🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
Python 시계열 데이터 분석 - AR, MA, ARIMA, SARIMAX, 분해, 지수평활
시계열 데이터 분석이라는 다소 넓은 범위의 주제이지만, 그 중에서도 전통적인 시계열 분석에서 언급되는 주요 분석 기법에 대해서 간략히 알아보고, 파이썬(Python) 코드로 구현하는 방법에 대해 알아보겠습니다.
필요한 모듈 import
시계열 데이터 분석에 필요한 패키지를 설치합니다.
# !pip install pmdarima -q
# !pip install statsmodels -q
import os
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import warnings
# SEED 설정
SEED = 123
##################### Pandas #####################
# DataFrame 행과 열의 출력 개수 지정. None은 전체 출력.
pd.set_option('display.max_columns', None)
# 1,000 단위 표기
pd.options.display.float_format = '{:,.3f}'.format
##################### Matplotlib #####################
# Unicode warning 제거 (폰트 관련 경고메시지)
plt.rcParams['axes.unicode_minus']=False
### 한글 폰트 설정 ###
# 나눔고딕 폰트
plt.rcParams['font.family'] = "NanumGothic"
# 맑은고딕 폰트
# plt.rcParams['font.family'] = "Malgun Gothic"
# 애플고딕 (Mac OS)
# plt.rcParams['font.family'] = "AppleGothic"
# 그래프 출력 사이즈 설정
plt.rcParams["figure.figsize"] = (10, 6)
# Seaborn
# sns.set_style("white")
COLORS = {
'green': '#278F45',
'red': '#DB4A25',
'blue': '#23D3DB',
'black': '#000000',
'yellow': '#DBBE2E',
}
%matplotlib inline
######################## Others #########################
# 노트북 출력에 나타나는 경고(warning) 메시지 무시
warnings.filterwarnings('ignore')
데이터 로드
- 금융 데이터 로드를 위한 Finance DataReader 모듈 설치
# Finance DataReader 설치
# !pip install -U finance-datareader
import FinanceDataReader as fdr
df = fdr.DataReader('BTC/USD')
df.head()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2014-09-17 | 465.864 | 468.174 | 452.422 | 457.334 | 457.334 | 21056800 |
| 2014-09-18 | 456.860 | 456.860 | 413.104 | 424.440 | 424.440 | 34483200 |
| 2014-09-19 | 424.103 | 427.835 | 384.532 | 394.796 | 394.796 | 37919700 |
| 2014-09-20 | 394.673 | 423.296 | 389.883 | 408.904 | 408.904 | 36863600 |
| 2014-09-21 | 408.085 | 412.426 | 393.181 | 398.821 | 398.821 | 26580100 |
freq에 원하는 시계열 데이터의 주기를 입력할 수 있습니다.
- 참고링크: https://pandas.pydata.org/docs/user_guide/timeseries.html#timeseries-offset-aliases
# 주간(Weekly) 데이터만 추출하기 위하여 date_range()를 주 단위로 생성합니다.
target_index = pd.date_range('20130107', '20230701', freq='W-MON')
target_index
DatetimeIndex(['2013-01-07', '2013-01-14', '2013-01-21', '2013-01-28',
'2013-02-04', '2013-02-11', '2013-02-18', '2013-02-25',
'2013-03-04', '2013-03-11',
...
'2023-04-24', '2023-05-01', '2023-05-08', '2023-05-15',
'2023-05-22', '2023-05-29', '2023-06-05', '2023-06-12',
'2023-06-19', '2023-06-26'],
dtype='datetime64[ns]', length=547, freq='W-MON')
# 추출한 시계열 인덱스 데이터로 필터링
df.loc[df.index.isin(target_index)].head(10)
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2014-09-22 | 399.100 | 406.916 | 397.130 | 402.152 | 402.152 | 24127600 |
| 2014-09-29 | 376.928 | 385.211 | 372.240 | 375.467 | 375.467 | 32497700 |
| 2014-10-06 | 320.389 | 345.134 | 302.560 | 330.079 | 330.079 | 79011800 |
| 2014-10-13 | 377.921 | 397.226 | 368.897 | 390.414 | 390.414 | 35221400 |
| 2014-10-20 | 389.231 | 390.084 | 378.252 | 382.845 | 382.845 | 16419000 |
| 2014-10-27 | 354.777 | 358.632 | 349.809 | 352.989 | 352.989 | 13033000 |
| 2014-11-03 | 325.569 | 334.002 | 325.481 | 327.554 | 327.554 | 12948500 |
| 2014-11-10 | 362.265 | 374.816 | 357.561 | 366.924 | 366.924 | 30450100 |
| 2014-11-17 | 388.349 | 410.199 | 377.502 | 387.408 | 387.408 | 41518800 |
| 2014-11-24 | 366.948 | 387.209 | 366.669 | 376.901 | 376.901 | 30930100 |
# 2020년 ~ 2022년 3년치의 시세 데이터를 조회합니다. (Close)는 종가를 의미
data = df.loc[(df.index >= '2020-01-01') & (df.index <= '2022-12-31'), 'Close']
data
Date
2020-01-01 7,200.174
2020-01-02 6,985.470
2020-01-03 7,344.884
2020-01-04 7,410.657
2020-01-05 7,411.317
...
2022-12-27 16,717.174
2022-12-28 16,552.572
2022-12-29 16,642.342
2022-12-30 16,602.586
2022-12-31 16,547.496
Name: Close, Length: 1096, dtype: float64
시계열 데이터 결측치 처리
Simple Imputer
-
단순하게 평균, 중앙값 등으로 채웁니다.
-
하지만, 시계열 데이터의 특성상 앞,뒤 데이터의 추세를 반영하지 못합니다.
# 결측치 확인
data.isnull().sum()
0
# 평균 값으로 채우는 경우
data.fillna(data.mean())
Date
2020-01-01 7,200.174
2020-01-02 6,985.470
2020-01-03 7,344.884
2020-01-04 7,410.657
2020-01-05 7,411.317
...
