🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
[pytorch] Seq2Seq with Attention 구현 및 한 줄씩 코드 설명
이번 포스팅에서는 Attention 메카니즘이 적용된 Seq2Seq 모델을 pytorch로 구현하고, 코드 한 줄씩 직접 shape를 찍어보고 확인하면서 구현된 코드 통해 동작 원리와 Attention 구조를 이해해 보도록 하겠습니다.
본 튜토리얼에서 활용한 한글 챗봇 데이터는 songys/Chatbot_data 를 활용하였습니다.
Attention을 적용하지 않은 Seq2Seq 모델 구조와 비교 해 보시는 것도 좋습니다. [pytorch] Seq2Seq 으로 챗봇 만들기 (코드 구현) 글을 참고해 주세요.
논문 링크
참고
실습코드
![]()
모듈 imports
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import random
import warnings
import time
import math
# Unicode warning 제거 (폰트 관련 경고메시지)
plt.rcParams['axes.unicode_minus']=False
# 한글 폰트 설정
plt.rcParams['font.family'] = "NanumGothic"
warnings.filterwarnings('ignore')
data_dir = 'data'
df = pd.read_csv(os.path.join(data_dir, 'ChatbotData.csv'))
df
| Q | A | label | |
|---|---|---|---|
| 0 | 12시 땡! | 하루가 또 가네요. | 0 |
| 1 | 1지망 학교 떨어졌어 | 위로해 드립니다. | 0 |
| 2 | 3박4일 놀러가고 싶다 | 여행은 언제나 좋죠. | 0 |
| 3 | 3박4일 정도 놀러가고 싶다 | 여행은 언제나 좋죠. | 0 |
| 4 | PPL 심하네 | 눈살이 찌푸려지죠. | 0 |
| ... | ... | ... | ... |
| 11818 | 훔쳐보는 것도 눈치 보임. | 티가 나니까 눈치가 보이는 거죠! | 2 |
| 11819 | 훔쳐보는 것도 눈치 보임. | 훔쳐보는 거 티나나봐요. | 2 |
| 11820 | 흑기사 해주는 짝남. | 설렜겠어요. | 2 |
| 11821 | 힘든 연애 좋은 연애라는게 무슨 차이일까? | 잘 헤어질 수 있는 사이 여부인 거 같아요. | 2 |
| 11822 | 힘들어서 결혼할까봐 | 도피성 결혼은 하지 않길 바라요. | 2 |
11823 rows × 3 columns
question = df['Q']
answer = df['A']
question[:5]
0 12시 땡! 1 1지망 학교 떨어졌어 2 3박4일 놀러가고 싶다 3 3박4일 정도 놀러가고 싶다 4 PPL 심하네 Name: Q, dtype: object
answer[:5]
0 하루가 또 가네요. 1 위로해 드립니다. 2 여행은 언제나 좋죠. 3 여행은 언제나 좋죠. 4 눈살이 찌푸려지죠. Name: A, dtype: object
1. 데이터 전처리
1-1. 한글 정규화
import re
# 한글, 영어, 숫자, 공백, ?!.,을 제외한 나머지 문자 제거
korean_pattern = r'[^ ?,.!A-Za-z0-9가-힣+]'
# 패턴 컴파일
normalizer = re.compile(korean_pattern)
normalizer
re.compile(r'[^ ?,.!A-Za-z0-9가-힣+]', re.UNICODE)
print(f'수정 전: {question[10]}')
print(f'수정 후: {normalizer.sub("", question[10])}')
수정 전: SNS보면 나만 빼고 다 행복해보여 수정 후: SNS보면 나만 빼고 다 행복해보여
print(f'수정 전: {answer[10]}')
print(f'수정 후: {normalizer.sub("", answer[10])}')
수정 전: 자랑하는 자리니까요. 수정 후: 자랑하는 자리니까요.
def normalize(sentence):
return normalizer.sub("", sentence)
normalize(question[10])
'SNS보면 나만 빼고 다 행복해보여'
1-2. 한글 형태소 분석기
from konlpy.tag import Mecab, Okt
# 형태소 분석기
mecab = Mecab()
okt = Okt()
# mecab
mecab.morphs(normalize(question[10]))
['SNS', '보', '면', '나', '만', '빼', '고', '다', '행복', '해', '보여']
# okt
okt.morphs(normalize(answer[10]))
['자랑', '하는', '자리', '니까', '요', '.']
# 한글 전처리를 함수화
def clean_text(sentence, tagger):
sentence = normalize(sentence)
sentence = tagger.morphs(sentence)
sentence = ' '.join(sentence)
sentence = sentence.lower()
return sentence
# 한글
clean_text(question[10], okt)
'sns 보면 나 만 빼고 다 행복 해보여'
# 영어
clean_text(answer[10], okt)
'자랑 하는 자리 니까 요 .'
len(question), len(answer)
(11823, 11823)
questions = [clean_text(sent, okt) for sent in question.values[:1000]]
answers = [clean_text(sent, okt) for sent in answer.values[:1000]]
questions[:5]
['12시 땡 !', '1 지망 학교 떨어졌어', '3 박 4일 놀러 가고 싶다', '3 박 4일 정도 놀러 가고 싶다', 'ppl 심하네']
answers[:5]
['하루 가 또 가네요 .', '위로 해 드립니다 .', '여행 은 언제나 좋죠 .', '여행 은 언제나 좋죠 .', '눈살 이 찌푸려지죠 .']
