datasets
boston = load_boston()
boston_df = pd.DataFrame(boston['data'], columns=boston['feature_names'])
boston_df['target'] = boston['target']
boston_df.head()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
간단 사용법
optimize()
optimize(
x,
y,
test_data=None,
cat_features=None,
eval_metric='f1',
cv=5,
seed=None,
n_rounds=3000,
n_trials=100,
)
입력 매개변수
-
x: Feature 데이터 -
y: Target 데이터 -
test_data: 예측 데이터 (test 데이터의 feature 데이터) -
cat_features: 카테고리형 컬럼 -
eval_metric: 최적화할 메트릭 (‘f1’, ‘accuracy’, ‘recall’, ‘precision’, ‘mse’, ‘rmse’, ‘rmsle’) -
cv: cross validation fold 개수 -
seed: 시드 -
n_rounds: 학습시 최대 iteration 횟수 -
n_trials: optuna 하이퍼파라미터 튜닝 시도 횟수
return
-
params: best 하이퍼파라미터 -
preds:test_data매개변수에 데이터를 지정한 경우 이에 대한 예측 값
결과값 자동저장 기능
optimizer() 로 튜닝 + 예측한 결과는 numpy array 형식으로 자동 저장합니다.
- 저장 경로:
models폴더
CatBoost + Optuna
이진분류(binary classification)
catboostoptuna = models.CatBoostClassifierOptuna(use_gpu=False)
params, preds = catboostoptuna.optimize(iris_df.drop('target', 1),
iris_df['target'],
test_data=iris_df.drop('target', 1),
seed=321,
eval_metric='recall', n_trials=3)
(np.squeeze(preds) == iris_df['target']).mean()
다중분류(multi-class classification)
catboostoptuna = models.CatBoostClassifierOptuna()
params, preds = catboostoptuna.optimize(cancer_df.drop('target', 1),
cancer_df['target'],
test_data=cancer_df.drop('target', 1),
seed=321,
eval_metric='recall', n_trials=3)
(np.squeeze(preds) == cancer_df['target']).mean()
회귀(regression)
for col in ['CHAS', 'RAD', 'ZN']:
boston_df[col] = boston_df[col].astype('int')
catboostoptuna_reg = models.CatBoostRegressorOptuna(use_gpu=False)
params, preds = catboostoptuna_reg.optimize(boston_df.drop('target', 1),
boston_df['target'],
test_data=boston_df.drop('target', 1),
# int, str 타입 이어야 한다. float는 허용하지 않음
cat_features=['CHAS', 'RAD', 'ZN'],
eval_metric='rmse', n_trials=3)
mean_squared_error(boston_df['target'], preds)
저장한 파일로부터 예측 값 (prediction) 불러오기
# 넘파이 array로 저장된 예측 결과를 로드할 수 있습니다.
models.load_prediction_from_file('models/CatBoostRegressor-0.87226.npy')
array([28.76168717, 21.97469764, 33.91423778, 36.25317587, 34.89063327,
30.36592103, 21.62216055, 21.67925239, 16.13744104, 18.55325167,
19.19114681, 20.39200754, 20.4851822 , 20.18992755, 19.53332984,
19.95333642, 21.90489984, 17.43089179, 19.28067897, 18.75662987,
13.27196673, 17.43784243, 16.54706384, 14.6641719 , 15.98753177,
14.55392224, 16.07654144, 15.15717605, 18.46626451, 19.14277466,
13.42305337, 16.08031477, 13.88189742, 15.42776871, 13.93921857,
21.76392661, 20.96989226, 22.05468906, 23.01954988, 30.38238318,
