🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
[pytorch] 토큰화(Tokenizing), Embedding + LSTM 모델을 활용한 텍스트 분류 예측
이번 튜토리얼에서는 sarcasm 데이터셋을 활용하여 뉴스 기사의 제목(headline) 텍스트를 학습하여 sarcastic(1) 인지 normal(0) 인지 판별하는 텍스트 분류기를 생성하고, 학습 및 추론까지 진행합니다.
체크리스트
- 튜토리얼의 전반부에서는 텍스트 데이터의 자연어 전처리 방법인 토큰화(tokenization) 에 대해서 다룹니다. Tokenizer 는
basic_english를 사용하지만, 추후에는 다른 Tokenizer 로 대체해 보시는 것을 추천 드립니다. - torch의
nn.Embedding()의 입출력 차원,nn.LSTM()의 입출력 차원에 대하여 꼼꼼히 이해할 수 있도록 주석을 최대한 상세히 달아놓았습니다.
시드 고정
import os
import random
import numpy as np
import torch
# 시드설정
SEED = 123
def seed_everything(seed=SEED):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(SEED)
샘플 예제파일 다운로드
import urllib
url = 'https://storage.googleapis.com/download.tensorflow.org/data/sarcasm.json'
urllib.request.urlretrieve(url, 'sarcasm.json')
('sarcasm.json', <http.client.HTTPMessage at 0x7f98981ab6d0>)
데이터 로드
import json
from tqdm import tqdm
import numpy as np
import pandas as pd
with open('sarcasm.json') as f:
datas = json.load(f)
df = pd.DataFrame(datas)
df.head()
| article_link | headline | is_sarcastic | |
|---|---|---|---|
| 0 | https://www.huffingtonpost.com/entry/versace-b... | former versace store clerk sues over secret 'b... | 0 |
| 1 | https://www.huffingtonpost.com/entry/roseanne-... | the 'roseanne' revival catches up to our thorn... | 0 |
| 2 | https://local.theonion.com/mom-starting-to-fea... | mom starting to fear son's web series closest ... | 1 |
| 3 | https://politics.theonion.com/boehner-just-wan... | boehner just wants wife to listen, not come up... | 1 |
| 4 | https://www.huffingtonpost.com/entry/jk-rowlin... | j.k. rowling wishes snape happy birthday in th... | 0 |
토큰화 (Word Tokenization)
-
get_tokenizer로 토크나이저 생성
-
basic_english,spacy,revtok,subword등 지정이 가능하나, 몇몇 토크나이저는 추가 라이브러리 설치가 필요합니다.
from torchtext.data.utils import get_tokenizer
# 토큰 생성
tokenizer = get_tokenizer('basic_english')
토큰화한 결과는 특수문자는 개별 토큰으로 처리, 모든 단어는 소문자로 처리됩니다.
tokenizer('Hi, my name is Teddy!!!')
['hi', ',', 'my', 'name', 'is', 'teddy', '!', '!', '!']
tokenizer('Hello, I would love to learn Python!')
['hello', ',', 'i', 'would', 'love', 'to', 'learn', 'python', '!']
tokenizer('안녕하세요? 한글 데이터에 대한 토큰 처리는 어떨까요??')
['안녕하세요', '?', '한글', '데이터에', '대한', '토큰', '처리는', '어떨까요', '?', '?']
단어사전 생성
from torchtext.vocab import build_vocab_from_iterator
def yield_tokens(sentences):
for text in sentences:
yield tokenizer(text)
build_vocab_from_iterator 를 활용하여 단어 사전을 생성합니다.
-
min_freq: 최소 빈도의 토큰의 개수를 입력합니다. -
max_tokens: 최대 빈도 토큰의 수를 한정합니다. 빈도수 기준으로 산정합니다.
vocab = build_vocab_from_iterator(yield_tokens(df['headline'].tolist()), # 텍스트 Iterator
specials=['<UNK>'], # 스페셜 토큰
min_freq=2, # 최소 빈도 토큰
max_tokens=1000, # 최대 토큰 개수
)
vocab.set_default_index(vocab['<UNK>'])
# 전체 단어사전의 개수 출력
len(vocab)
1000
# string -> index
stoi = vocab.get_stoi()
# index -> string
itos = vocab.get_itos()
itos[0]
'<UNK>'
itos[15]
'trump'
stoi['trump']
15
sample_sentence = 'Hello, I am Teddy. Nice to meet you!!'