1-3. 단어 사전 생성
import torch
import torch.nn as nn
from torch import optim
import torch.nn.functional as F
from torch.utils.data.dataset import Dataset
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
device(type='cuda', index=0)
class WordVocab():
def __init__(self):
SOS_TOKEN = 0
EOS_TOKEN = 1
UNKNOWN_TOKEN = 2
self.unknown_token = UNKNOWN_TOKEN
# 각 토큰 별 word count
self.word2count = {}
# word -> idx
self.word2index = {
'<SOS>': SOS_TOKEN,
'<EOS>': EOS_TOKEN,
'<UKN>': UNKNOWN_TOKEN,
}
# idx -> word
self.index2word = {
SOS_TOKEN: '<SOS>',
EOS_TOKEN: '<EOS>',
UNKNOWN_TOKEN: '<UKN>',
}
# total word counts
self.n_words = 3 # SOS, EOS, UNKNOWN 포함
def add_sentence(self, sentence):
for word in sentence.split(' '):
self.add_word(word)
def add_word(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.word2count[word] = 1
self.index2word[self.n_words] = word
self.n_words += 1
else:
self.word2count[word] += 1
def word_to_index(self, word):
if word in self.word2index:
return self.word2index[word]
else:
return self.unknown_token
def index_to_word(self, idx):
return self.index2word[idx]
questions[10]
'sns 보면 나 만 빼고 다 행복 해보여'
print(f'원문: {questions[10]}')
wordvocab = WordVocab()
wordvocab.add_sentence(questions[10])
print('==='*10)
print('단어사전')
print(wordvocab.word2index)
원문: sns 보면 나 만 빼고 다 행복 해보여
==============================
단어사전
{'<SOS>': 0, '<EOS>': 1, '<UKN>': 2, 'sns': 3, '보면': 4, '나': 5, '만': 6, '빼고': 7, '다': 8, '행복': 9, '해보여': 10}
1-4. 전처리 프로세스를 클래스화
-
데이터를 로드하고, 정규화 및 전처리, 토큰화를 진행합니다.
-
단어 사전을 생성하고 이에 따라, 시퀀스로 변환합니다.
from konlpy.tag import Mecab, Okt
class QADataset():
def __init__(self, csv_path, min_length=3, max_length=25):
data_dir = 'data'
# TOKEN 정의
self.SOS_TOKEN = 0 # SOS 토큰
self.EOS_TOKEN = 1 # EOS 토큰
self.tagger = Okt() # 형태소 분석기
self.max_length = max_length # 한 문장의 최대 길이 지정
# CSV 데이터 로드
df = pd.read_csv(os.path.join(data_dir, csv_path))
# 한글 정규화
korean_pattern = r'[^ ?,.!A-Za-z0-9가-힣+]'
self.normalizer = re.compile(korean_pattern)
# src: 질의, tgt: 답변
src_clean = []
tgt_clean = []
# 단어 사전 생성
wordvocab = WordVocab()
for _, row in df.iterrows():
src = row['Q']
tgt = row['A']
# 한글 전처리
src = self.clean_text(src)
tgt = self.clean_text(tgt)
if len(src.split()) > min_length and len(tgt.split()) > min_length:
# 최소 길이를 넘어가는 문장의 단어만 추가
wordvocab.add_sentence(src)
wordvocab.add_sentence(tgt)
src_clean.append(src)
tgt_clean.append(tgt)
self.srcs = src_clean
self.tgts = tgt_clean
self.wordvocab = wordvocab
def normalize(self, sentence):
# 정규표현식에 따른 한글 정규화
return self.normalizer.sub("", sentence)
def clean_text(self, sentence):
# 한글 정규화
sentence = self.normalize(sentence)
# 형태소 처리
sentence = self.tagger.morphs(sentence)
sentence = ' '.join(sentence)
sentence = sentence.lower()
return sentence
def texts_to_sequences(self, sentence):
# 문장 -> 시퀀스로 변환
sequences = [self.wordvocab.word_to_index(w) for w in sentence.split()]
# 문장 최대 길이 -1 까지 슬라이싱
sequences = sequences[:self.max_length-1]
# 맨 마지막에 EOS TOKEN 추가
sequences.append(self.EOS_TOKEN)
return sequences
def sequences_to_texts(self, sequences):
# 시퀀스 -> 문장으로 변환
sentences = [self.wordvocab.index_to_word(s.item()) for s in sequences]
