🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
[tensorflow] ImageDataGenerator / Convolution Neural Network(CNN) 을 활용한 이미지 분류
TensorFlow 2.0의 ImageDataGenerator를 활용하여 Image 데이터를 로컬 폴더에서 로딩 후 Generator를 통해 Image Augmentation과 모델에 Feed 할 수 있는 Generator를 만들어 보도록 하겠습니다.
ImageDataGenerator만 잘 활용해도 적은 Image 데이터 Augmentation으로 생성된 다양한 Data를 Generation할 수 있다는 장점이 있습니다.
Image Augmentation을 적용한 후에는 Convolution Neural Network가 사진으로부터 어떻게 feature extraction을 하는지 직접 시각화해보고, model을 만들어 ImageDataGenerator를 통한 학습까지 진행해 보도록 하겠습니다.
import urllib.request
import zipfile
import numpy as np
import os
from IPython.display import Image
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dropout, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.image import ImageDataGenerator
%%javascript
IPython.OutputArea.auto_scroll_threshold = 50;
STEP 1. Load Dataset & Define Folder
개와 고양이를 분류하는 classification 문제입니다.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
download 받은 폴더의 경로를 출력합니다
os.listdir(PATH)
train과 validation폴더로 구분하여 Dataset을 제공하고 있습니다.
각각의 폴더에 대한 ImageDataGenerator를 만들어 줍니다.
train_path = os.path.join(PATH, 'train')
validation_path = os.path.join(PATH, 'validation')
STEP 2. ImageDataGenerator
이미지의 RGB 값이 0~255 값으로 표현되는데 우리는 0~1 값으로 바꿔줍니다.
original_datagen = ImageDataGenerator(rescale=1./255)
rescale: 이미지의 픽셀 값을 조정rotation_range: 이미지 회전width_shift_range: 가로 방향으로 이동height_shift_range: 세로 방향으로 이동shear_range: 이미지 굴절zoom_range: 이미지 확대horizontal_flip: 횡 방향으로 이미지 반전fill_mode: 이미지를 이동이나 굴절시켰을 때 빈 픽셀 값에 대하여 값을 채우는 방식
training_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest')
STEP 3. Make Generator
flow_from_directory
original_generator = original_datagen.flow_from_directory(train_path,
batch_size=128,
target_size=(150, 150),
class_mode='binary'
)
training_generator = training_datagen.flow_from_directory(train_path,
batch_size=128,
shuffle=True,
target_size=(150, 150),
class_mode='binary'
)
validation_generator = training_datagen.flow_from_directory(validation_path,
batch_size=128,
shuffle=True,
target_size=(150, 150),
class_mode='binary'
)
STEP 4. 시각화 해보기
import matplotlib.pyplot as plt
%matplotlib inline
class_map = {
0: 'Cats',
1: 'Dogs',
}
print('오리지널 사진 파일')
for x, y in original_generator:
print(x.shape, y.shape)
print(y[0])
fig, axes = plt.subplots(2, 5)
fig.set_size_inches(15, 6)
for i in range(10):
axes[i//5, i%5].imshow(x[i])
axes[i//5, i%5].set_title(class_map[int(y[i])], fontsize=15)
axes[i//5, i%5].axis('off')
plt.show()
break
print('Augmentation 적용한 사진 파일')
for x, y in training_generator:
print(x.shape, y.shape)
print(y[0])
fig, axes = plt.subplots(2, 5)
fig.set_size_inches(15, 6)
for i in range(10):
axes[i//5, i%5].imshow(x[i])
axes[i//5, i%5].set_title(class_map[int(y[i])], fontsize=15)
axes[i//5, i%5].axis('off')
plt.show()
break