2022-12-27 16,717.174
2022-12-28 16,552.572
2022-12-29 16,642.342
2022-12-30 16,602.586
2022-12-31 16,547.496
Name: Close, Length: 1096, dtype: float64
Interpolate
- 앞, 뒤 데이터의 추세를 보고 interpolation 값을 계산하여 채웁니다.
# interpolation 방식으로 결측치를 채웁니다.
data = data.interpolate()
data
Date
2020-01-01 7,200.174
2020-01-02 6,985.470
2020-01-03 7,344.884
2020-01-04 7,410.657
2020-01-05 7,411.317
...
2022-12-27 16,717.174
2022-12-28 16,552.572
2022-12-29 16,642.342
2022-12-30 16,602.586
2022-12-31 16,547.496
Name: Close, Length: 1096, dtype: float64
# 결측치 확인
data.isnull().sum()
0
지수평활 (Exponential Smoothing)
지수평활(Exponential Smoothing) 은 시계열 데이터 분석에서 일반적으로 사용되는 기법 중 하나입니다. 이는 데이터의 패턴을 예측하는 데 도움이 되는, 데이터의 노이즈를 줄이고 추세를 더 잘 파악 할 수 있는 방법입니다.
지수평활의 기본적인 아이디어는 최근의 관찰값에 더 많은 가중치 를 주고, 과거의 관찰값에는 적은 가중치 를 주는 것입니다. ‘지수’라는 용어는 각 관찰값에 곱해지는 가중치가 지수적으로 감소하기 때문에 사용됩니다.
이 방법은 다음과 같은 이유로 사용됩니다:
-
간단함: 지수평활은 계산이 간단하고 이해하기 쉬운 방법입니다. 이는 데이터가 복잡한 패턴이나 추세를 보이지 않을 때 특히 유용합니다.
-
노이즈 감소: 지수평활은 원래의 시계열 데이터에서 노이즈를 줄이고 주요한 패턴을 강조함으로써 데이터를 더 잘 이해하는 데 도움이 됩니다.
-
예측: 지수평활은 미래 값의 예측에 사용할 수 있습니다. 이 방법은 과거의 데이터를 사용하여 미래의 데이터를 예측하는 방법 중 하나로, 데이터의 패턴이 시간이 지남에 따라 일정하게 유지될 것으로 예상되는 경우 특히 유용합니다.
-
빠른 업데이트: 지수평활은 새로운 데이터가 추가될 때마다 쉽게 업데이트될 수 있습니다. 이는 특히 실시간 분석이 필요한 경우에 유용합니다.
지수평활에는 다양한 변형이 있습니다.
- 가장 간단한 형태의 지수평활은 단순 지수평활(Simple Exponential Smoothing, SES)이며, 이는 데이터에 선형적인 패턴이 없을 때 사용됩니다.
- 더 복잡한 형태의 지수평활은
홀트의 선형 지수평활(Holt's Linear Exponential Smoothing)이나홀트-윈터스의 계절적 지수평활(Holt-Winters' Seasonal Exponential Smoothing)과 같이 트렌드와 계절성을 포함하는 데이터를 다룰 수 있습니다.
fig, ax = plt.subplots(1, 1)
fig.set_size_inches(10, 6)
fig.set_dpi(300)
ax.plot(data, label='Close', color='black', linestyle='solid', linewidth=0.5)
ax.plot(data.ewm(alpha=0.1).mean(), label='alpha=0.1', color=COLORS['red'], linestyle='solid', linewidth=0.8)
ax.plot(data.ewm(alpha=0.5).mean(), label='alpha=0.5', color=COLORS['blue'], linestyle='solid', linewidth=0.7)
ax.plot(data.ewm(alpha=0.8).mean(), label='alpha=0.8', color=COLORS['green'], linestyle='solid', linewidth=0.5)
plt.xticks(rotation=30)
plt.legend()
plt.show()

이동평균(Moving Average)
이동 평균은 주어진 시점에서 이전 n 개의 데이터 포인트의 평균을 계산 하는 것을 의미합니다.
이는 시계열 데이터의 잡음을 줄이고 데이터의 기본적인 패턴을 확인하는 데 도움이 됩니다.
이동평균(moving average) 를 구하는 방식은 다음과 같습니다.
(예시)
- 10일 이동평균을 계산
data.rolling(window=10).mean()
fig, ax = plt.subplots(1, 1)
fig.set_size_inches(10, 6)
fig.set_dpi(300)
ax.plot(data, label='Close', color='black', linestyle='solid', linewidth=0.5)
ax.plot(data.rolling(window=10).mean().bfill(), label='ma10', color=COLORS['red'], linestyle='solid', linewidth=0.8)
ax.plot(data.rolling(window=20).mean().bfill(), label='ma20', color=COLORS['blue'], linestyle='solid', linewidth=0.7)
ax.plot(data.rolling(window=60).mean().bfill(), label='ma60', color=COLORS['green'], linestyle='solid', linewidth=0.5)
plt.xticks(rotation=30)
plt.legend()
plt.show()

정상성(stationary) / 비정상성(non-stationary)

이미지 출처: https://t1.daumcdn.net/cfile/tistory/99E7CC3E5D13859D30
정상 시계열 (stationary)
정상 시계열은 시간의 흐름에 따라 그 통계적 특성이 변하지 않는 시계열 을 의미합니다.
다시 말해, 정상 시계열의 평균과 분산(또는 표준편차), 그리고 공분산은 시간이 변해도 일정 합니다.
이러한 특성 때문에 정상 시계열은 분석이 용이하며, 많은 통계적 시계열 모델들(AR, MA, ARMA 등)은 데이터가 정상성을 가정 하고 있습니다.
(여기서, 정상성을 가정한다는 점이 매우 중요합니다!!)
(예시)
-
시간에 따른 일정한 주기를 가진 신호(일정한 주기로 진동하는 심장 박동)
-
백색 잡음(랜덤한 값들의 연속) 등이 있습니다.