return ' '.join(sentences)
def __getitem__(self, idx):
inputs = self.srcs[idx]
inputs_sequences = self.texts_to_sequences(inputs)
outputs = self.tgts[idx]
outputs_sequences = self.texts_to_sequences(outputs)
return torch.tensor(inputs_sequences).view(-1, 1), torch.tensor(outputs_sequences).view(-1, 1)
def __len__(self):
return len(self.srcs)
# 한 문장의 최대 단어길이를 25로 설정
MAX_LENGTH = 25
dataset = QADataset('ChatbotData.csv', min_length=3, max_length=MAX_LENGTH)
# 3번 index 데이터셋 조회
# 결과: x(입력 데이터), y(출력 데이터)
dataset[3]
(tensor([[22],
[23],
[24],
[25],
[ 1]]),
tensor([[26],
[27],
[28],
[29],
[30],
[31],
[10],
[ 1]]))
x, y = dataset[3]
# 시퀀스를 문장으로 변환
print(dataset.sequences_to_texts(x))
print(dataset.sequences_to_texts(y))
sd 카드 안 돼 <EOS>
다시 새로 사는 게 마음 편해요 . <EOS>
2. Encoder
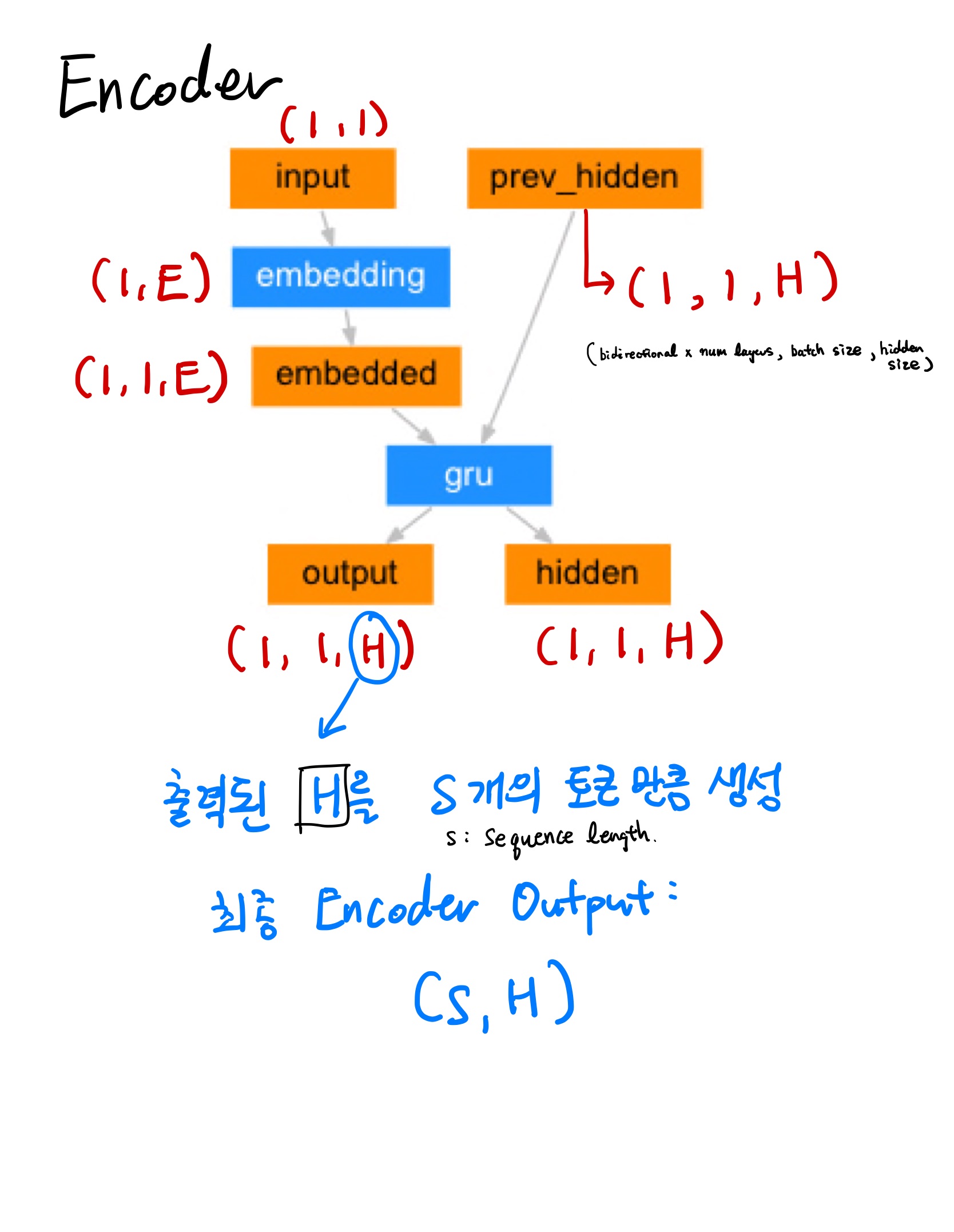
class Encoder(nn.Module):
def __init__(self, num_vocabs, hidden_size, embedding_dim, num_layers):
super(Encoder, self).__init__()
# 단어 사전의 개수 지정
self.num_vocabs = num_vocabs
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
# 임베딩 레이어 정의 (number of vocabs, embedding dimension)
self.embedding = nn.Embedding(num_vocabs, embedding_dim)
# GRU (embedding dimension)
self.gru = nn.GRU(embedding_dim,
hidden_size,
num_layers=num_layers,
bidirectional=False,
batch_first=True,
)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
# x: (1, 1, embedding_dim)
# hidden: (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32))
output, hidden = self.gru(x, hidden)
# output: (batch_size, sequence_length, hidden_size(32) x bidirectional(1))
# hidden: (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32))
return output, hidden
def init_hidden(self, device):
# hidden_state: (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32)) 로 초기화
return torch.zeros(1, 1, self.hidden_size, device=device)
- Embedding Layer
# x, y 추출
x, y = dataset[0]
embedding_dim = 20 # 임베딩 차원
embedding = nn.Embedding(dataset.wordvocab.n_words, embedding_dim)
embedded = embedding(x[0])
print(x.shape)
print(embedded.view(1, 1, -1).shape)
# input: (sequence_length, 1)
# output: (1, 1, embedding_dim)
torch.Size([5, 1]) torch.Size([1, 1, 20])
- GRU Layer
embedding_dim = 20 # 임베딩 차원
hidden_size = 32 # GRU hidden_size
gru = nn.GRU(embedding_dim,
hidden_size,
num_layers=1,
bidirectional=False)
o, h = gru(embedded.view(1, 1, -1))
print(o.shape)
# output : (batch_size, sequence_length, hidden_size(32) x bidirectional(1))
print(h.shape)
# hidden_state: (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32))
torch.Size([1, 1, 32]) torch.Size([1, 1, 32])
- Encoder
NUM_VOCABS = dataset.wordvocab.n_words
print(f'number of vocabs: {NUM_VOCABS}')
number of vocabs: 10548
# Encoder 정의
encoder = Encoder(NUM_VOCABS,
hidden_size=32,
embedding_dim=20,
num_layers=1)
# Encoder hidden_state 초기화
encoder.init_hidden(device=device).shape
torch.Size([1, 1, 32])
# Encoder에 x 통과 후 output, hidden_size 의 shape 확인
encoder_out, encoder_hidden = encoder(x[0], torch.zeros_like(encoder.init_hidden(device='cpu')))
print(encoder_out.shape)
print(encoder_hidden.shape)