Convolution Neural Network (CNN)
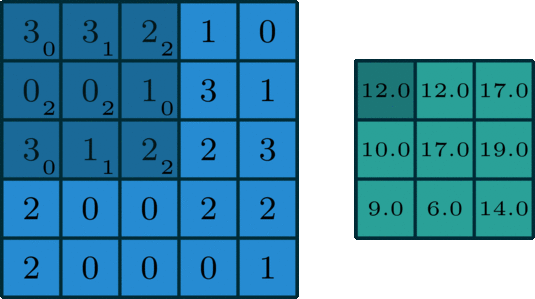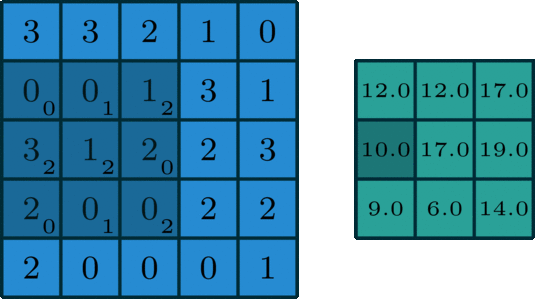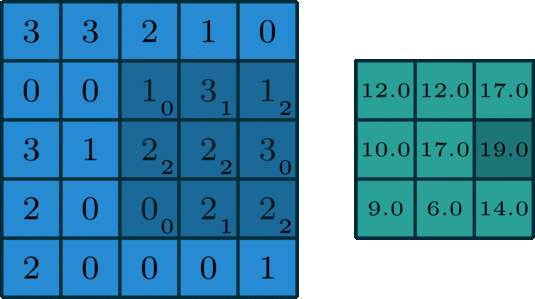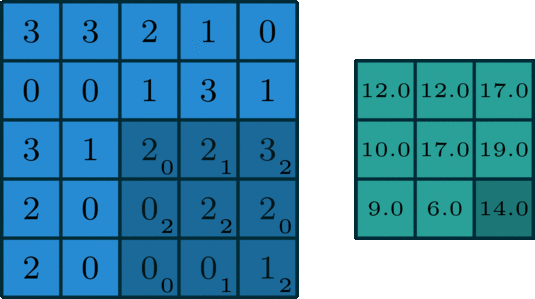
CNN - activation - Pooling 과정을 통해 이미지 부분 부분의 주요한 Feature 들을 추출해 냅니다.
CNN을 통해 우리는 다양한 1개의 이미지를 filter를 거친 다수의 이미지로 출력합니다.
filter의 사이즈는 3 X 3 필터를 자주 사용합니다
또한, 3 X 3 필터를 거친 이미지의 사이즈는 2px 만큼 사이즈가 줄어듭니다.
{kind=link}
Image('https://devblogs.nvidia.com/wp-content/uploads/2015/11/fig1.png')

for x, y in original_generator:
pic = x[:5]
break
pic.shape
plt.imshow(pic[0])

Conv2D를 거친 후
conv2d = Conv2D(64, (3, 3), input_shape=(150, 150, 3))
conv2d_activation = Conv2D(64, (3, 3), activation='relu', input_shape=(150, 150, 3))
fig, axes = plt.subplots(8, 8)
fig.set_size_inches(16, 16)
for i in range(64):
axes[i//8, i%8].imshow(conv2d(pic)[0,:,:,i], cmap='gray')
axes[i//8, i%8].axis('off')

fig, axes = plt.subplots(8, 8)
fig.set_size_inches(16, 16)
for i in range(64):
axes[i//8, i%8].imshow(conv2d_activation(pic)[0,:,:,i], cmap='gray')
axes[i//8, i%8].axis('off')

plt.imshow(conv2d(pic)[0,:,:,34], cmap='gray')

plt.imshow(conv2d_activation(pic)[0,:,:,34], cmap='gray')

MaxPooling2D를 거친 후
fig, axes = plt.subplots(8, 8)
fig.set_size_inches(16, 16)
for i in range(64):
axes[i//8, i%8].imshow(MaxPooling2D(2, 2)(conv2d(pic))[0, :, :, i], cmap='gray')
axes[i//8, i%8].axis('off')

STEP 5. Build Model
model = Sequential([
Conv2D(16, (3, 3), padding='same', activation='relu', input_shape=(150, 150, 3)),
MaxPooling2D(2, 2),
Conv2D(32, (3, 3), padding='same', activation='relu'),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), padding='same', activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dense(1, activation='sigmoid'),
])
model.summary()
STEP 6. optimizer, loss
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
STEP 7. train
epochs=25
history = model.fit(training_generator,
validation_data=validation_generator,
epochs=epochs)
STEP 8. 학습결과 Visualization
plt.figure(figsize=(9, 6))
plt.plot(np.arange(1, epochs+1), history.history['loss'])
plt.plot(np.arange(1, epochs+1), history.history['val_loss'])
plt.title('Loss / Val Loss', fontsize=20)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['loss', 'val_loss'], fontsize=15)
plt.show()

plt.figure(figsize=(9, 6))
plt.plot(np.arange(1, epochs+1), history.history['acc'])
plt.plot(np.arange(1, epochs+1), history.history['val_acc'])
plt.title('Acc / Val Acc', fontsize=20)
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(['acc', 'val_acc'], fontsize=15)
plt.show()

댓글남기기