35.86242058, 27.86047868, 24.46726054, 24.81965244, 21.93943212,
20.97466042, 19.40221015, 17.69406529, 14.9838815 , 18.13447461,
20.67717755, 22.8037252 , 27.00797342, 22.50247985, 18.38411847,
34.59829013, 25.66841753, 34.24698692, 23.25394891, 20.56548366,
18.08249006, 15.98063826, 23.92861079, 24.18700647, 31.40892682,
25.84846134, 19.79075001, 20.42532382, 18.62746158, 20.80022091,
23.33964199, 21.12974915, 22.61460761, 23.59166397, 23.77889816,
22.56759439, 20.36601319, 21.90976033, 20.22201645, 20.79508199,
26.11453205, 23.92772329, 24.00113404, 22.73930675, 23.72290053,
26.13084916, 21.3290855 , 24.25999642, 28.84149579, 30.07779444,
25.15881721, 25.06305693, 23.06077441, 24.28432971, 20.45356778,
27.53869606, 25.76019718, 39.81858701, 41.84946703, 34.55262548,
24.02980442, 25.65445863, 20.71075989, 20.2305375 , 19.82863103,
16.79407357, 17.75558312, 18.35677353, 19.65660082, 18.0508654 ,
21.5689087 , 23.06746945, 18.09671889, 18.42912872, 21.51601955,
17.52104662, 21.19149237, 21.53741825, 18.60982263, 19.8353869 ,
21.78394929, 20.82479114, 19.52986522, 16.34316023, 19.12320234,
20.51817182, 15.84022485, 14.82196509, 17.39604813, 15.71638676,
19.23800906, 19.38498764, 20.40981153, 17.61717099, 15.42971604,
17.70507511, 16.60916137, 18.13055393, 12.97506937, 16.57567281,
15.20248486, 14.23643501, 13.36728264, 14.72898506, 13.55049322,
14.9755267 , 16.03064387, 14.98655171, 15.15773699, 15.42038297,
19.80594139, 18.72855912, 16.47855863, 16.13431554, 17.39118588,
18.95159967, 16.80484215, 36.44802584, 27.31847993, 24.42104749,
33.32831742, 48.17558575, 48.10500758, 50.10220898, 21.6445183 ,
24.25216144, 46.87931622, 22.3243491 , 23.54260782, 23.23930775,
20.11795752, 20.55089244, 21.96288645, 25.19124179, 23.64260695,
28.62909465, 24.51323548, 24.80628451, 30.42589992, 37.3450949 ,
38.4181347 , 30.23559046, 38.05903337, 31.71650322, 26.26537372,
28.50830185, 45.52756479, 30.25326372, 30.14612204, 32.84831893,
29.96189048, 29.83769357, 35.86649294, 31.06581569, 29.52652706,
47.51160949, 36.3245743 , 29.81679975, 33.0799321 , 32.54773576,
34.19546892, 25.76115073, 41.09042432, 48.59485047, 48.31403964,
21.86601009, 22.41873571, 19.98276713, 23.41414041, 18.99296122,
20.94222734, 19.85599395, 22.46012421, 23.23118424, 22.33826844,
24.35427176, 22.84754784, 26.78443297, 22.02070077, 25.00887251,
29.11967995, 21.35142102, 28.4845406 , 28.13266249, 43.55809324,
43.92528527, 41.41070297, 33.03739803, 43.98911308, 34.88425066,
23.95836477, 35.73025736, 43.16032433, 43.04690079, 27.64386148,
