🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
Pandas와 scikit-learn으로 정말 간단한 pre-processing 몇 가지 팁
캐글 (Kaggle) 의 Titanic: Machine Learning from Disaster 의 train 데이터를 활용해 간단한 시각화 및 빠진 데이터 pre-processing 그리고 간단한 Normalization까지 해보도록 하겠습니다. Train 데이터는 윗 줄의 링크에서 Data탭에서 받아볼 수 있습니다.
전체적인 개요 살펴보기
column의 갯수를 확인하고 혹시 빠진 데이터인 NaN 값이 있는지 가볍게 확인할 수 있는 pandas의 기본 method가 바로 .describe() 입니다. 코드로 보면 다음과 같습니다.
import pandas as pd
# data import
data = pd.read_csv('data/train.csv')
# decribe 확인
print(data.describe())
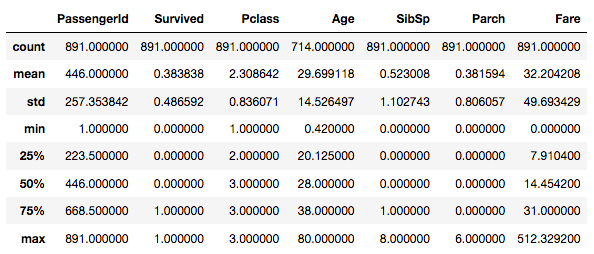
위의 테이블에서 보는바와 같이, Age column의 count 가 다른 column 보다 갯수가 적음을 확인할 수 있습니다. 즉, NaN값이 존재한다는 의미가 될 수 있겠습니다.
테이블에서는 count 뿐만 아니라, mean / std와 같은 속성들에 대한 종합적인 정보도 제공해 줍니다.
유용할 수 있는 정보를 예로 들자면,
Survived의 column과 같은 경우, 탑승객이 살았다면 1 그렇지 않다면 0으로 표기되어 있습니다. mean은 전체 데이터의 합을 갯수로 나눈 평균값이므로, Survived의 mean은 곧 전체 탑승객의 생존율을 말해줍니다.
column별 그룹으로 나누어 데이터를 볼 수 있는 groupby나 pivot_table 을 활용하여 세분화된 분석이 가능할 수 있겠으나, 추후 이부분은 더 디테일하게 다루도록 하고 이번 내용에서는 간략하게만 설명하고 넘어가겠습니다.
print(data.info())
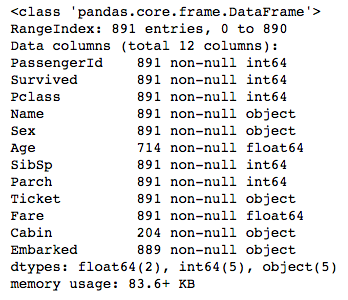
.info()의 메소드를 활용해서도 NaN값이 어느 column에서 빠졌는지 쉽게 확인할 수 있습니다. Age, Cabin, Embarked에서 빠졌음을 볼 수 있습니다. Embarked column은 단 2곳만이 빠졌기 때문에 눈으로 일일이 확인했더라면 놓쳤을 수도 있었겠습니다.
빠졌으면 채워넣어야지
이번에는 sklearn패키지에서 제공해주는 소중한 툴을 활용하여 빠진 데이터를 쉽게 채워넣어 보겠습니다.
우선, 예시부터 보도록 하겠습니다.
from sklearn.preprocessing import Imputer
df = data.copy()
# text 로 표기된 column은 drop
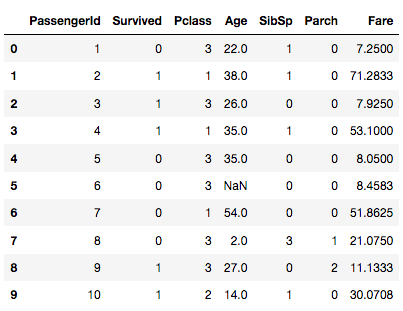
df.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
df.head(10)
imputer = Imputer(strategy='median')
strategy를 옵션 값으로 주게 되어있는데, strategy의 옵션 값으로는 ‘mean’, ‘median’, 그리고 ‘most_frequent’가 있습니다.
imputer.fit(df)
print(imputer.statistics_)
데이터를 fit한 후에 statistics_에 저장된 결과 값을 출력해 볼 수 있습니다.
출력 결과
array([446. , 0. , 3. , 28. , 0. , 0. ,
14.4542])
이제는 transform()을 호출하여 적용해 보도록 하겠습니다.
output = imputer.transform(df)
## DataFrame으로 전환
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
print(output.info())
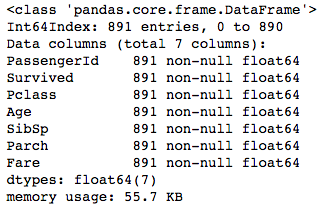
빠진 데이터들이 채워졌음을 확인할 수 있습니다.
