🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
TensorFlow 와 PyTorch 중 무엇을 써야할까?
TensorFlow는 딥러닝 프레임워크 시장에서 초기에 막강한 선두 주자 였습니다. 그러나 최근에 들어 PyTorch가 연구 커뮤니티에서 큰 사랑을 받기 시작했습니다.
두 프레임워크는 머신러닝 모델의 구축, 학습 및 추론을 지원하며, 여러 공통점이 있지만 구조와 디자인 철학에서 몇 가지 핵심 차이점이 있습니다. 이 포스팅을 통해 각 프레임워크의 핵심 특성과 함께 예제 코드를 통한 실제 구현의 차이를 명확하게 이해할 수 있을 것입니다.
🌈 딥러닝 프레임워크의 거장: TensorFlow & PyTorch
TensorFlow는 초기에 딥러닝 프레임워크 시장에서 매우 강력한 위치 를 차지하였습니다. 그러나 시간이 지남에 따라 PyTorch가 연구 커뮤니티에서 큰 인기 를 얻기 시작했습니다.
TensorFlow(파란색) vs PyTorch(빨간색) 관심도 변화
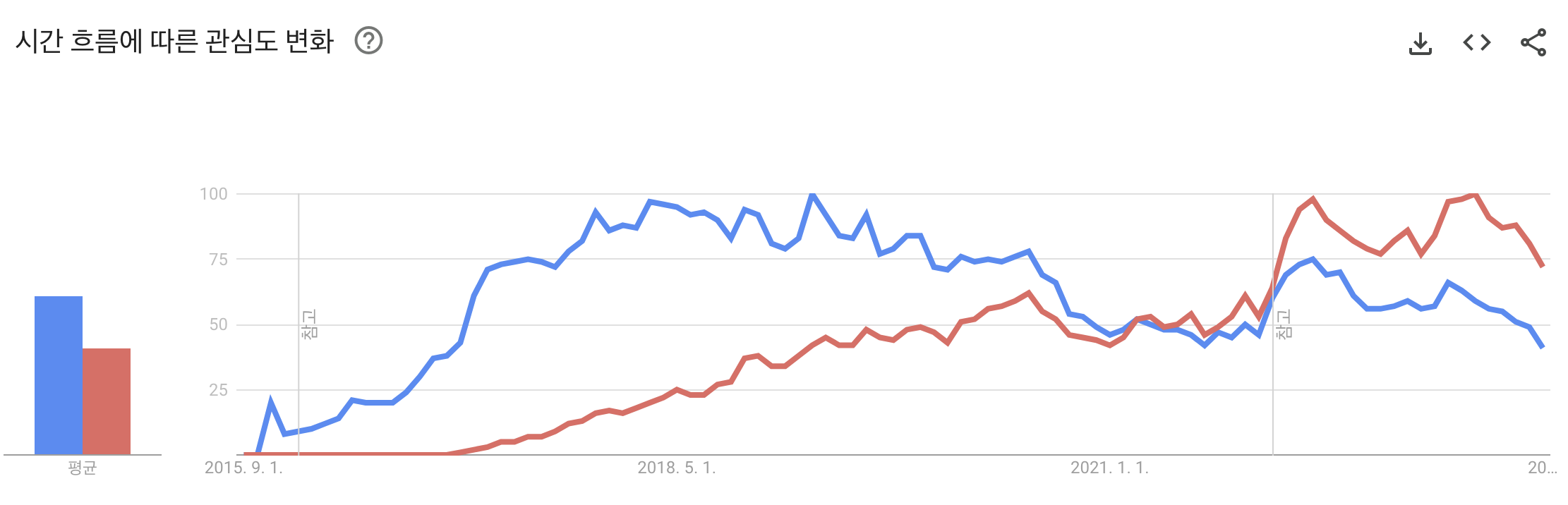
TensorFlow의 점유율이 PyTorch에 비해 상대적으로 밀리게 된 주요 계기는 아래와 같습니다.