24.70308422, 25.4884944 , 37.47134395, 24.75982658, 24.46682263,
24.01787678, 20.55522458, 21.81256414, 25.1210334 , 18.84767363,
18.65530061, 23.31803976, 20.90605542, 23.2340228 , 25.26291264,
24.24455301, 29.6144702 , 31.89752872, 40.56324634, 23.53199626,
19.96194628, 40.74456114, 48.1240842 , 36.47112068, 31.95761281,
35.22692603, 41.08284384, 43.59715004, 32.69785587, 38.395269 ,
29.9962736 , 31.91708957, 40.03140873, 46.20098888, 21.80400282,
20.18597404, 25.8267357 , 25.12578985, 35.62999617, 33.24609222,
32.1246326 , 32.1276531 , 33.20775978, 26.22963653, 35.73998533,
44.73786966, 36.20293923, 46.15322327, 50.76547855, 31.24164863,
24.72412287, 20.28457479, 22.92577672, 22.80344633, 23.12369478,
31.17422305, 35.1362746 , 26.74748661, 23.54393337, 22.04051644,
26.52810061, 25.09489421, 19.48346588, 26.88560752, 32.68850504,
27.88899813, 23.20912832, 24.87111363, 32.28653345, 33.91915569,
28.80376445, 35.01262449, 29.21634021, 25.79724389, 22.05887928,
21.3824104 , 23.18025825, 20.00625817, 23.00639761, 22.75589549,
17.94145995, 18.06389734, 18.02561674, 22.79710775, 20.21203719,
23.45896878, 23.04214565, 22.94954438, 18.56859949, 24.6756368 ,
25.56719479, 24.084167 , 20.2480269 , 20.91046936, 24.25174757,
21.23424581, 16.49834945, 19.66746909, 21.4557298 , 21.65723782,
20.06222367, 19.22627356, 18.87736706, 20.04211261, 19.71010834,
19.77379091, 32.5851722 , 24.65104583, 24.97530297, 30.10281989,
19.2971915 , 17.20332405, 23.85532316, 25.69790452, 26.13244964,
23.82816976, 24.07280403, 22.60158478, 31.12142614, 21.94114302,
23.35171169, 18.76796541, 18.91663659, 23.34380777, 20.45138255,
22.45630745, 17.74251749, 21.83864988, 18.43330579, 23.54134213,
26.68331628, 19.25077592, 22.754818 , 38.81018216, 49.26446287,
50.79271301, 39.70994055, 47.02221074, 12.5120863 , 13.44238312,
16.03211618, 14.14478663, 12.77288871, 11.2105293 , 12.32364567,
12.25072646, 10.34790415, 10.53523456, 10.7030971 , 11.42738056,
8.88825104, 9.34983733, 9.12203832, 11.97584357, 11.17106292,
14.56801675, 16.83874389, 10.02438036, 13.9523593 , 13.26336838,
13.90404049, 12.99194972, 11.10259056, 7.3404075 , 9.94517994,
7.68810727, 10.44760646, 12.67179266, 10.04602704, 9.2217173 ,
9.49584146, 18.29746443, 26.3683067 , 16.04251865, 20.71751946,
27.65855805, 16.86487185, 14.54875179, 15.70205646, 8.96022422,
9.18930385, 10.93764513, 9.52636606, 9.02340857, 9.99152837,
15.03190469, 14.90398513, 17.58508063, 13.3390705 , 13.65630505,
9.17099086, 13.15485696, 11.95532373, 11.0969807 , 10.75318325,
15.2116026 , 15.75387832, 18.8499195 , 14.90319747, 13.90606762,