# output : (batch_size, sequence_length, hidden_size(32) x bidirectional(1))
# hidden_state: (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32))
torch.Size([1, 1, 32]) torch.Size([1, 1, 32])
3. Attention 이 적용된 Decoder
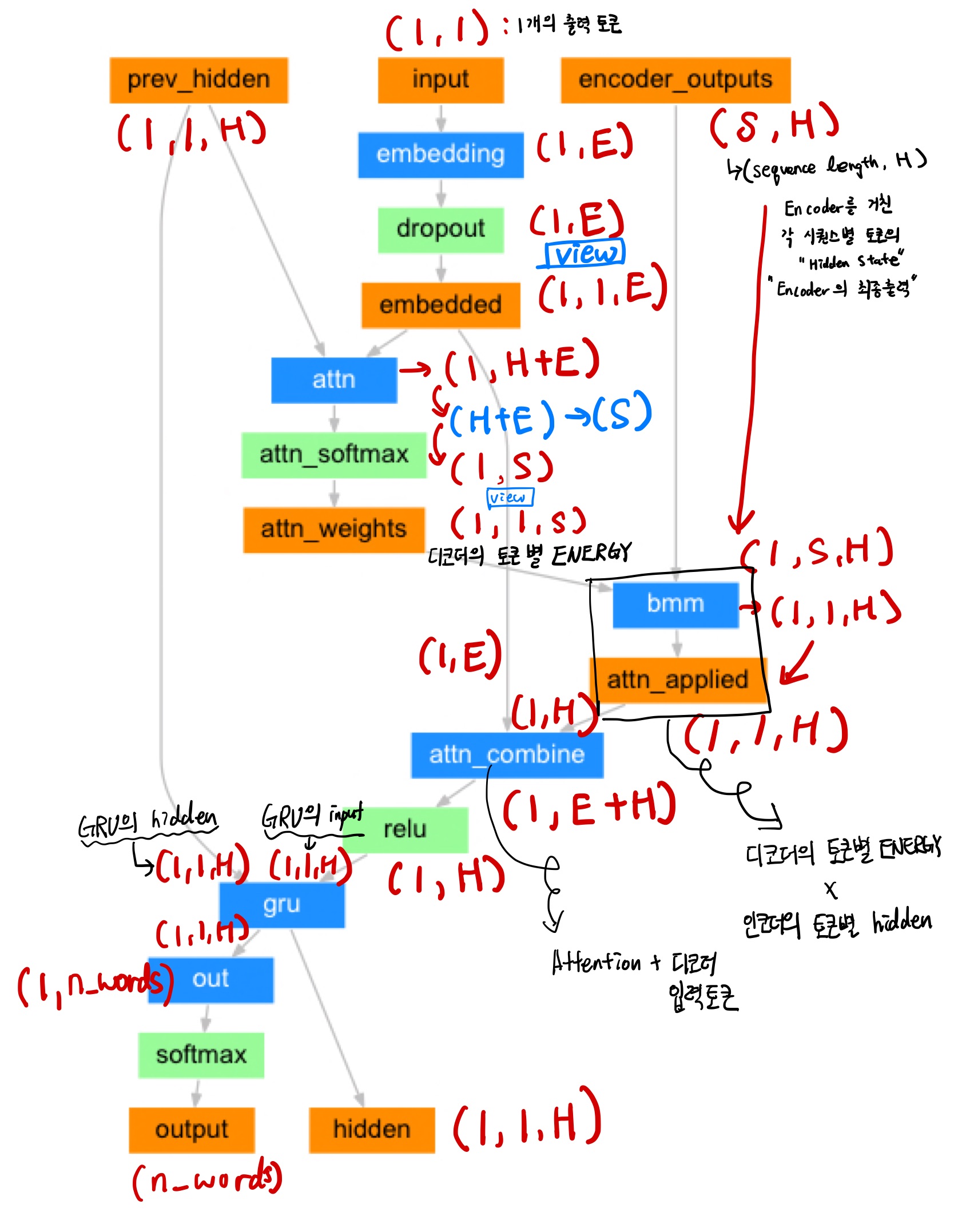
class AttentionDecoder(nn.Module):
def __init__(self, num_vocabs, hidden_size, embedding_dim, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttentionDecoder, self).__init__()
self.hidden_size = hidden_size
self.max_length = max_length
self.embedding = nn.Embedding(num_vocabs, embedding_dim)
self.attn = nn.Linear(hidden_size + embedding_dim , max_length)
self.attn_combine = nn.Linear(hidden_size + embedding_dim, hidden_size)
self.dropout = nn.Dropout(dropout_p)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, num_vocabs)
def forward(self, x, hidden, encoder_outputs):
# x: (1, 1) 1개의 토큰
embedded = self.embedding(x).view(1, 1, -1)
# embedded: (1, 1, 1)
embedded = self.dropout(embedded)
# embedded[0]: (1, embedding_dim)
# hidden[0]: (1, hidden_size)
attn_in = torch.cat((embedded[0], hidden[0]), 1)
# attn_in: (1, embedding_dim + hidden_size)
attn = self.attn(attn_in)
# attn: (1, max_length)
attn_weights = F.softmax(attn)
# attn_weights: (1, max_length)
# (1, 1, max_length), (1, max_length, hidden_size)
attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
# attn_applied: (1, 1, hidden_size)
# embedded[0]: (1, embedding_dim)
# attn_applied[0]: (1, hidden_size)
output = torch.cat((embedded[0], attn_applied[0]), 1)
# output: (1, embedding_dim + hidden_size)
output = self.attn_combine(output)
# output: (1, hidden_size)
output = output.unsqueeze(0)
# output: (1, 1, hidden_size)
output = F.relu(output)
# output: (1, 1, hidden_size)
# output: (1, 1, hidden_size)
# hidden: (1, 1, hidden_size)
output, hidden = self.gru(output, hidden)
# output: (1, 1, hidden_size)
# hidden: (1, 1, hidden_size)
# output[0]: (1, hidden_size)
output = self.out(output[0])
# output: (1, number of vocabs)
# output[0]: (number of vocabs)
# hidden: (1, 1, hidden_size)
# attn_weights: (1, max_length)
return output[0], hidden, attn_weights
def initHidden(self, device):
# (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32))
return torch.zeros(1, 1, self.hidden_size, device=device)
# 디코더 문장의 길이가 12 단어라고 가정한 경우
x = torch.abs(torch.randn(size=(12, 1)).long())
x.shape
torch.Size([12, 1])
- 디코더의 단어 1개에 대한 Embedding
embedding_dim = 20
embedding = nn.Embedding(wordvocab.n_words, embedding_dim)
# Decoder의 단어 1개: x[0]를 입력으로 가짐
embedded = embedding(x[0])
print(embedded.shape)
# (1, 20)
embedded = embedded.view(1, 1, -1)
# (1, 1, 20)
print(embedded.shape)
torch.Size([1, 20]) torch.Size([1, 1, 20])
- 드롭아웃 적용
# dropout 적용
dropout = nn.Dropout(0.1)
embedded = dropout(embedded)
embedded.shape
torch.Size([1, 1, 20])
-
디코더의 첫 번째 단어는 Encoder
hidden_state를 사용 -
두 번째 단어부터는 이전 단계의 Decoder
hidden_state를 사용 -
디코드의 현재 입력 Embedding + (Encoder
hidden_stateor Decoder 이전 단계의hidden_state)를 concat -
결과는
(1, E + H)
# 첫 단어는 encoder_hidden 사용, 두 번째 단어부터는 decoder_hidden 사용
# encoder_hidden.shape == decoder_hidden.shape 같아야 함
# hidden.shape: (1, 1, H)
hidden = encoder_hidden