① 디자인 철학의 차이
TensorFlow 1.x는 정적 계산 그래프 (Define-and-Run) 를 사용했는데, 이는 초기 사용자들에게 학습 곡선(learning curve) 이 크고, 디버깅이 어려운 단점 이 있었습니다.
TensorFlow 1.x의 코드 스타일은 정적 계산 그래프를 기반으로 하기 때문에, 연산의 정의와 실행이 분리 되어 있습니다. 이로 인해 코드가 상대적으로 덜 직관적 이게 됩니다.
TensorFlow 1.x에서 간단한 선형 회귀 모델을 학습하는 예시 코드
import tensorflow as tf
# 1. 데이터 정의
# 특성 및 레이블 데이터를 위한 placeholder 정의
X = tf.placeholder(tf.float32, shape=[None, 1], name="X")
Y = tf.placeholder(tf.float32, shape=[None, 1], name="Y")
# 2. 변수 및 모델 구조 정의
# 선형 회귀 모델의 가중치와 편향
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.random_normal([1]), name="bias")
# 예측 모델: Y = X * W + b
prediction = tf.add(tf.multiply(X, W), b)
# 3. 손실 함수 정의
loss = tf.reduce_mean(tf.square(prediction - Y))
# 4. 옵티마이저 및 학습 연산 정의
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(loss)
# 5. 세션 생성 및 변수 초기화
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 변수 초기화
# 6. 학습 데이터
train_data = {
X: [[1], [2], [3]],
Y: [[2], [4], [6]]
}
# 7. 학습 진행
for step in range(1000):
_, l = sess.run([train_op, loss], feed_dict=train_data)
if step % 100 == 0:
print("Step: %i, Loss: %f" % (step, l))
sess.close()
기존 TensorFlow 1.x 버전을 사용한 사용자들은 코드의 직관성이 떨어지고, 디버깅도 어려운 TensorFlow 프레임워크에 불편함 을 느끼게 됩니다. 때문에 많은 연구 커뮤니티에서는 TensorFlow 1.x 이 지닌 단점을 보완하고 실행속도도 더 빠른 PyTorch 프레임워크에 빠르게 받아들이기 시작합니다.
TensorFlow & PyTorch 비교표
| 항목 | PyTorch | TensorFlow |
|---|---|---|
| 디자인 철학 | Imperative Programming (Define-by-Run) | TensorFlow 1.x: Declarative Programming (Define-and-Run) TensorFlow 2.x: Eager Execution (Define-by-Run) |
| 그래프 생성 | 동적 계산 그래프 | TensorFlow 2.x는 Eager Execution을 사용하지만, 정적 그래프도 지원 가능 |
| 디버깅 | Pythonic하며, 동적 계산 그래프로 인해 디버깅이 상대적으로 쉽다. | TensorFlow 2.x의 Eager Execution으로 개선됨. 1.x에서는 복잡함. |
| 프로덕션 | TorchScript 사용 | TensorFlow Serving, TensorFlow Lite, TensorFlow.js 제공 |
| API & 생태계 | 자연스러운 Python API. PyTorch Lightning 등의 확장 포함. | 포괄적인 API. Keras 통합. TFX 등의 확장 프로그램 제공. |
| 커뮤니티 | 주로 학계에서 인기. 연구용 프로젝트 및 논문에 주로 사용. | 구글 지원. 연구와 상용 애플리케이션 모두에서 널리 사용됨. |
PyTorch는 동적 계산 그래프 (Define-by-Run)를 사용하여 사용자가 코드를 순차적으로 작성하고 실행 할 수 있게 하였습니다. 이 동적 계산 그래프의 접근 방식은 연구자들에게 모델 구축 및 디버깅이 더 직관적이라는 장점 이 있었습니다.
이후 PyTorch가 연구 커뮤니티에서 많이 활용되기 시작하고, 커뮤니티가 커지게 되고, TensorFlow 역시 사용자들의 피드백을 듣고 변화하였습니다.