비정상 시계열 (non-stationary)
비정상 시계열은 시간의 흐름에 따라 그 통계적 특성이 변하는 시계열 을 의미합니다. 즉, 평균, 분산, 공분산 등이 시간에 따라 변화합니다.
비정상 시계열 데이터는 시간의 흐름에 따라 통계적 속성이 변하는 데이터를 의미합니다. 이는 추세(trend) 또는 계절성(seasonality) 때문에 발생할 수 있습니다.
-
추세(trend): 시계열 데이터가
시간에 따라 증가하거나 감소하는 경향을 보일 때, 이를 추세 라고 합니다. -
계절성(seasonality): 시계열 데이터가
일정한 주기로 반복되는 패턴을 보일 때, 이를 계절성 이라고 합니다.
대부분의 실제 시계열 데이터는 비정상적인 성질을 가지고 있습니다. 이 경우에는 데이터를 정상적으로 만드는 변환(예: 차분, 로그 변환 등) 이 필요할 수 있습니다.
(예시)
-
시간에 따라 트렌드가 있는 주가 데이터
-
인구 증가 데이터 등
이러한 데이터는 시간에 따라 평균과 분산이 변하기 때문에 비정상적(non-stationary) 입니다.
정상성(stationary) / 비정상성(non-stationary) 확인
시각화를 통한 확인
ACF(Auto Correlation Function) Plot - 시각화
- 링크: https://www.statsmodels.org/stable/generated/statsmodels.graphics.tsaplots.plot_acf.html
분석 tip 1. 통계적 유의성 확인
-
자기 상관이 통계적으로 유의미한지 여부를 나타내는 “신뢰구간”을 회색 음영 영역(shading area) 으로 표시
-
기본적으로 95% 신뢰구간 을 사용하여 shading area를 그립니다.
-
각 Lag 에서 Shading 영역을 벗어나 자기상관계수(Autocorrelation) 추정치는 95% 신뢰구간을 벗어났기 때문에, 통계적 유의성을 찾을 수 없다 는 의미로 해석할 수 있습니다.
분석 tip 2. 정상성 확인
-
보통은 시차가 커질수록 상관계수는 점차 0에 가까워지며, 시차가 커질 수록 자기상관성이 떨어지는 양상을 보여주는 것이 일반적입니다. 하지만, Seasonal 한 데이터의 경우, 값이 다시 튀어오르는 현상은 있을 수 있습니다.
-
ACF는 시계열 데이터의 정상성을 판단할 때 유용 하게 활용될 수 있습니다.
-
빠르게 0으로 수렴하는 경우 -> 정상(stationary) 시계열, 천천히 감소합니다.
-
큰 상관계수를 가지는 경우 비정상(non-stationary) 시계열 데이터로 평가할 수 있습니다.
-
수식
- ACF는 시계열 데이터의 lagged 복사본과 원본 사이의 상관 관계를 측정합니다.
$\rho_k = \frac{Cov(X_t, X_{t+k})}{\sqrt{Var[X_t]*Var[X_{t+k}]}}$
PACF(Partial Autocorrelation Function) Plot - 시각화
-
시간차(lag)가 늘어나면서 관측치 간의 상관 관계가 어떻게 변하는지 설명 합니다.
-
원리적으로, PACF는 선형 회귀분석을 통해 계산됩니다.
각 시차의 관측치를 이전 시차들의 관측치로 선형 회귀분석하고, 이때의 회귀 계수를 PACF로 간주합니다. 이렇게 하면, PACF는 이전 시차들의 영향을 배제하고 특정 시차만의 자기상관을 측정할 수 있습니다.
분석 tip 1. AR 모델의 차수 결정
- PACF를 사용하면 AR 모델의 차수 를 결정하는 데 도움이 될 수 있습니다.
수식
- PACF는 다른 모든 시점의 영향을 배제하고 두 시점 사이의 상관 관계를 측정합니다.
$\phi_{kk} = Cor r(X_t, X_{t+k} | X_{t+1}, …, X_{t+k-1})$
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
fig, axes = plt.subplots(1, 2)
fig.set_size_inches(12, 4)
# ACF Plot
plot_acf(data, lags=30, ax=axes[0])
# PACF Plot
plot_pacf(data, lags=10, zero=False, ax=axes[1])
for ax in axes:
ax.set_ylim(-0.5, 1.25)
plt.show()

정상성 검증
kpss test
-
귀무가설: 해당 시계열은 정상(stationary) 시계열이다. <-> 대립가설: 해당 시계열은 비정상(non-stationary) 시계열이다.
-
p-value <= 0.05: 귀무가설 기각/ 대립가설 채택 -> 비정상(non-stationary) 시계열. -
p-value > 0.05: 귀무가설 채택/ 대립가설 기각 -> 정상(stationary) 시계열.
-
from statsmodels.tsa.stattools import kpss
def kpss_test(series, **kw):
stats, p_value, nlags, critical_values = kpss(series, **kw)
print(f'KPSS Stat: {stats:.5f}')
print(f'p-value: {p_value:.2f}')
print(f'Lags: {nlags}')
print(f'검증결과: {"비정상(non-stationary)" if p_value <= 0.05 else "정상(stationary)"} 시계열 데이터입니다.')
kpss_test(data, nlags=30)
KPSS Stat: 1.18454 p-value: 0.01 Lags: 30 검증결과: 비정상(non-stationary) 시계열 데이터입니다.
# 1차 차분에 대한 결과
diff_1 = data.diff(periods=1).iloc[1:]
kpss_test(diff_1, nlags=30)
KPSS Stat: 0.29060 p-value: 0.10 Lags: 30 검증결과: 정상(stationary) 시계열 데이터입니다.
# 1차 차분 결과에 대한 시각화
fig, axes = plt.subplots(1, 1)
fig.set_size_inches(8, 4)
# ACF Plot
plot_acf(diff_1, lags=30, ax=axes)
axes.set_ylim(-0.5, 1.25)
plt.show()

Adfuller 테스트
-
kpss test 와 귀무가설이 반대입니다.