Text (문자형 데이터)를 숫자로 변환해볼까
기존의 성별 column 인 data[‘Sex’]를 출력해 보면 ‘male’과 ‘female’로 구성되어 있음을 알 수 있습니다. 성별은 binary 속성 (남 / 여) 으로 구성되어 있기 때문에 이를 0 / 1로 변환해 주고 싶다면 factorize() 를 호출하여 손쉽게 변환할 수 있습니다.
sex_encoded, sex_category = data['Sex'].factorize()
print(sex_encoded)
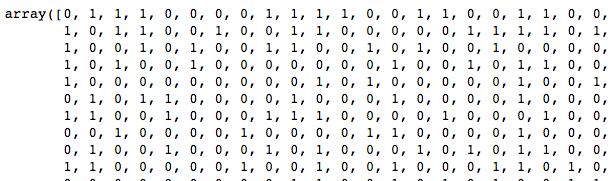
one-hot encoding 도 쉽게 해보자
One-hot 인코딩의 필요성과 세부적인 내용은 이전 포스팅 에서 확인하실 수 있습니다.
이번에는 sklearn.preprocessing 패키지를 활용하여 one-hot encoding 해 보도록 하겠습니다.
우선, ‘Embarked’ column을 살펴 보면, ‘C’, ‘S’, ‘Q’ 3가지로 이뤄져 있음을 확인할 수 있습니다. (참고로, 2개의 row에 NaN 값이 있습니다)
# NaN값에 'S' 입력처리
data.loc[data['Embarked'].isnull(), 'Embarked'] = 'S'
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
embarked_encoded, embarked_categories = data['Embarked'].factorize()
embarked_hot = encoder.fit_transform(embarked_encoded.reshape(-1, 1))
print(embarked_hot.toarray())

매우 쉽게 one-hot encoding 하였음을 확인할 수 있습니다.
Normalization - 데이터 정규화
이번에는 sklearn.preprocessing 패키지가 제공하는 MinMaxScaler / StandardScaler를 활용하여 데이터 정규화를 해보겠습니다.
min-max scaling
우선, min-max scaler를 python으로 구현해 보았는데, 코드는 다음과 같습니다.
def norm(x):
_max = x.max()
_min = x.min()
_denom = _max - _min
return (x - _min) / _denom
위 함수를 통하여 min-max scaling 할 수 있겠으나, sklearn을 통하여 해보겠습니다.
from sklearn.preprocessing import MinMaxScaler
print(output.head())
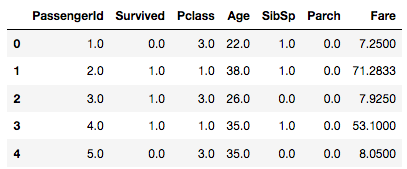
min_max_scaler = MinMaxScaler()
fitted = min_max_scaler.fit(output)
print(fitted.data_max_)
## 출력 결과
## [891. 1. 3. 80. 8. 6. 512.3292]
output = min_max_scaler.transform(output)
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
print(output.head())
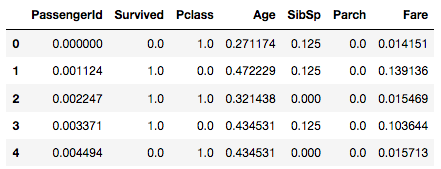
standardization
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
output.head()
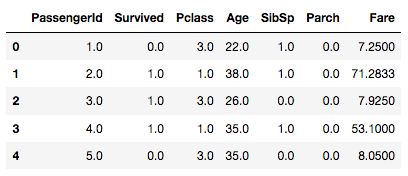
fitted = std_scaler.fit(output)
print(fitted.mean_)
## 출력 결과
## array([4.46000000e+02, 3.83838384e-01, 2.30864198e+00, 2.93615825e+01,
## 5.23007856e-01, 3.81593715e-01, 3.22042080e+01])
output = std_scaler.transform(output)
output = pd.DataFrame(output, columns=df.columns, index=list(df.index.values))
print(output.head())
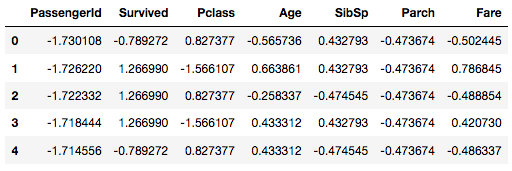
Min-max scaling 과 standardization 에서 전혀 다른 값으로 normalize 됨을 확인할 수 있었습니다. 데이터의 특성에 따라 어떻게 normalization을 해야하는지 결정하고 이에 맞는 정규화 방법을 활용해야겠습니다.
Pandas를 이용한 최소한의 시각화
matplotlib 에서 제공하는 막강한 시각화 툴을 활용하여 다양한 조합의 데이터들을 시각화해 볼 수 있습니다. 하지만 이번 포스팅에서는 pandas가 제공하는 간략한 개요를 볼 수 있는 시각화를 살펴 보도록 하겠습니다.