stoi['i']
50
tokenizer(sample_sentence)
['hello', ',', 'i', 'am', 'teddy', '.', 'nice', 'to', 'meet', 'you', '!', '!']
vocab(tokenizer(sample_sentence))
[0, 7, 50, 0, 0, 11, 0, 2, 423, 20, 141, 141]
Dataset 분할
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df['headline'], df['is_sarcastic'],
stratify=df['is_sarcastic'],
test_size=0.2,
random_state=SEED
)
Dataset 생성
from torch.utils.data import DataLoader, Dataset
from torchtext.vocab import build_vocab_from_iterator
class CustomDataset(Dataset):
def __init__(self, texts, labels, vocab, tokenizer):
super().__init__()
self.texts = texts
self.labels = labels
self.vocab = vocab
self.tokenizer = tokenizer
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
text = self.texts.iloc[idx]
label = self.labels.iloc[idx]
return self.vocab(self.tokenizer(text)), label
# Custom Dataset 생성
train_ds = CustomDataset(x_train, y_train, vocab=vocab, tokenizer=tokenizer)
valid_ds = CustomDataset(x_test, y_test, vocab=vocab, tokenizer=tokenizer)
# 1개의 데이터 추출
text, label = next(iter(train_ds))
len(text), label
(10, 1)
DataLoader 생성
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
cuda
def collate_batch(batch, max_sequence_length):
label_list, text_list = [], []
for text, label in batch:
# 최대 문장길이를 넘어가는 단어는 제거합니다.
processed_text = torch.tensor(text[:max_sequence_length], dtype=torch.int64)
text_list.append(processed_text)
label_list.append(label)
label_list = torch.tensor(label_list, dtype=torch.int64)
# padding을 주어 짧은 문장에 대한 길이를 맞춥니다.
text_list = pad_sequence(text_list, batch_first=True, padding_value=0)
return text_list.to(device), label_list.to(device)
# 한 문장에 최대 포함하는 단어의 개수를 지정합니다. (예시. 120 단어)
MAX_SEQUENCE_LENGTH = 120
train_loader = DataLoader(train_ds,
batch_size=32,
shuffle=True,
collate_fn=lambda x: collate_batch(x, MAX_SEQUENCE_LENGTH))
valid_loader = DataLoader(valid_ds,
batch_size=32,
shuffle=False,
collate_fn=lambda x: collate_batch(x, MAX_SEQUENCE_LENGTH))
x, y = next(iter(train_loader))
x = x.to(device)
y = y.to(device)
x.shape, y.shape
# (batch_size, seq_length), (batch_size)
(torch.Size([32, 19]), torch.Size([32]))
x
tensor([[ 0, 0, 316, 0, 29, 44, 611, 20, 0, 6, 4, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 0, 2, 201, 411, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 7, 0, 0, 0, 761, 29, 32, 0, 301, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[190, 0, 0, 10, 30, 0, 274, 44, 192, 108, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[149, 1, 21, 0, 39, 0, 10, 138, 51, 4, 0, 0, 3, 68,
14, 0, 0, 12, 0],
[102, 38, 157, 3, 4, 110, 413, 0, 3, 793, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 0, 45, 81, 42, 0, 279, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 14, 272, 2, 0, 4, 194, 109, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 0, 726, 106, 52, 0, 0, 2, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 14, 186, 50, 233, 67, 2, 192, 4, 0, 0, 0, 0, 0,