-
귀무가설: 해당 시계열은 비정상(non-stationary) 시계열이다. <-> 대립가설: 해당 시계열은 정상(stationary) 시계열이다.
-
p-value <= 0.05: 귀무가설 기각/ 대립가설 채택 -> 정상(stationary) 시계열. -
p-value > 0.05: 귀무가설 채택/ 대립가설 기각 -> 비정상(non-stationary) 시계열.
-
# 데이터 정상 상태 수치 확인
from statsmodels.tsa.stattools import adfuller #ADF Test를 위한 함수 호출
st_result = adfuller(data)
def adfuller_test(series, **kw):
adf, p_value, nlags, number_of_observations, critical_values, _ = adfuller(series, **kw)
print(f'ADF: {adf:.5f}')
print(f'p-value: {p_value:.2f}')
print(f'Lags: {nlags}')
print(f'Number of Observations: {number_of_observations}')
print(f'검증결과: {"비정상(non-stationary)" if p_value > 0.05 else "정상(stationary)"} 시계열 데이터입니다.')
# Adfuller 테스트
adfuller_test(data, maxlag=30)
ADF: -1.44857 p-value: 0.56 Lags: 0 Number of Observations: 1095 검증결과: 비정상(non-stationary) 시계열 데이터입니다.
# 1차 차분에 대한 Adfuller 테스트
adfuller_test(diff_1, maxlag=30)
ADF: -10.34401 p-value: 0.00 Lags: 8 Number of Observations: 1086 검증결과: 정상(stationary) 시계열 데이터입니다.
ARIMA Model
시계열 데이터 분석에서는 AR(AutoRegressive), MA(Moving Average), ARMA(AutoRegressive Moving Average), ARIMA(AutoRegressive Integrated Moving Average) 등의 모델이 있습니다.
-
AR (AutoRegressive): 이전 관측치의 값들이 현재 관측치에 영향을 주는 모델입니다. 예를 들어, AR(1) 모델은 현재 관측치가 바로 이전 관측치에 의해 영향을 받는다는 것을 나타냅니다. AR 모델은 파라미터 p로 몇 개의 이전 관측치를 고려할지를 결정합니다.
-
MA (Moving Average): 이전 오차항들이 현재 관측치에 영향을 주는 모델입니다. MA(1) 모델은 현재 관측치가 바로 이전의 오차항에 의해 영향을 받는다는 것을 나타냅니다. MA 모델은 파라미터 q로 몇 개의 이전 오차항을 고려할지를 결정합니다.
AR & MA 모델의 차이
AR(AutoRegressive) 모델과 MA(Moving Average) 모델은 둘 다 시계열 분석에서 널리 사용되는 모델이지만, 그 방식이 다릅니다.
AR 모델
- AR 모델은 ‘자기회귀 모델’ 로, 과거의 자신의 값에 의존하여 현재 값을 예측하는 방법을 사용합니다. 즉, 이전 시점의 관측값이 현재 시점의 관측값에 영향을 줍니다.
- 예를 들어,
주식 시장에서 어제 주가가 상승했다면 오늘 주가도 상승할 가능성이 있다는 것이 AR 모델의 관점입니다.
AR 모델은 파라미터 p로 이전 몇 개의 관측치를 고려할지 결정 하게 됩니다. AR(1) 모델은 바로 이전의 한 단계 관측치를 고려하고, AR(2) 모델은 바로 이전의 두 단계 관측치를 고려하게 됩니다.
(예시)
예를 들어, 전력 소비를 예측하는 문제를 생각해 보겠습니다. 사람들은 특정 시간대에 일관되게 전력을 사용하는 경향이 있습니다. 아침에 사람들이 일어나서 활동을 시작하면 전력 사용량이 증가하고, 밤에 사람들이 잠에 들면 전력 사용량이 감소합니다. 이러한 경우, AR 모델은 이전 시간대의 전력 사용 패턴을 학습하여 다음 시간대의 전력 사용량을 예측하는 데 사용 될 수 있습니다.
MA 모델
- MA 모델은 ‘이동 평균 모델’ 로, 과거의 오차항에 의존하여 현재 값을 예측합니다.
- 예를 들어, 우리가 날씨를 예측한다고 가정해 봅시다.
오늘의 기온 예측치가 실제 기온보다 더 높았다면, 이는 오차를 의미합니다. MA 모델에 따르면, 이 오차는 내일의 기온 예측에 반영되어야 합니다. 즉, 오늘 예측이 너무 높았다면, 내일의 예측치는 그 오차를 보정하기 위해 조금 더 낮아질 것입니다.
MA 모델은 파라미터 q로 이전 몇 개의 오차항을 고려할지 결정하게 됩니다. MA(1) 모델은 바로 이전의 한 단계 오차항 을 고려하고, MA(2) 모델은 바로 이전의 두 단계 오차항 을 고려하게 됩니다.
즉, AR 모델은 자신의 과거 값을, MA 모델은 과거의 예측 오차를 사용하여 현재 값을 예측하는 방법론입니다. 어떤 모델을 사용할지는 주로 데이터의 특성과 목표에 따라 결정됩니다.
(예시)
매장의 판매량 예측을 예로 들어 보겠습니다. 이전의 판매 예측이 과소평가되었다면 (즉, 실제 판매량이 예측보다 높았다면), 그 다음날의 판매량 예측을 증가시키는 것이 합리적일 수 있습니다. 반대로, 이전의 판매 예측이 과대평가 되었다면 (즉, 실제 판매량이 예측보다 낮았다면), 그 다음날의 판매량 예측을 감소시키는 것이 합리적 일 수 있습니다. 이런 상황에서는 MA 모델이 유용하게 사용될 수 있습니다.
ARMA, ARIMA
-
ARMA (AutoRegressive Moving Average): AR 모델과 MA 모델의 결합으로, 이전 관측치와 이전 오차항 모두를 고려하는 모델입니다. ARMA 모델은 두 파라미터 p와 q를 모두 사용합니다.