11.24903563, 12.25064494, 10.36012359, 9.54165187, 11.81341828,
10.84391803, 13.36466617, 15.57695542, 14.26152587, 10.23491255,
10.70045996, 14.70878743, 14.79437752, 14.33805741, 13.99509979,
13.91139729, 15.20039866, 16.1576856 , 18.10186486, 13.92352322,
14.85029811, 14.2714253 , 15.14535685, 16.80094021, 18.69923671,
16.33460786, 17.54055978, 19.44845554, 20.11537833, 21.70623678,
19.35919475, 16.46347524, 15.96509858, 17.28791419, 19.37198404,
20.14604739, 20.67226853, 21.52497603, 22.75428627, 16.2353488 ,
15.04075596, 17.64296268, 13.079737 , 16.40755067, 20.24207015,
22.28444162, 23.89979801, 25.88883777, 21.55801563, 20.88892453,
22.86809854, 20.05936591, 21.45465288, 15.16904835, 9.95506956,
10.62074076, 14.6694633 , 19.00900648, 21.3145516 , 22.52886541,
21.62849666, 18.76080567, 21.24361604, 21.34419004, 18.83961699,
20.54947447, 21.35132386, 17.93859277, 23.9005454 , 22.68316054,
17.21506894])
하이퍼파라미터 튜닝 시각화
# 튜닝 결과 시각화
catboostoptuna_reg.visualize()
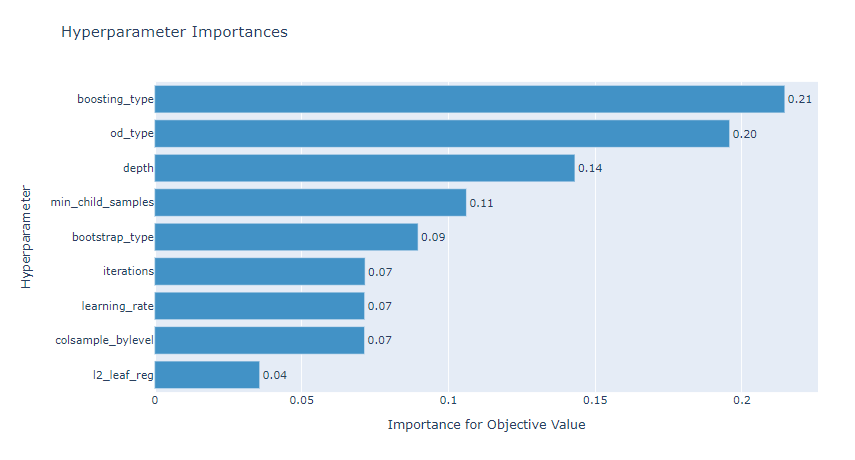
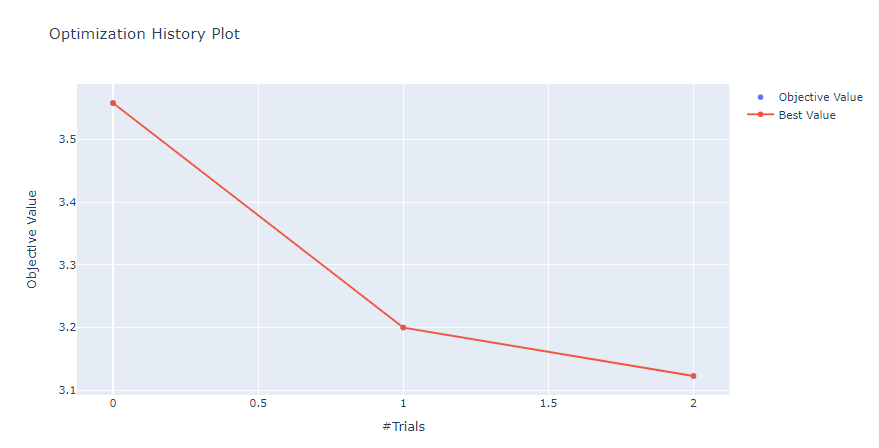
XGBoost
이진분류(binary classification)
xgboptuna = models.XGBClassifierOptuna(use_gpu=False)
params, preds = xgboptuna.optimize(iris_df.drop('target', 1),
iris_df['target'],
test_data=iris_df.drop('target', 1),
seed=321,
eval_metric='recall', n_trials=3)
(preds == iris_df['target']).mean()
다중분류(multi-class classification)
xgboptuna_binary = models.XGBClassifierOptuna(use_gpu=False)
params, preds = xgboptuna_binary.optimize(cancer_df.drop('target', 1),
cancer_df['target'],
test_data=cancer_df.drop('target', 1),
eval_metric='accuracy', n_trials=3)
(preds == cancer_df['target']).mean()
회귀(regression)
xgboptuna_reg = models.XGBRegressorOptuna()
params, preds = xgboptuna_reg.optimize(boston_df.drop('target', 1),
boston_df['target'],
test_data=boston_df.drop('target', 1),
eval_metric='mse', n_trials=3)
mean_squared_error(boston_df['target'], preds)
LGBM
이진분류(binary classification)
lgbmoptuna_binary = models.LGBMClassifierOptuna()
params, preds = lgbmoptuna_binary.optimize(cancer_df.drop('target', 1),
cancer_df['target'],
test_data=cancer_df.drop('target', 1),
eval_metric='accuracy', n_trials=3)
(preds == cancer_df['target']).mean()
다중분류(multi-class classification)
lgbmoptuna = models.LGBMClassifierOptuna()
params, preds = lgbmoptuna.optimize(iris_df.drop('target', 1),
iris_df['target'],
seed=321,
eval_metric='recall', n_trials=3)
(preds == iris_df['target']).mean()
회귀(regression)
lgbmoptuna_reg = models.LGBMRegressorOptuna()
params, preds = lgbmoptuna_reg.optimize(boston_df.drop('target', 1),