2019년 2.0 버전의 TensorFlow 를 출시하게 됩니다. TensorFlow 2.x 에서는 tf.keras를 중심으로 API를 간소화하였고, 동적 계산 그래프를 지원하는 tf.function을 도입하여 PyTorch와 유사한 경험을 제공하기 시작했습니다.
아래는 TensorFlow 2.x 와 PyTorch 를 활용한 선형회귀 모델 학습 예시코드입니다.
TensorFlow 2.x: 선형회귀 모델 예시코드
import tensorflow as tf
# 데이터
x_data = [1, 2, 3, 4, 5]
y_data = [2, 4, 5, 4, 5]
# 모델 정의
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_dim=1)
])
# 모델 컴파일
model.compile(optimizer='sgd', loss='mean_squared_error')
# 모델 학습
model.fit(x_data, y_data, epochs=1000, verbose=0)
# 예측
print(model.predict([10]))
PyTorch: 선형회귀 모델 예시코드
import torch
import torch.nn as nn
import torch.optim as optim
# 데이터
x_data = torch.tensor([[1.], [2.], [3.], [4.], [5.]])
y_data = torch.tensor([[2.], [4.], [5.], [4.], [5.]])
# 모델 정의
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
model = LinearRegressionModel()
# 손실 함수와 최적화 정의
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 모델 학습
for epoch in range(1000):
optimizer.zero_grad()
outputs = model(x_data)
loss = criterion(outputs, y_data)
loss.backward()
optimizer.step()
# 예측
print(model(torch.tensor([[10.]])))
② 연구 커뮤니티의 성장
Deep Learning 프레임워크의 전쟁에서 PyTorch는 연구 분야에서 빠르게 성장하는 인기를 누리고 있습니다. TensorFlow는 상업적인 애플리케이션과 대규모 배포에 적합하게 설계되었으며, 초기에 많은 주목을 받았습니다. 그럼에도 불구하고, PyTorch는 특히 연구 커뮤니티에서 빠르게 성장하였는데, 그 이유는 무엇일까요?
-
연구 논문과 코드의 연결
- 최근 연구 논문들, 특히 NeurIPS, ICML, ICLR 등 주요 학술 대회의 논문들에서는 PyTorch를 사용한 코드 구현의 예시를 자주 볼 수 있습니다. 이런 연구 논문들의 코드가 공개되면, 연구 커뮤니티는 해당 논문의 기법을 자신들의 연구에 쉽게 적용할 수 있게 됩니다.
-
동적 계산 그래프
- PyTorch의 동적 계산 그래프는 연구자들이 모델을 더 자유롭게 실험하고, 디버깅하기 쉽게 만들어줍니다. 이러한 특징은 연구 초기 단계에서의 빠른 프로토타이핑에 큰 장점을 제공합니다.
-
풍부한 튜토리얼과 리소스
- PyTorch 공식 웹사이트에서는 다양한 튜토리얼과 교육 자료를 제공하고 있어, 초보자도 쉽게 접근하여 학습할 수 있습니다.
-
밀접한 연구 커뮤니티의 협력
- 많은 대학 연구실과 기관들이 PyTorch를 채택하면서, 연구 커뮤니티 내에서의 정보 공유와 협력이 활발해졌습니다. 이런 환경은 새로운 아이디어나 기법의 공유를 촉진하며, 연구의 진행을 가속화시킵니다.
이러한 이유들로, PyTorch는 연구 분야에서 주목받는 프레임워크로 자리매김하게 되었습니다. 물론, TensorFlow도 연구 커뮤니티를 위한 다양한 기능과 툴을 제공하고 있지만, 현재의 트렌드를 보면 PyTorch가 연구 분야에서는 약간의 우위를 가지고 있는 것으로 보입니다.