-
ARIMA (AutoRegressive Integrated Moving Average): ARMA 모델에 비정상 시계열을 정상 시계열로 변환하는 과정을 포함한 모델입니다. 이 변환 과정은 차분(differencing)이라고 하며, 몇 차 차분을 사용할지를 결정하는 파라미터가 d입니다. 따라서 ARIMA 모델은 세 파라미터 p, d, q를 모두 사용합니다.
ARIMA 적용시 고려사항
-
AR(p) = ARIMA(p, 0, 0)
-
MA(q) = ARIMA(0, 0, q)
-
ARMA(p, q) = ARIMA(p, 0, q)
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
import itertools
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
p = range(0, 4)
d = range(0, 3)
q = range(0, 5)
pdq = list(itertools.product(p,d,q))
aic = []
params = []
with tqdm(total=len(pdq)) as pg:
for i in pdq:
pg.update(1)
try:
model = ARIMA(data, order=(i)).fit()
aic.append(round(model.aic, 2))
params.append((i))
except:
continue
100%|███████████████████████████████████████████| 60/60 [00:22<00:00, 2.66it/s]
가장 Optimal 한 (p, d, q) 하이퍼 파라미터를 찾습니다.
optimal = [(params[i],j) for i,j in enumerate(aic) if j == min(aic)]
arima = ARIMA(data, order = optimal[0][0], freq='D').fit()
arima.summary()
| Dep. Variable: | Close | No. Observations: | 1096 |
|---|---|---|---|
| Model: | ARIMA(2, 2, 3) | Log Likelihood | -9369.370 |
| Date: | Mon, 03 Jul 2023 | AIC | 18750.740 |
| Time: | 01:46:18 | BIC | 18780.726 |
| Sample: | 01-01-2020 | HQIC | 18762.087 |
| - 12-31-2022 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | -1.9073 | 0.014 | -137.751 | 0.000 | -1.934 | -1.880 |
| ar.L2 | -0.9732 | 0.014 | -71.464 | 0.000 | -1.000 | -0.946 |
| ma.L1 | 0.8959 | 0.030 | 29.584 | 0.000 | 0.837 | 0.955 |
| ma.L2 | -0.9402 | 0.046 | -20.326 | 0.000 | -1.031 | -0.850 |
| ma.L3 | -0.9557 | 0.028 | -34.322 | 0.000 | -1.010 | -0.901 |
| sigma2 | 1.637e+06 | 8.1e-08 | 2.02e+13 | 0.000 | 1.64e+06 | 1.64e+06 |
| Ljung-Box (L1) (Q): | 0.03 | Jarque-Bera (JB): | 1219.10 |
|---|---|---|---|
| Prob(Q): | 0.86 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 5.39 | Skew: | -0.19 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 8.16 |
arima_model = ARIMA(data, order=optimal[0][0], freq='D').fit()
forecast = arima_model.forecast(steps=10)
fig, ax = plt.subplots(1, 1)
fig.set_size_inches(10, 5)
fig.set_dpi(300)
ax.plot(data.index, data, color=COLORS['green'])
ax.plot(forecast, color=COLORS['red'])
plt.show()

결과를 시각화 합니다. 다음의 시각화 결과는 향후 15일 치 데이터에 대한 예측 결과입니다.
fig, axes = plt.subplots(1, 2)
fig.set_size_inches(12, 6)
fig.set_dpi(300)
# number of prediction days
n_futures = 15
freq = 'D'
future_idx = pd.date_range(data.index[-1], periods=n_futures+1, freq=freq)[-n_futures:]
forecast = arima_model.fittedvalues
forecast_futures = arima_model.forecast(steps=n_futures)
axes[0].plot(data.index, data, label='data', color=COLORS['black'], linestyle='dotted', alpha=0.5)
axes[0].plot(data.index, forecast, label='fitted', color=COLORS['green'], linestyle='solid', alpha=0.5)
axes[0].set_title('Fitted Result')
axes[0].set_xticklabels(mdates.num2date(axes[0].get_xticks()), rotation = 45)
axes[0].xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
axes[1].plot(future_idx, forecast_futures, color=COLORS['red'], label='prediction')
axes[1].plot(data.index[-30:], data[-30:], color=COLORS['black'], linestyle='dotted', label='real')
axes[1].set_title(f'Predict Next {n_futures} days')
axes[1].set_xticklabels(mdates.num2date(axes[1].get_xticks()), rotation = 45)
axes[1].xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
# plt.xticks(rotation=45)
plt.legend()
plt.tight_layout()
plt.show()

SARIMAX
SARIMAX: Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors
주요 하이퍼파라미터
-
AR(AutoRegressive):
이전 관측치의 값을 사용하여 현재 값을 예측하는데 사용되는 모델입니다. -
I(Integrated): 시계열의 비정상성을 처리하기 위해 사용되는
차분(Differencing)단계를 나타냅니다. -
MA(Moving Average): 이전
오차항의 평균을 사용하여 현재 값을 예측하는데 사용되는 모델입니다. -
Seasonality:
계절성 요인을 고려한 모델입니다. 예를 들어, 연간 패턴, 월간 패턴, 주간 패턴 등을 모델링 할 수 있습니다. -
Exogenous: 시계열에 영향을 주는
외부 변수를 고려하는 모델입니다.
ARIMA 모델은 AR, I, MA의 세 가지 구성요소만을 포함합니다. 따라서 계절성과 외생변수는 ARIMA 모델로는 처리하기 어렵습니다. 이 때문에 이러한 요소를 고려해야 하는 복잡한 시계열 데이터를 분석할 때는 ARIMA 보다는 SARIMAX와 같은 확장된 모델 을 사용하는 것이 적합할 수 있습니다.
즉, ARIMA와 SARIMAX의 주요 차이점은 SARIMAX가 ARIMA에 비해 계절성 과 외생변수를 모델링할 수 있다는 점입니다. 이로 인해 SARIMAX는 ARIMA보다 더 다양한 시계열 데이터를 분석할 수 있으며, 이에 따라 예측의 정확성을 높일 수 있습니다.