boston_df['target'],
test_data=boston_df.drop('target', 1),
eval_metric='mse', n_trials=3)
mean_squared_error(boston_df['target'], preds)
하이퍼파라미터 범위 수정 (custom)
lgbmoptuna = models.LGBMRegressorOptuna()
# 기본 값으로 설정된 하이퍼파라미터 출력
lgbmoptuna.print_params()
name: verbose, fixed_value: -1, type: fixed name: lambda_l1, low: 1e-08, high: 5, type: loguniform name: lambda_l2, low: 1e-08, high: 5, type: loguniform name: path_smooth, low: 1e-08, high: 0.001, type: loguniform name: learning_rate, low: 1e-05, high: 0.1, type: loguniform name: feature_fraction, low: 0.5, high: 0.9, type: uniform name: bagging_fraction, low: 0.5, high: 0.9, type: uniform name: num_leaves, low: 15, high: 90, type: int name: min_data_in_leaf, low: 10, high: 100, type: int name: max_bin, low: 100, high: 255, type: int name: n_estimators, low: 100, high: 3000, type: int name: bagging_freq, low: 0, high: 15, type: int name: min_child_weight, low: 1, high: 20, type: int
param_type에 관하여
param_type은 int, uniform, loguniform, categorical, fixed 가 있습니다.
int,uniform,loguniform은 optuna의 search range 정의하는 파라미터와 같습니다.
예시)
- int 범위(int)
lgbmoptuna.set_param(models.OptunaParam('num_leaves', low=10, high=25, param_type='int'))
- 카테고리(categorical)
cboptuna.set_param(models.OptunaParam('bootstrap_type', categorical_value=['Bayesian', 'Bernoulli', 'MVS'], param_type='categorical'))
- 고정된 값(fixed)
cboptuna.set_param(models.OptunaParam('one_hot_max_size', fixed_value=1024, param_type='fixed'))
# 하이퍼파라미터 범위 정의
lgbmoptuna.set_param(models.OptunaParam('num_leaves', low=10, high=25, param_type='int'))
lgbmoptuna.set_param(models.OptunaParam('n_estimators', low=0, high=500, param_type='int'))
# 출력
lgbmoptuna.print_params()
name: verbose, fixed_value: -1, type: fixed name: lambda_l1, low: 1e-08, high: 5, type: loguniform name: lambda_l2, low: 1e-08, high: 5, type: loguniform name: path_smooth, low: 1e-08, high: 0.001, type: loguniform name: learning_rate, low: 1e-05, high: 0.1, type: loguniform name: feature_fraction, low: 0.5, high: 0.9, type: uniform name: bagging_fraction, low: 0.5, high: 0.9, type: uniform name: num_leaves, low: 10, high: 25, type: int name: min_data_in_leaf, low: 10, high: 100, type: int name: max_bin, low: 100, high: 255, type: int name: n_estimators, low: 0, high: 500, type: int name: bagging_freq, low: 0, high: 15, type: int name: min_child_weight, low: 1, high: 20, type: int
# 달라진 결과값 확인
params, preds = lgbmoptuna.optimize(boston_df.drop('target', 1),
boston_df['target'],
test_data=boston_df.drop('target', 1),
eval_metric='mse', n_trials=3)
trial에 대한 결과를 출력합니다.