1, 0, 0, 25, 0],
[ 0, 188, 221, 2, 117, 32, 37, 93, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 0, 4, 1, 0, 22, 86, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[530, 165, 6, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 7, 0, 0, 0, 0, 215, 6, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 49, 0, 3, 0, 142, 67, 85, 538, 87, 219, 566, 290, 431, 0,
0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 448, 4, 61, 12, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[710, 1, 5, 0, 0, 432, 208, 2, 0, 0, 300, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 716, 0, 17, 1, 5, 0, 59, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 73, 0, 0, 107, 197, 2, 4, 0, 3, 0, 217, 9, 0, 0,
0, 0, 0, 0, 0],
[373, 113, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 143, 52, 0, 4, 934, 7, 121, 240, 43, 35, 0, 217, 0,
0, 0, 0, 0, 0],
[ 0, 0, 100, 43, 301, 0, 26, 120, 606, 253, 241, 0, 1, 21,
0, 153, 0, 0, 0],
[ 15, 0, 295, 0, 0, 12, 0, 55, 56, 742, 11, 483, 0, 0,
0, 0, 0, 0, 0],
[190, 768, 2, 801, 7, 0, 0, 10, 118, 7, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[414, 355, 1, 5, 0, 0, 0, 18, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 4, 0, 9, 297, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 8, 0, 844, 0, 153, 395, 8, 443, 164, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 13, 0, 0, 396, 0, 0, 860, 19, 16, 75,
0, 0, 0, 0, 0],
[ 0, 277, 1, 215, 3, 0, 1, 35, 326, 85, 24, 634, 0, 0,
0, 0, 0, 0, 0],
[ 1, 15, 0, 1, 0, 4, 56, 18, 39, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 0, 0, 0, 4, 0, 3, 0, 0, 294, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[253, 667, 497, 10, 458, 0, 792, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]], device='cuda:0')
Embedding Layer
NUM_VOCAB = len(vocab)
NUM_VOCAB
1000
x, y = next(iter(train_loader))
x = x.to(device)
y = y.to(device)
x.shape, y.shape
# (batch_size, seq_length), (batch_size)
(torch.Size([32, 19]), torch.Size([32]))
nn.Embedding() 생성
# Embedding: (vocab_size, embedding_dim)
EMBEDDING_DIM = 30 # Dimension을 30 차원으로 설정(hyper-parameter)
embedding = nn.Embedding(len(vocab), EMBEDDING_DIM).to(device)
nn.Embedding() 의 입출력 shape 에 대한 이해
# x : (batch_size, seq_length)
embedding_out = embedding(x)
embedding_out.shape
# embedding_out: (batch_size, seq_length, embedding_dim)
torch.Size([32, 19, 30])
LSTM Layer
- 참고 링크: https://teddylee777.github.io/pytorch/pytorch-lstm/
from IPython.display import Image
Image(url='https://teddylee777.github.io/images/2023-03-05/lstm-shapes-01.png')
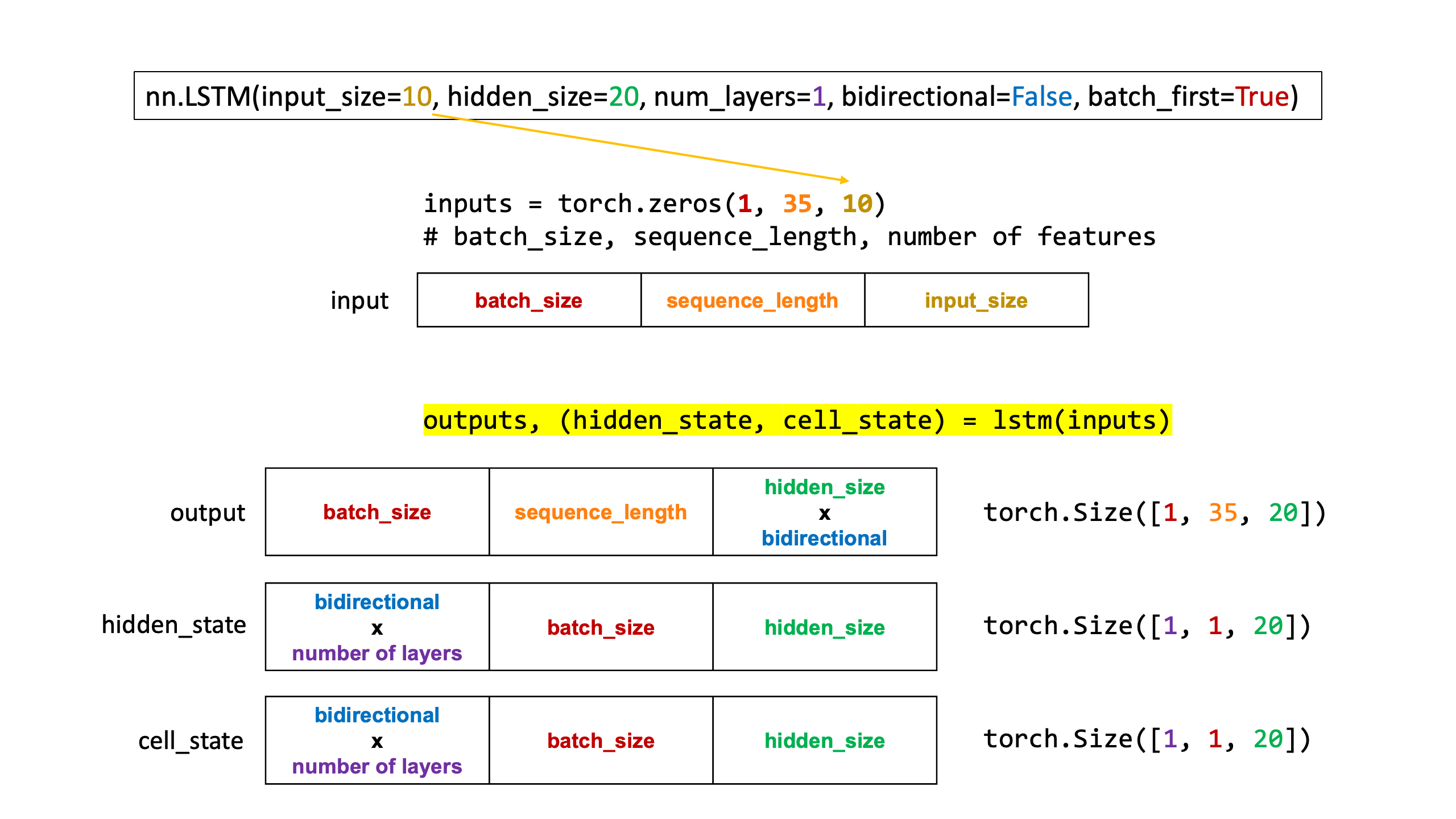
EMBEDDING_DIM = 30 # input_size: embedding_dim(임베딩 차원)
HIDDEN_SIZE = 64 # hidden_size: 추출할 특성의 수(hyper-parameter)