③ Pythonic한 스타일
PyTorch는 그 구현 방식과 인터페이스가 Python 스타일에 더 가깝게 설계되어 있어, 기존의 Python 개발자들이 더 쉽게 접근하고 사용할 수 있었습니다. 2019년 TensorFlow 도 변화를 도모하기 시작하였습니다. TensorFlow 2.x에서는 PyTorch의 동적 계산 그래프 방식을 인식하고 이를 Eager Execution 모드로 도입하였습니다. 그러나 이러한 큰 변화는 기존 사용자들에게 학습 곡선을 제공하였으며, 일부 사용자들이 PyTorch로 전환하는 계기가 되었습니다.
④ 교육 및 커뮤니티 리소스
많은 온라인 교육 자료와 커뮤니티 리소스가 PyTorch를 기반으로 제작되었습니다. 이로 인해 새로운 사용자들이 PyTorch를 더 쉽게 배우고 적용할 수 있었습니다.
⑤ 그 밖에
- 강력한 Autograd 시스템: PyTorch는 자동 미분(Autograd) 시스템이 내장되어 있어, 복잡한 모델과 연산에 대한 그래디언트 계산을 자동으로 처리할 수 있습니다.
- 밀접한 통합과 확장성: PyTorch는 다양한 딥러닝 라이브러리와 툴(예: TorchVision, HuggingFace Transformers 등)와 밀접하게 통합되어 있습니다. 이로 인해 사용자들은 다양한 태스크에 쉽게 접근하고 활용할 수 있습니다.
- Facebook의 지원: PyTorch는 Facebook의 AI Research lab(FAIR)에 의해 개발되었으며, 이로 인해 계속적인 개선과 확장이 이루어지고 있습니다.
이러한 요인들은 PyTorch가 딥러닝 및 머신러닝 연구 커뮤니티에서 널리 받아들여지고 인기를 얻게 된 주요 원인들 중 일부 입니다.
🔥 앞으로의 TensorFlow vs PyTorch. 승자는?
PyTorch와 TensorFlow는 각각 독특한 개발 이야기와 복잡한 디자인 결정 과정을 거쳤습니다. 이로 인해 두 프레임워크를 비교하는 것은 그들의 현재 기능과 예상되는 미래 기능에 대한 복잡한 기술적 토론이 되었습니다. 그러나 두 프레임워크 모두 출시 이후 급속도로 성숙해졌기 때문에 이러한 기술적인 차이점은 대부분 현재 의미가 없게 되었습니다.
PyTorch와 TensorFlow 간의 논의는 종종 “TensorFlow는 상용 환경에 적합” 하며 “PyTorch는 연구에 적합” 하다는 프레임으로 서술되었습니다. 그러나 두 프레임워크는 계속 발전하고 있으며, 2023년 현재로서는 그 답이 그렇게 단순하지 않습니다. 다양한 관점에서 이 논쟁을 살펴보겠습니다.
① 주요 쟁점
- 모델의 유용성: 딥러닝 분야가 매년 확장되고 모델들이 차례로 커지기 때문에 최첨단 (SOTA) 모델을 처음부터 훈련시키는 것은 더 이상 실행 가능하지 않습니다. 다행히도 많은 SOTA 모델들이 공개적으로 이용 가능하며 가능한 경우 이를 활용하는 것이 중요합니다.
- 배포 인프라: 잘 작동하는 모델을 훈련시키는 것은 이를 사용할 수 없다면 의미가 없습니다. 특히 마이크로서비스 비즈니스 모델의 인기가 높아짐에 따라 배포까지의 시간을 줄이는 것이 중요하며, 효율적인 배포는 기계 학습을 중심으로 하는 많은 기업에서 중요한 문제가 될 수 있습니다.
- 생태계: 딥러닝은 더 이상 특정 사용 사례에만 국한되지 않습니다. AI는 다양한 산업에 새로운 힘을 주입하고 있으므로 모바일, 로컬 및 서버 애플리케이션 개발을 촉진하는 더 큰 생태계 내에서 프레임워크를 사용하는 것이 중요합니다. 또한 Google의 Edge TPU와 같은 특수 기계 학습 하드웨어의 출현으로 성공적인 전문가는 이 하드웨어와 잘 통합될 수 있는 프레임워크와 함께 작업해야 합니다.