# trial에 대한 결과 출력
lgbmoptuna.study.trials_dataframe()
| number | value | datetime_start | datetime_complete | duration | params_bagging_fraction | params_bagging_freq | params_feature_fraction | params_lambda_l1 | params_lambda_l2 | params_learning_rate | params_max_bin | params_min_child_weight | params_min_data_in_leaf | params_n_estimators | params_num_leaves | params_path_smooth | state | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 83.529143 | 2021-12-31 07:26:21.337195 | 2021-12-31 07:26:24.492885 | 0 days 00:00:03.155690 | 0.508583 | 9 | 0.650294 | 6.415572e-07 | 4.982401e-02 | 0.000030 | 205 | 6 | 22 | 363 | 14 | 4.464380e-08 | COMPLETE |
| 1 | 1 | 82.696414 | 2021-12-31 07:26:24.494212 | 2021-12-31 07:26:26.673476 | 0 days 00:00:02.179264 | 0.712115 | 12 | 0.703372 | 4.705313e-08 | 6.194418e-08 | 0.000061 | 254 | 17 | 39 | 323 | 22 | 2.821343e-08 | COMPLETE |
| 2 | 2 | 20.680800 | 2021-12-31 07:26:26.674743 | 2021-12-31 07:26:28.133769 | 0 days 00:00:01.459026 | 0.857708 | 11 | 0.580214 | 1.124464e-02 | 5.298364e-06 | 0.091827 | 230 | 20 | 76 | 485 | 20 | 2.478903e-05 | COMPLETE |
하이퍼파라미터 튜닝 결과 시각화
lgbmoptuna.visualize()
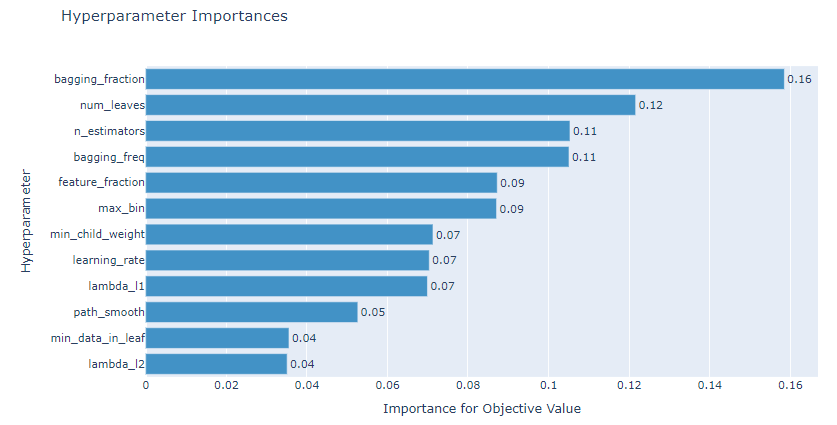
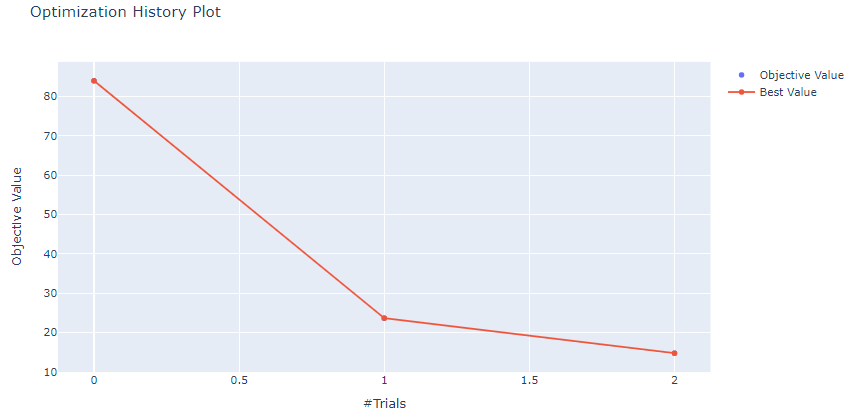
Best 하이퍼파라미터 출력
lgbmoptuna.get_best_params()
{'lambda_l1': 0.011244644026182967,
'lambda_l2': 5.298363992080463e-06,
'path_smooth': 2.4789027860002685e-05,
'learning_rate': 0.09182657994717408,
'feature_fraction': 0.5802144206891808,
'bagging_fraction': 0.8577082120277062,
'num_leaves': 20,
'min_data_in_leaf': 76,
'max_bin': 230,
'n_estimators': 485,
'bagging_freq': 11,
'min_child_weight': 20}
댓글남기기