print(hidden[0].shape)
print(embedded[0].shape)
torch.Size([1, 32]) torch.Size([1, 20])
# 디코드의 현재 입력 Embedding + (Encoder hidden_state or Decoder 이전 단계의 hidden_state)를 concat
context = torch.cat((embedded[0], hidden[0]), 1)
context.shape
torch.Size([1, 52])
-
attention 생성
-
FC 레이어: (1, E+H) -> (1, MAX_LENGTH)
# (1, E+H) -> (1, MAX_LENGTH)
fc = nn.Linear(hidden_size+embedding_dim, MAX_LENGTH)
attn = fc(context)
print(attn.shape)
torch.Size([1, 25])
attn_weights = F.softmax(attn, dim=1)
# attn weights: (1, MAX_LENGTH)
print('변경 전:', attn_weights.shape)
# (1, MAX_LENGTH) -> (1, 1, MAX_LENGTH)
attn_weights = attn_weights.unsqueeze(0)
print('변경 후:', attn_weights.shape)
변경 전: torch.Size([1, 25]) 변경 후: torch.Size([1, 1, 25])
# Encoder의 시퀀스 별 H가 모두 채워진 Matrix
encoder_outputs = torch.zeros(MAX_LENGTH, hidden_size)
# (MAX_LENGTH, H)
print('변경 전:', encoder_outputs.shape)
encoder_outputs = encoder_outputs.unsqueeze(0)
# (1, MAX_LENGTH, H)
print('변경 후', encoder_outputs.shape)
변경 전: torch.Size([25, 32]) 변경 후 torch.Size([1, 25, 32])
-
attention weights: 현재의 디코더 입력 (1개 단어)와 이전 단계의 hidden_state 사이에서 구한 Energy -
encoder outputs: 인코더의 전체 문장 출력 (MAX_LENGTH, hidden_size)로 이루어짐. -
attention weights와encoder outputs간의 Attention BMM을 산출
# BMM: (1, 1, MAX_LENGTH) x (1, MAX_LENGTH, H) => (1, 1, H)
# BMM 적용 후: (1, 1, H)
attn_applied = torch.bmm(attn_weights, encoder_outputs)
attn_applied.shape
torch.Size([1, 1, 32])
-
디코더의 현재 입력 (1개 단어)와 Attention 값을 concat
-
(1, E) + (1, H) = (1, E+H)
-
FC: (1, E+H) -> (1, H)
output = torch.cat((embedded[0], attn_applied[0]), 1)
# (1, E+H)
print('concat 결과 : ', output.shape)
fc = nn.Linear(hidden_size+embedding_dim, hidden_size)
output = fc(output)
# (1, H)
print('FC 통과 후 : ', output.shape)
# GRU 입력으로 넣기 위하여 (1, H) -> (1, 1, H)
output = output.unsqueeze(0)
print('unsqueeze 후: ', output.shape)
concat 결과 : torch.Size([1, 52]) FC 통과 후 : torch.Size([1, 32]) unsqueeze 후: torch.Size([1, 1, 32])
-
output을 ReLU 통과
-
GRU의 입력으로 output, hidden 주입
-
output: (1, 1, H), hidden: (1, 1, H)
output = F.relu(output)
gru = nn.GRU(hidden_size, hidden_size)
output, hidden = gru(output, hidden)
output.shape, hidden.shape
(torch.Size([1, 1, 32]), torch.Size([1, 1, 32]))
-
output: (1, 1, 32) -> (1, 32)
-
output을 최종 출력으로 변경: (1, number of vocabs)
# (1, H) -> (1, number of vocabs)
out = nn.Linear(hidden_size, dataset.wordvocab.n_words)
decoder_out = out(output[0])
# (1, number of vocabs)
decoder_out.shape
torch.Size([1, 10548])
- attention 디코더 입출력 확인
# 입력 문장의 길이가 12 단어라고 가정한 경우
# x: 12개의 토큰으로 이루어진 입력 문장이라고 가정
x = torch.abs(torch.randn(size=(12, 1)).long())
x.shape
torch.Size([12, 1])
encoder_outputs = torch.zeros(MAX_LENGTH, encoder.hidden_size)
# (max_length, hidden_size)
encoder_outputs.shape
torch.Size([25, 32])
# (1, 1, hidden_size)
encoder_hidden.shape
torch.Size([1, 1, 32])
# Attention이 적용된 디코더 생성
decoder = AttentionDecoder(num_vocabs=NUM_VOCABS,
hidden_size=32,
embedding_dim=20,
dropout_p=0.1,
max_length=MAX_LENGTH)
# y[0]: 디코더의 입력으로 들어가는 1개 토큰
decoder_out, decoder_hidden, attn_weights = decoder(y[0], encoder_hidden, encoder_outputs)