② 모델의 유용성
TensorFlow
- TensorFlow는 TensorFlow Hub에서 많은 사전 훈련된 모델을 제공합니다. 이는 상업적인 응용 프로그램에 매우 적합합니다.
PyTorch
- PyTorch는 Torch Hub를 통해 다양한 사전 훈련된 모델을 제공합니다. 연구자들이 즐겨 사용하기 때문에 최신의 연구 결과를 빠르게 찾을 수 있습니다.
TensorFlow와 PyTorch는 각각 TensorFlow Hub와 PyTorch Hub 에 보관된 대규모의 사전 훈련된 모델에 접근할 수 있게 해줍니다. 이들은 추론, 미세 조정, 배포를 위한 훈련된 모델의 저장소입니다. 몇 줄의 코드만으로 이미지 세그멘테이션을 위한 사전 훈련된 Mask RCNN을 사용하고 선호하는 백본 모델을 선택할 수 있습니다.
현재로서, TensorFlow Hub는 컴퓨터 비전(이미지 및 비디오), 텍스트, 오디오의 네 영역에 걸쳐 1300개의 다양한 모델 을 제공합니다. 대부분은 컴퓨터 비전을 위한 것입니다.
반면에, PyTorch Hub는 단지 49개의 모델 만을 호스팅합니다. 사전 훈련된 모델 컬렉션 측면에서 TensorFlow가 우위를 점하고 있습니다.
③ 배포 인프라
TensorFlow
- TensorFlow는 TensorFlow Serving, TensorFlow Lite, TensorFlow.js 등 다양한 플랫폼 및 어플리케이션에 모델을 배포하는 데 필요한 도구를 포괄적으로 제공합니다.
PyTorch
- TorchServe를 사용하여 모델을 배포할 수 있습니다. 그러나 초기에는 배포 측면에서 TensorFlow에 비해 다소 뒤처졌습니다.
④ 생태계
TensorFlow:
- TensorFlow는 Google의 강력한 지원을 받고 있으며, Google Cloud, TPU와 같은 다양한 제품과 서비스와의 통합이 잘 되어 있습니다.
PyTorch:
- PyTorch는 Facebook의 FAIR 연구 그룹과 긴밀하게 연결되어 있습니다. 이는 연구 중심의 개발에 특화되어 있습니다.
🔆 결론
PyTorch와 TensorFlow는 둘 다 딥러닝과 기계 학습 분야에서 굉장히 강력하고 인기 있는 프레임워크입니다. 그렇기 때문에 어느 한 쪽을 선택하는 것은 종종 개인의 필요나 특정 프로젝트의 요구 사항에 따라 결정됩니다.
PyTorch는 그 직관적인 인터페이스와 동적 계산 그래프로 인해 연구자들 사이에서 큰 인기를 얻었습니다. 이러한 특징은 연구와 프로토타이핑을 더 쉽고 유연하게 만듭니다. 만약 새로운 모델 아키텍처나 연구 아이디어를 실험하려는 학계의 연구자라면, PyTorch는 아마 더 적절한 선택지라고 생각합니다.
반면 TensorFlow는 그 풍부한 기능과 배포를 위한 강력한 도구로 인해 상업적인 환경에서 더 널리 사용됩니다. TensorFlow Serving, TensorFlow Lite 등의 도구는 다양한 플랫폼에 모델을 쉽게 배포할 수 있게 합니다. 또한, Google의 강력한 지원과 함께 Google Cloud, TPU와의 통합은 큰 규모의 데이터와 복잡한 인프라에서 모델을 훈련하고 배포하는 데 있어 큰 장점을 제공합니다.
두 프레임워크 모두 계속해서 발전하고 있으므로, 둘 중 어느 것을 선택하든지, 당신은 강력한 커뮤니티의 지원과 지속적인 업데이트를 기대할 수 있습니다. 선택의 기준은 당신의 프로젝트의 목적, 필요한 도구 및 리소스, 그리고 개인적인 경험과 선호도에 달려 있습니다.
댓글남기기