NUM_LAYERS = 1 # LSTM Stacking Layer 수
BIDIRECTIONAL = 1 # 양방향 특성 추출: True(2), False(1)
BATCH_SIZE = x.size(0)
SEQ_LENGTH = x.size(1)
print('BATCH_SIZE: ', BATCH_SIZE)
print('SEQ_LENGTH: ', SEQ_LENGTH)
BATCH_SIZE: 32 SEQ_LENGTH: 19
lstm = nn.LSTM(input_size=EMBEDDING_DIM, hidden_size=HIDDEN_SIZE, batch_first=True, device=device)
lstm
LSTM(30, 64, batch_first=True)
# initial weights 초기화
h_0 = torch.zeros(NUM_LAYERS*BIDIRECTIONAL, SEQ_LENGTH, HIDDEN_SIZE).to(device)
c_0 = torch.zeros(NUM_LAYERS*BIDIRECTIONAL, SEQ_LENGTH, HIDDEN_SIZE).to(device)
embedding_out.shape
torch.Size([32, 19, 30])
# 임베딩 레이어 Output, 초기화 (hidden_state, cell_state)
lstm_out, (hidden, cell) = lstm(embedding_out)
# (batch_size, seq_length, hidden_size)
lstm_out.shape
torch.Size([32, 19, 64])
# (num_layers * bidirectional, batch_size, hidden_size)
# (num_layers * bidirectional, batch_size, hidden_size)
hidden.shape, cell.shape
(torch.Size([1, 32, 64]), torch.Size([1, 32, 64]))
Embedding -> LSTM 의 입출력 이해
def EmbeddingLSTM(x, vocab_size, embedding_dim, hidden_size, bidirectional, num_layers, device):
'''
x : 데이터 입력 (batch_size, seq_length)
vocab_size : 단어사전의 개수
embedding_dim : 임베딩 차원
hidden_size : 특성추출의 개수(hyper-parameter)
bidirectional : 양방향 특성 추출: 양방향(True), 단방향(False)
num_layers : Stacking LSTM 레이어 수, 기본: 1
'''
x = x.to(device)
batch_size = x.size(0)
print(f'===== Part1. 입력(x) =====\n')
print(f'입력(x)의 차원(batch_size({batch_size}), seq_length({x.size(1)}))')
print(f'{x.shape}\n')
embedding = nn.Embedding(vocab_size, embedding_dim, device=device)
embedding_out = embedding(x)
print(f'===== Part2. Embedding =====\n')
print(f'(batch_size({batch_size}), seq_length({x.size(1)}), embedding_dim({embedding_dim}))')
print(f'{embedding_out.shape}')
lstm = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=bidirectional,
batch_first=True,
device=device
)
bidi = 2 if bidirectional else 1
out, (h, c) = lstm(embedding_out)
print()
print(f'===== Part3. LSTM =====\n')
print('out, (h, c) = lstm(x)\n')
print('LSTM output')
print(f'(batch_size({x.size(0)}), seq_length({x.size(1)}), hidden_size({hidden_size})*bidirectional({bidi}))')
print(f'{out.shape}\n')
print('==='*8)
print('\n(hidden, cell) state\n')
print(f'(num_layers({num_layers})*bidirectional({bidi}), batch_size({batch_size}), hidden_size({hidden_size}))')
print(f'{h.shape}\n')
print('==='*8)
EmbeddingLSTM(x,
vocab_size=len(vocab),
embedding_dim=30,
hidden_size=64,
bidirectional=False,
num_layers=2,
device=device
)
===== Part1. 입력(x) ===== 입력(x)의 차원(batch_size(32), seq_length(19)) torch.Size([32, 19]) ===== Part2. Embedding ===== (batch_size(32), seq_length(19), embedding_dim(30)) torch.Size([32, 19, 30]) ===== Part3. LSTM ===== out, (h, c) = lstm(x) LSTM output (batch_size(32), seq_length(19), hidden_size(64)*bidirectional(1)) torch.Size([32, 19, 64]) ======================== (hidden, cell) state (num_layers(2)*bidirectional(1), batch_size(32), hidden_size(64)) torch.Size([2, 32, 64]) ========================