공식문서: https://www.statsmodels.org/dev/generated/statsmodels.tsa.statespace.sarimax.SARIMAX.html
sarimax = SARIMAX(data, order=(2, 2, 3), season_order = (1, 1, 2, 14)).fit(disp=False)
forecast = sarimax.forecast(steps=30)
plt.figure(figsize=(10, 5))
plt.plot(data.index, data, label='real', color=COLORS['green'])
plt.plot(forecast, label='predict', color=COLORS['red'])
plt.legend()
plt.show()

Finance DataReader 라이브러리를 활용하여 금 선물가격 과 코스피 지수 데이터를 가져와서 병합하도록 하겠습니다.
# 금 선물
gold = fdr.DataReader('ZG')
# 금 선물 데이터 컬럼 변환
gold = gold['Close'].reset_index().rename(columns={'Close': 'Gold'})
gold
| Date | Gold | |
|---|---|---|
| 0 | 2011-07-20 | 11.154 |
| 1 | 2011-07-21 | 10.352 |
| 2 | 2011-07-22 | 10.686 |
| 3 | 2011-07-25 | 11.101 |
| 4 | 2011-07-26 | 11.360 |
| ... | ... | ... |
| 3002 | 2023-06-26 | 48.190 |
| 3003 | 2023-06-27 | 49.980 |
| 3004 | 2023-06-28 | 51.390 |
| 3005 | 2023-06-29 | 49.010 |
| 3006 | 2023-06-30 | 49.200 |
3007 rows × 2 columns
# 코스피 데이터
kospi = fdr.DataReader('KS11')
# 코스피 데이터 병합
kospi = kospi['Close'].reset_index().rename(columns={'Close': 'Kospi'})
kospi
| Date | Kospi | |
|---|---|---|
| 0 | 1996-12-11 | 704.680 |
| 1 | 1996-12-12 | 689.380 |
| 2 | 1996-12-13 | 689.070 |
| 3 | 1996-12-16 | 673.920 |
| 4 | 1996-12-17 | 663.350 |
| ... | ... | ... |
| 6689 | 2023-06-26 | 2,582.200 |
| 6690 | 2023-06-27 | 2,581.390 |
| 6691 | 2023-06-28 | 2,564.190 |
| 6692 | 2023-06-29 | 2,550.020 |
| 6693 | 2023-06-30 | 2,564.280 |
6694 rows × 2 columns
# Kospi 데이터와 금값 시세 데이터 병합
kospi_gold = pd.merge(kospi, gold, how='left')
kospi_gold
| Date | Kospi | Gold | |
|---|---|---|---|
| 0 | 1996-12-11 | 704.680 | NaN |
| 1 | 1996-12-12 | 689.380 | NaN |
| 2 | 1996-12-13 | 689.070 | NaN |
| 3 | 1996-12-16 | 673.920 | NaN |
| 4 | 1996-12-17 | 663.350 | NaN |
| ... | ... | ... | ... |
| 6689 | 2023-06-26 | 2,582.200 | 48.190 |
| 6690 | 2023-06-27 | 2,581.390 | 49.980 |
| 6691 | 2023-06-28 | 2,564.190 | 51.390 |
| 6692 | 2023-06-29 | 2,550.020 | 49.010 |
| 6693 | 2023-06-30 | 2,564.280 | 49.200 |
6694 rows × 3 columns
병합한 데이터에서 결측치가 관측됩니다. 결측치를 interpolate() 으로 결측치를 채우도록 하겠습니다.
kospi_gold['Gold'] = kospi_gold['Gold'].interpolate().bfill()
kospi_gold['Kospi'] = kospi_gold['Kospi'].interpolate().bfill()
kospi_gold
| Date | Kospi | Gold | |
|---|---|---|---|
| 0 | 1996-12-11 | 704.680 | 11.154 |
| 1 | 1996-12-12 | 689.380 | 11.154 |
| 2 | 1996-12-13 | 689.070 | 11.154 |
| 3 | 1996-12-16 | 673.920 | 11.154 |
| 4 | 1996-12-17 | 663.350 | 11.154 |
| ... | ... | ... | ... |
| 6689 | 2023-06-26 | 2,582.200 | 48.190 |
| 6690 | 2023-06-27 | 2,581.390 | 49.980 |
| 6691 | 2023-06-28 | 2,564.190 | 51.390 |
| 6692 | 2023-06-29 | 2,550.020 | 49.010 |
| 6693 | 2023-06-30 | 2,564.280 | 49.200 |
6694 rows × 3 columns
data 와 kospi_gold 데이터를 병합합니다.
data_merged = pd.merge(data, kospi_gold, left_on=data.index, right_on=kospi_gold['Date'], how='left').drop('Date', axis=1)
data_merged = data_merged.rename(columns={'key_0': 'Date'})
