🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
python의 pickle 기능을 활용하여 data를 저장하고 불러오는 방법
큰 용량의 dataset을 다루다 보면, 중간에 binary file 형태로 저장하고, 이를 나중에 불러와야하는 경우가 있습니다.
가령, Dataset을 불러와서 이리저리 merge하고 전처리를 열심히 했는데, jupyter notebook이 멈추거나, 컴퓨터가 갑자기 꺼지기라도 한다면, 전처리를 다시 수행해야하는데 데이터셋의 size가 작으면 상관없지만, size가 매우 큰 경우에는 전처리하는 시간이 상당히 오래걸립니다.
이때 유용하게 사용할 수 있는 python 라이브러리가 바로 pickle입니다.
Pickle 로 데이터 dump (저장) 하기
import pickle
save_data = { "name": "john", "color": "red" }
with open( "my_pickle", "wb" ) as file:
pickle.dump( save_data, file)
데이터 불러오기
with open( "my_pickle", "rb" ) as file:
loaded_data = pickle.load(file)
print(loaded_data)
# 출력: {'name': 'john', 'color': 'red'}
DataFrame도 저장하고 불러올 수 있습니다
import pandas as pd
import pickle
df = pd.DataFrame({'num_legs': [2, 4, 8, 0],
'num_wings': [2, 0, 0, 0],
'num_specimen_seen': [10, 2, 1, 8]},
index=['falcon', 'dog', 'spider', 'fish'])
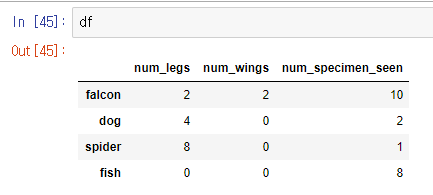
dataframe을 dump
with open( "my_dataframe", "wb" ) as file:
pickle.dump( df, file)
pickle로 load
with open( "my_dataframe", "rb" ) as file:
loaded_data = pickle.load(file)
load된 dataframe 출력
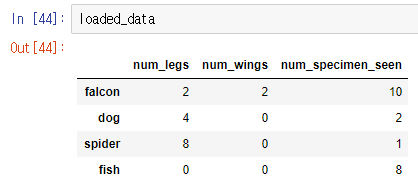
정상적으로 잘 출력된 모습을 확인하실 수 있습니다.
댓글남기기