# decoder_out: (number of vocabs)
# decoder_hidden: (1, 1, hidden_size)
# attn_weights: (1, max_length)
decoder_out.shape, decoder_hidden.shape, attn_weights.shape
(torch.Size([10548]), torch.Size([1, 1, 32]), torch.Size([1, 25]))
4. Training
SOS_TOKEN = dataset.SOS_TOKEN
EOS_TOKEN = dataset.EOS_TOKEN
# 훈련시 training loss 를 출력하기 위한 util 함수
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# 주기적인 간격에 이 locator가 tick을 설정
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points)
plt.title('Losses over training')
plt.show()
# 훈련시 시간 출력을 위한 util 함수
def as_minutes(s):
m = math.floor(s / 60)
s -= m * 60
return f'{int(m)}m {int(s)}s'
# 훈련시 시간 출력을 위한 util 함수
def time_since(since, percent):
now = time.time()
s = now - since
es = s / (percent)
rs = es - s
return f'{as_minutes(s)} (remaining: {as_minutes(rs)})'
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer,
decoder_optimizer, criterion, device, max_length=MAX_LENGTH, teacher_forcing_ratio=0.5):
# Encoder의 hidden_state 초기화
encoder_hidden = encoder.init_hidden(device=device)
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# input_length: 입력 문장의 길이
# target_length: 출력 문장의 길이
input_length = input_tensor.size(0)
target_length = target_tensor.size(0)
# Encoder의 출력 결과를 담을 tensor
# (문장의 max_length, encoder의 hidden_size)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
loss = 0
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
# Encoder의 출력을 encoder_outputs[ei] 에 저장
# encoder_output[0, 0]: (hidden_size,)
encoder_outputs[ei] = encoder_output[0, 0]
# Decoder의 첫 토큰은 SOS_TOKEN
decoder_input = torch.tensor([[SOS_TOKEN]], device=device)
# Encoder의 마지막 hidden state를 Decoder의 초기 hidden state로 지정
decoder_hidden = encoder_hidden
# teacher forcing 적용 여부 확률로 결정
# teacher forcing 이란: 정답치를 다음 RNN Cell의 입력으로 넣어주는 경우. 수렴속도가 빠를 수 있으나, 불안정할 수 있음
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)
# loss 계산
loss += criterion(decoder_output.view(1, -1), target_tensor[di])
if use_teacher_forcing:
# teacher forcing 적용: 정답 값 입력
decoder_input = target_tensor[di]
else:
# 확률, 인덱스
topv, topi = decoder_output.topk(1)
# 다음 입력으로 주입할 디코더 최종 토큰 결정
decoder_input = topi.squeeze().detach() # 입력으로 사용할 부분을 히스토리에서 분리
# EOS_TOKEN 이면 종료
if decoder_input.item() == EOS_TOKEN:
break
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
return loss.item() / target_length
def train_iterations(encoder, decoder, n_iters, dataset, device, print_every=1000, plot_every=100, learning_rate=0.001):
start = time.time()
plot_losses = []
print_loss_total = 0 # print_every 마다 초기화
plot_loss_total = 0 # plot_every 마다 초기화
encoder_optimizer = optim.Adam(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=learning_rate)
# 랜덤 샘플링된 데이터셋 생성
training_pairs = [dataset[random.randint(0, len(dataset)-1)] for i in range(n_iters)]
# Loss Function 정의
criterion = nn.CrossEntropyLoss()
# n_iters 만큼 training 시작
for iter in range(1, n_iters + 1):
# 문장 pair
training_pair = training_pairs[iter - 1]
# 입력 문장
input_tensor = training_pair[0]
# 출력 문장
target_tensor = training_pair[1]
input_tensor = input_tensor.to(device)
target_tensor = target_tensor.to(device)