data_merged
| Date | Close | Kospi | Gold | |
|---|---|---|---|---|
| 0 | 2020-01-01 | 7,200.174 | NaN | NaN |
| 1 | 2020-01-02 | 6,985.470 | 2,175.170 | 45.000 |
| 2 | 2020-01-03 | 7,344.884 | 2,176.460 | 44.560 |
| 3 | 2020-01-04 | 7,410.657 | NaN | NaN |
| 4 | 2020-01-05 | 7,411.317 | NaN | NaN |
| ... | ... | ... | ... | ... |
| 1091 | 2022-12-27 | 16,717.174 | 2,332.790 | 31.540 |
| 1092 | 2022-12-28 | 16,552.572 | 2,280.450 | 30.390 |
| 1093 | 2022-12-29 | 16,642.342 | 2,236.400 | 31.100 |
| 1094 | 2022-12-30 | 16,602.586 | NaN | NaN |
| 1095 | 2022-12-31 | 16,547.496 | NaN | NaN |
1096 rows × 4 columns
# Gold, Kospi 의 결측치를 채웁니다.
data_merged['Gold'] = data_merged['Gold'].interpolate().bfill()
data_merged['Kospi'] = data_merged['Kospi'].interpolate().bfill()
data_merged
| Date | Close | Kospi | Gold | |
|---|---|---|---|---|
| 0 | 2020-01-01 | 7,200.174 | 2,175.170 | 45.000 |
| 1 | 2020-01-02 | 6,985.470 | 2,175.170 | 45.000 |
| 2 | 2020-01-03 | 7,344.884 | 2,176.460 | 44.560 |
| 3 | 2020-01-04 | 7,410.657 | 2,169.330 | 44.517 |
| 4 | 2020-01-05 | 7,411.317 | 2,162.200 | 44.473 |
| ... | ... | ... | ... | ... |
| 1091 | 2022-12-27 | 16,717.174 | 2,332.790 | 31.540 |
| 1092 | 2022-12-28 | 16,552.572 | 2,280.450 | 30.390 |
| 1093 | 2022-12-29 | 16,642.342 | 2,236.400 | 31.100 |
| 1094 | 2022-12-30 | 16,602.586 | 2,236.400 | 31.100 |
| 1095 | 2022-12-31 | 16,547.496 | 2,236.400 | 31.100 |
1096 rows × 4 columns
SARIMAX 모델로 학습하고, 예측 후 검증결과를 확인하기 위하여 데이터셋을 분할합니다.
- 30일 기준으로 분할하여,
train데이터로 학습된 모델로test데이터를 예측하도록 하겠습니다.
# train / test 분할
train_data = data_merged[:-30]
test_data = data_merged[-30:]
# 향후 30일의 데이터에 대한 예측
n_predictions = 30
sarimax = SARIMAX(train_data['Close'],
exog=train_data[['Gold', 'Kospi']],
order=(2, 2, 3),
season_order = (1, 1, 2, 14)).fit(disp=False)
forecast = sarimax.forecast(steps=30, exog=test_data[['Gold', 'Kospi']])
fig, axes = plt.subplots(1, 2)
fig.set_size_inches(12, 5)
fig.set_dpi(300)
axes[0].plot(train_data['Date'], train_data['Close'], label='real', color=COLORS['green'])
axes[0].plot(test_data['Date'], forecast, label='predict', color=COLORS['red'])
axes[0].set_xlim(pd.Timestamp('2020-09-01'), )
# Tick을 날짜형식으로 변환
axes[0].set_xticklabels(mdates.num2date(axes[0].get_xticks()), rotation = 45)
axes[0].xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
axes[0].set_title('Overall Time Series')
axes[0].legend()
axes[1].plot(train_data['Date'], train_data['Close'], label='real', color=COLORS['green'])
axes[1].plot(test_data['Date'], forecast, label='predict', color=COLORS['red'])
axes[1].set_xlim(pd.Timestamp('2022-11-01'), pd.Timestamp('2023-01-15'))
# Tick을 날짜형식으로 변환
axes[1].set_xticklabels(mdates.num2date(axes[1].get_xticks()), rotation = 45)
axes[1].xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m'))
axes[1].set_title(f'Predict Next {n_predictions} days')
axes[1].legend()
plt.tight_layout()
plt.legend()
plt.show()

SARIMAX 하이퍼파라미터 튜닝
p = range(0, 5) # AR
d = range(1, 3) # 차분
q = range(0, 4) # MA
m = 30 # 계절성 주기(Seasonal Trends)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], m) for x in list(itertools.product(p, d, q))]
aic = []
params = []
with tqdm(total = len(pdq) * len(seasonal_pdq)) as pg:
for i in pdq:
for j in seasonal_pdq:
pg.update(1)
try:
model = SARIMAX(train_data['Close'],
exog=train_data[['Gold', 'Kospi']],
order=(i),
season_order = (j)).fit(disp=False)
aic.append(round(model.aic, 2))
params.append((i,j))
except:
print('Error Occured..')
continue
100%|███████████████████████████████████████| 1600/1600 [17:53<00:00, 1.49it/s]
# 향후 30일의 데이터에 대한 예측
n_predictions = 30
optimal = [(params[i], j) for i, j in enumerate(aic) if j == min(aic)]
sarimax_tunned = SARIMAX(train_data['Close'],
exog=train_data[['Gold', 'Kospi']],
order = optimal[0][0][0],
seasonal_order = optimal[0][0][1]).fit(disp=False)
sarimax_tunned.summary()
| Dep. Variable: | Close | No. Observations: | 1066 |
|---|---|---|---|
| Model: | SARIMAX(2, 1, 2)x(0, 1, [], 30) | Log Likelihood | -9211.826 |
| Date: | Mon, 03 Jul 2023 | AIC | 18437.652 |