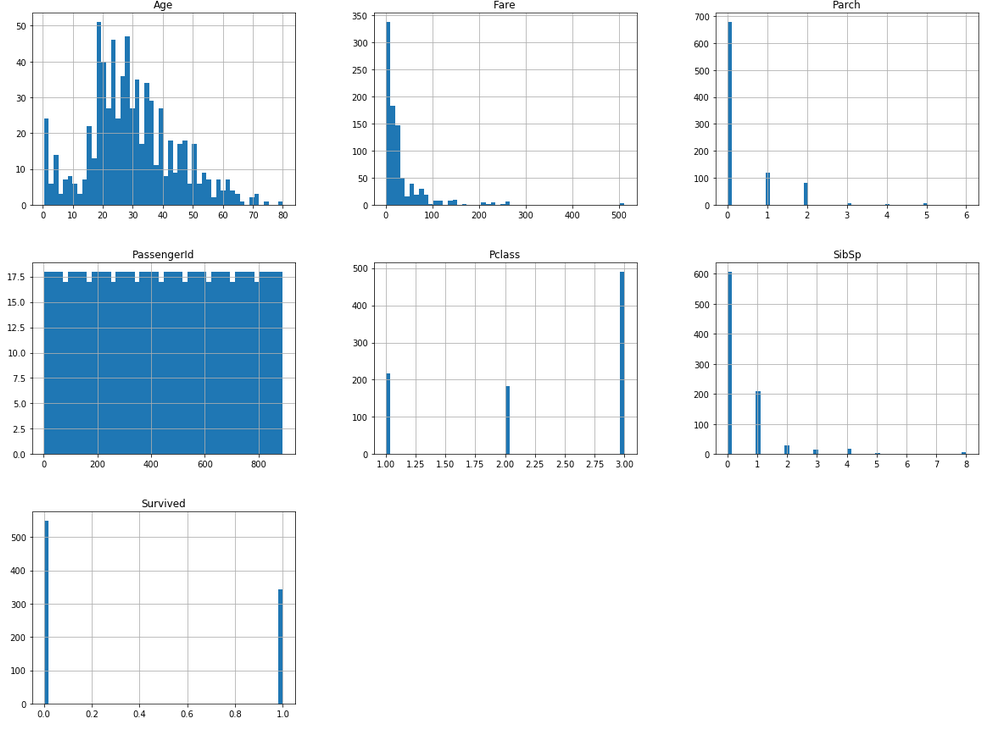
column별 간단한 hist를 보고 싶을때는..
data.hist(bins=50, figsize=(20, 15))
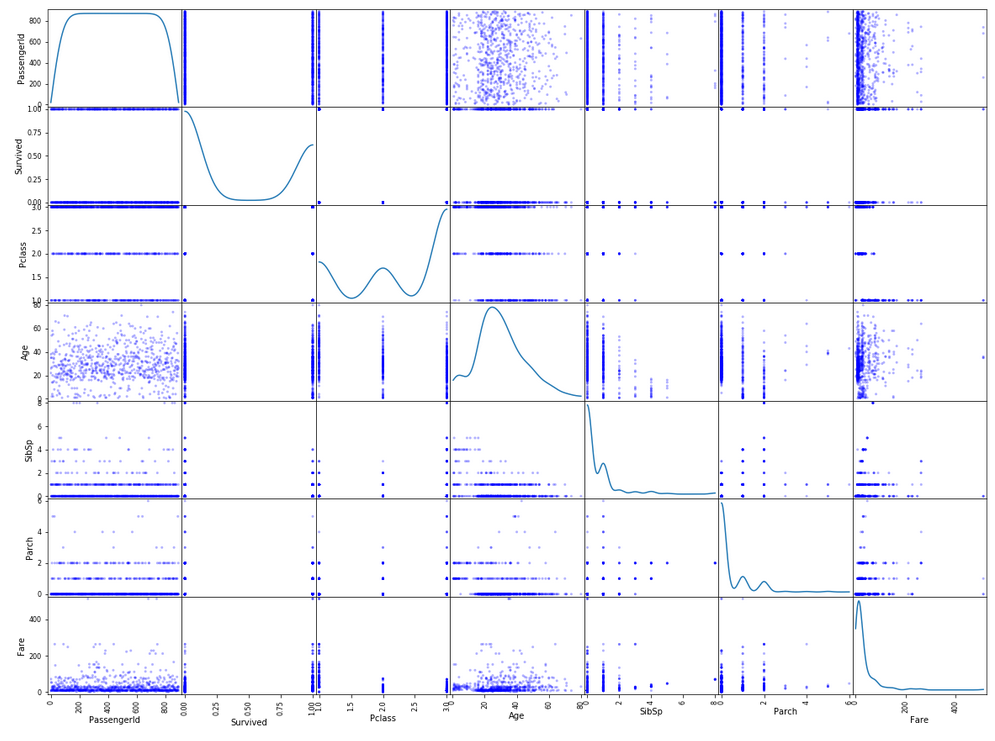
Column by column 으로 볼 수 있는 scatter_matrix
pd.scatter_matrix(data, diagonal='kde', color='b', alpha=0.3, figsize=(20, 15))
댓글남기기