# 훈련
loss = train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer,
decoder_optimizer, criterion, device)
print_loss_total += loss
plot_loss_total += loss
# print_every 마다 loss 출력
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print(f'{time_since(start, iter/n_iters)} iter: {iter} ({iter/n_iters*100:.1f}%), loss: {print_loss_avg:.4f}')
# plot_every 마다 loss 시각화
if iter % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every
plot_losses.append(plot_loss_avg)
plot_loss_total = 0
showPlot(plot_losses)
# Hyper-Parameter 정의
NUM_VOCABS = dataset.wordvocab.n_words
HIDDEN_SIZE = 512
EMBEDDING_DIM = 256
DROPOUT_P = 0.1
# Encoder 정의
encoder = Encoder(NUM_VOCABS,
hidden_size=HIDDEN_SIZE,
embedding_dim=EMBEDDING_DIM,
num_layers=1)
# Attention 이 적용된 Decoder 정의
decoder = AttentionDecoder(num_vocabs=NUM_VOCABS,
hidden_size=HIDDEN_SIZE,
embedding_dim=EMBEDDING_DIM,
dropout_p=DROPOUT_P,
max_length=MAX_LENGTH)
# encoder, decoder 생성 및 device 지정
encoder = encoder.to(device)
decoder = decoder.to(device)
train_iterations(encoder, decoder, 100000, dataset, device, print_every=5000)
1m 24s (remaining: 26m 52s) iter: 5000 (5.0%), loss: 4.8845 2m 34s (remaining: 23m 9s) iter: 10000 (10.0%), loss: 4.0157 3m 45s (remaining: 21m 18s) iter: 15000 (15.0%), loss: 3.4559 4m 58s (remaining: 19m 54s) iter: 20000 (20.0%), loss: 3.1542 6m 9s (remaining: 18m 28s) iter: 25000 (25.0%), loss: 2.9211 7m 21s (remaining: 17m 9s) iter: 30000 (30.0%), loss: 2.8129 8m 32s (remaining: 15m 51s) iter: 35000 (35.0%), loss: 2.6756 9m 45s (remaining: 14m 38s) iter: 40000 (40.0%), loss: 2.5733 10m 50s (remaining: 13m 14s) iter: 45000 (45.0%), loss: 2.5347 11m 54s (remaining: 11m 54s) iter: 50000 (50.0%), loss: 2.4623 13m 0s (remaining: 10m 38s) iter: 55000 (55.0%), loss: 2.4422 14m 5s (remaining: 9m 23s) iter: 60000 (60.0%), loss: 2.3936 15m 9s (remaining: 8m 9s) iter: 65000 (65.0%), loss: 2.2880 16m 14s (remaining: 6m 57s) iter: 70000 (70.0%), loss: 2.2630 17m 21s (remaining: 5m 47s) iter: 75000 (75.0%), loss: 2.2305 18m 28s (remaining: 4m 37s) iter: 80000 (80.0%), loss: 2.2141 19m 34s (remaining: 3m 27s) iter: 85000 (85.0%), loss: 2.2107 20m 40s (remaining: 2m 17s) iter: 90000 (90.0%), loss: 2.1225 21m 45s (remaining: 1m 8s) iter: 95000 (95.0%), loss: 2.1499 22m 51s (remaining: 0m 0s) iter: 100000 (100.0%), loss: 2.0816

5. Evaluation
def evaluate(encoder, decoder, input_tensor, dataset, device, max_length=MAX_LENGTH):
# Eval 모드 설정
encoder.eval()
decoder.eval()
with torch.no_grad():
input_length = input_tensor.size(0)
# Encoder의 hidden state 초기화
encoder_hidden = encoder.init_hidden(device=device)
# encoder_outputs는 Encoder를 통과한 문장의 출력
# (max_length, hidden_size)
encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)
# Encoder 에 입력 문자 주입 후 encoder_outputs 생성
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)
encoder_outputs[ei] += encoder_output[0, 0]
# Decoder의 첫 번째 입력으로 SOS_TOKEN 입력(SOS_TOKEN=0)
decoder_input = torch.tensor([[0]], device=device)
# Decoder의 첫 번째 hidden state는 Encoder의 마지막 hidden state 사용
decoder_hidden = encoder_hidden
decoded_words = []