| Time: | 02:04:26 | BIC | 18472.247 |
| Sample: | 0 | HQIC | 18450.778 |
| - 1066 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Gold | 80.1426 | 12.380 | 6.474 | 0.000 | 55.879 | 104.406 |
| Kospi | 0.4043 | 1.656 | 0.244 | 0.807 | -2.842 | 3.651 |
| ar.L1 | -1.8651 | 0.012 | -150.177 | 0.000 | -1.889 | -1.841 |
| ar.L2 | -0.9719 | 0.012 | -81.006 | 0.000 | -0.995 | -0.948 |
| ma.L1 | 1.8475 | 0.013 | 140.016 | 0.000 | 1.822 | 1.873 |
| ma.L2 | 0.9670 | 0.013 | 75.694 | 0.000 | 0.942 | 0.992 |
| sigma2 | 3.265e+06 | 4.59e-05 | 7.11e+10 | 0.000 | 3.27e+06 | 3.27e+06 |
| Ljung-Box (L1) (Q): | 1.17 | Jarque-Bera (JB): | 242.89 |
|---|---|---|---|
| Prob(Q): | 0.28 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 5.96 | Skew: | 0.02 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 5.37 |
sarimax_tunned.forecast(steps=n_predictions, exog=test_data[['Gold', 'Kospi']])
1066 16,750.097 1067 16,527.811 1068 17,467.031 1069 17,493.765 1070 17,086.020 1071 16,559.103 1072 14,505.218 1073 11,872.131 1074 13,345.895 1075 12,583.305 1076 12,389.935 1077 12,193.529 1078 12,474.401 1079 12,560.788 1080 12,330.134 1081 12,341.078 1082 12,425.906 1083 12,470.121 1084 11,983.324 1085 11,553.372 1086 11,896.263 1087 12,174.399 1088 12,190.526 1089 12,071.561 1090 12,055.353 1091 11,979.975 1092 11,682.838 1093 11,908.014 1094 12,426.192 1095 12,175.555 Name: predicted_mean, dtype: float64
예측 결과 시각화
forecast = sarimax_tunned.forecast(steps=n_predictions, exog=test_data[['Gold', 'Kospi']])
plt.figure(figsize=(10, 5))
plt.plot(data.index, data, label='real', color='#1AA341', alpha=0.5)
plt.plot(test_data['Date'], forecast, label='predict', color='#F02828')
plt.axvline(x = pd.Timestamp('2022-12-02'), color = 'blue', label = 'After Prediction', linestyle='dotted')
plt.xlim(pd.Timestamp('2022-11-01'), )
plt.ylim(10000, 25000)
plt.xticks(rotation=45)
plt.legend()
plt.show()

시계열 성분 분해 (Seasonal Decomposition)
시계열 데이터 분석에서 성분 분해(Decomposition)는 관측된 시계열 데이터를 여러 성분으로 나누는 것을 의미합니다. 이는 시계열 데이터에 있는 복잡한 패턴을 이해하고 분석하는 데 도움이 됩니다. 주로 데이터를 추세(Trend), 계절성(Seasonality), 그리고 잔차(Redisual)/불규칙성(Irregularity) 으로 분해합니다.
-
추세 성분(Trend Component) : 이는 시계열 데이터의 장기적인 패턴 을 의미합니다. 예를 들어, 회사의 매출이 시간이 지남에 따라 전반적으로 증가하거나 감소하는 경향이 있다면, 이를 추세라고 합니다. 추세는 일반적으로 선형적일 수도 있고, 비선형적일 수도 있습니다.
-
계절 성분(Seasonal Component) : 이는 시계열 데이터에서 반복적으로 나타나는 패턴 을 의미합니다. 예를 들어, 매년 여름에 아이스크림 판매가 증가하는 것이 계절성의 예입니다. 계절성은 일반적으로 연간, 분기별, 월별, 주별, 일별 등 주기적으로 나타납니다.
-
불규칙 성분(Irregular Component) : 이는 추세나 계절성에 의해 설명되지 않는 잔차(Residual) 를 의미합니다. 불규칙성은 랜덤 노이즈일 수도 있고, 데이터에 있는 예측 불가능한 변동성일 수도 있습니다. 예를 들어, 예측할 수 없는 이벤트(자연재해, 금융위기 등)에 의한 판매량의 변동이 이에 해당됩니다.
additive 방식을 활용한 분해
$Y_t = T_t + S_t + I_t$
-
시계열 데이터가 선형적인 형태 라는 가정하에 데이터를 분해합니다.
-
즉, 데이터에서의 추세, 계절성, 그리고 잔차가 더해져 원래의 시계열 데이터를 구성한다는 가정입니다.
이는 시계열 데이터의 계절적 효과가 시간이 흐름에 따라 일정하게 유지되는 경우에 적합합니다.
import statsmodels.api as sm
# additive 방식을 활용한 분해
decomposition = sm.tsa.seasonal_decompose(data, model='additive', period=365)
fig = decomposition.plot()
fig.set_dpi(300)
fig.set_tight_layout('constrained')
fig.set_size_inches(10, 6)
plt.show()

Multiplicative Model
$Y_t = T_t \times S_t \times I_t$
이 모델은 세 가지 성분이 곱해져서 시계열 데이터를 구성한다고 가정합니다
-
시계열 데이터가 비선형적인 형태, 특히 시간이 지남에 따라 계절적 효과가 증가하거나 감소하는 경우에 적합합니다.
-
즉, 데이터에서의 추세, 계절성, 그리고 잔차가 곱해져 원래의 시계열 데이터를 구성한다는 가정입니다.
(주의) multiplicative 모델을 사용하기 위해서는 데이터에 0이 존재해서는 안됩니다.
decomposition = sm.tsa.seasonal_decompose(data, model='multiplicative', period=365)
fig = decomposition.plot()
fig.set_dpi(300)
fig.set_tight_layout('constrained')
fig.set_size_inches(10, 6)
plt.show()

additive 와 multiplicative의 차이
additive 모델은 시간에 따라 빈도와 진폭이 변하지 않는다는 점에 유의하세요.
multiplicative 모델은 이 두 번째 모델에서 행동이 증가하는 깔때기 역할을 합니다(감소할 수도 있음).
-
additive는Trend와Seasonality를 별개로 보고, -
multiplicative는Trend에 따라Seasonality도 변화한다고 보면 됩니다.
따라서 데이터의 계절적 패턴의 크기가 데이터의 크기에 따라 달라지는 경우 multiplicative 모델을 사용합니다. 반면, additive 모델에서는 계절성의 크기가 시간에 따라 변하지 않습니다.
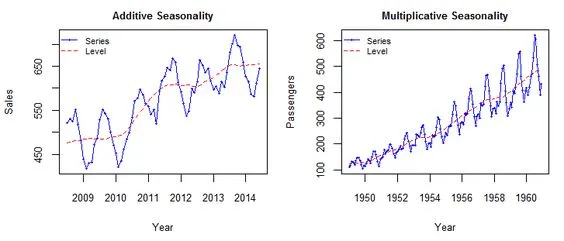
출처: https://sigmundojr.medium.com/seasonality-in-python-additive-or-multiplicative-model-d4b9cf1f48a7
댓글남기기