decoder_attentions = torch.zeros(max_length, max_length)
for di in range(max_length):
# 1개의 Decoder 입력 토큰을 통과
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)
# Attention 시각화를 위한 tensor 저장
decoder_attentions[di] = decoder_attention.data
# 출력 토큰 예측
topv, topi = decoder_output.data.topk(1)
# EOS_TOKEN이면 종료
if topi.item() == dataset.EOS_TOKEN:
decoded_words.append('<EOS>')
break
else:
# 출력 문장에 토큰 시퀀스(index)를 단어(word)로 변환한 후 저장
decoded_words.append(dataset.wordvocab.index_to_word(topi.item()))
# decoder_input은 다음 토큰 예측시 입력 값
# decoder_input: (hidden_size,)
decoder_input = topi.squeeze().detach()
return decoded_words, decoder_attentions[:di + 1]
def evaluate_randomly(encoder, decoder, dataset, device, n=10):
for i in range(n):
# 랜덤 샘플링
x, y = random.choice(dataset)
# 입력 문장, 출력 문장 (Ground Truth)
print('>', dataset.sequences_to_texts(x))
print('=', dataset.sequences_to_texts(y))
# 예측
output_words, attentions = evaluate(encoder, decoder, x.to(device), dataset, device)
output_sentence = ' '.join(output_words)
# 예측 문장 출력
print('<', output_sentence)
print('')
# 랜덤 샘플링 된 데이터 evaluate
evaluate_randomly(encoder, decoder, dataset, device)
> 요즘 광고 가 너무 길어 <EOS>
= 채널 을 돌려 보세요 . <EOS>
< 잘 돌려 보세요 . <EOS>
> 대화 가 잘 통 하는 사람 이야 <EOS>
= 그런 사람 놓치지 마세요 . <EOS>
< 나쁜 사람 만들어 . <EOS>
> 나를 좋아하는 애 랑 친구 가능 ? <EOS>
= 그건 좀 힘들 것 같아요 . <EOS>
< 그럴 수도 오세요 . <EOS>
> 썸 인지 아닌지 알 수 있나 <EOS>
= 연락 하는 패턴 으로 가늠 해보세요 . <EOS>
< 그 사람 이 다가 마세요 . <EOS>
> 더워서 잠 을 못자 <EOS>
= 잠 이 최고 의 보약 이에요 . 노력 해보세요 . <EOS>
< 잠 이 최고 의 보약 이에요 . <EOS>
> 내 가 친절하니까 쉬워 보이 나 ? <EOS>
= 그런 사람 만나지 마세요 . <EOS>
< 당신 에 확신 에 하지 마세요 . <EOS>
> 서로 좋아하게 되는건 운명 같은 일 이었어 . <EOS>
= 운명 이자 기적 이 죠 . <EOS>
< 운명 기적 이 죠 . <EOS>
> 선풍기 가 있어도 소용 없어 <EOS>
= 시원한 아이스크림 어떠세요 ? <EOS>
< 시원한 아이스크림 ? <EOS>
> 보험료 설계 다시 해야 하나 ? <EOS>
= 재 설계 가 필요하다면 하는 게 좋을 것 같습니다 . <EOS>
< 재 설계 하는 게 좋을 건 좋을 것 같습니다 . <EOS>
> 자꾸 갠톡 하 는 선배 있는데 관심 있나 ? <EOS>
= 호감 이 있을 수도 있어요 . 그렇지만 조금 더 상황 을 지켜보세요 . <EOS>
< 호감 에서 있을 수도 있어요 . 그렇지만 조금 상황 이 더 상황 을 지켜보세요 . <EOS>
6. Attention 가중치 시각화
# Attention Weights를 활용한 시각화
output_words, attentions = evaluate(encoder, decoder, dataset[2][0].to(device), dataset, device)
plt.matshow(attentions.numpy())
plt.show()

# Attention 시각화를 위한 함수
def show_attention(input_sentence, output_words, attentions):
# colorbar로 그림 설정
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(attentions.numpy(), cmap='bone')
fig.colorbar(cax)
# 축 설정
ax.set_xticklabels([''] + input_sentence.split(' ') + ['<EOS>'], rotation=90)
ax.set_yticklabels([''] + output_words)
# 매 틱마다 라벨 보여주기
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()
def evaluate_and_show_attention(encoder, decoder, input_sentence, dataset, device):
output_words, attentions = evaluate(encoder, decoder, input_sentence.to(device), dataset, device)
input_sentence = dataset.sequences_to_texts(input_sentence)
output_words = ' '.join(output_words)
print('input =', input_sentence)
print('output =', output_words)
show_attention(input_sentence, output_words.split(), attentions)
evaluate_and_show_attention(encoder, decoder, dataset[2][0], dataset, device)
input = 3 박 4일 정도 놀러 가고 싶다 <EOS>
output = 여행 여행 은 언제나 좋죠 . <EOS>

댓글남기기