모델
from tqdm import tqdm # Progress Bar 출력
import numpy as np
import torch.nn as nn
import torch.optim as optim
class TextClassificationModel(nn.Module):
def __init__(self, num_classes, vocab_size, embedding_dim, hidden_size, num_layers, bidirectional=True, drop_prob=0.1):
super(TextClassificationModel, self).__init__()
self.num_classes = num_classes
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.hidden_size = hidden_size
self.num_layers = num_layers
self.bidirectional = 2 if bidirectional else 1
self.embedding = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=embedding_dim)
self.lstm = nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
bidirectional=bidirectional,
)
self.dropout = nn.Dropout(drop_prob)
self.relu = nn.ReLU()
self.fc = nn.Linear(hidden_size*self.bidirectional, hidden_size)
self.output = nn.Linear(hidden_size, num_classes)
def init_hidden_and_cell_state(self, batch_size, device):
# LSTM 입력시 초기 Cell 에 대한 가중치 초기화를 진행합니다.
# (num_layers*bidirectional, batch_size, hidden_size)
self.hidden_and_cell = (
torch.zeros(self.num_layers*self.bidirectional, batch_size, self.hidden_size).to(device),
torch.zeros(self.num_layers*self.bidirectional, batch_size, self.hidden_size).to(device),
)
def forward(self, x):
x = self.embedding(x)
output, (h, c) = self.lstm(x, self.hidden_and_cell)
# (batch_size, seq_length, hidden_size*bidirectional)
# last sequence 의 (batch_size, hidden_size*bidirectional)
h = output[:, -1, :]
o = self.dropout(h)
o = self.relu(self.fc(o))
o = self.dropout(o)
return self.output(o)
모델의 설정(hyper-parameter) 를 정의합니다.
config = {
'num_classes': 2,
'vocab_size': len(vocab),
'embedding_dim': 16,
'hidden_size': 32,
'num_layers': 2,
'bidirectional': True,
}
model = TextClassificationModel(**config)
model.to(device)
TextClassificationModel( (embedding): Embedding(1000, 16) (lstm): LSTM(16, 32, num_layers=2, batch_first=True, bidirectional=True) (dropout): Dropout(p=0.1, inplace=False) (relu): ReLU() (fc): Linear(in_features=64, out_features=32, bias=True) (output): Linear(in_features=32, out_features=2, bias=True) )
손실함수 및 옵티마이저 정의
# loss 정의: CrossEntropyLoss
loss_fn = nn.CrossEntropyLoss()
# 옵티마이저 정의: bert.paramters()와 learning_rate 설정
optimizer = optim.Adam(model.parameters(), lr=0.001)
훈련(model_train) / 검증(model_evaluate) 함수 정의
def model_train(model, data_loader, loss_fn, optimizer, device):
# 모델을 훈련모드로 설정합니다. training mode 일 때 Gradient 가 업데이트 됩니다. 반드시 train()으로 모드 변경을 해야 합니다.
model.train()
# loss와 accuracy 계산을 위한 임시 변수 입니다. 0으로 초기화합니다.
running_loss = 0
corr = 0
counts = 0
# 예쁘게 Progress Bar를 출력하면서 훈련 상태를 모니터링 하기 위하여 tqdm으로 래핑합니다.
prograss_bar = tqdm(data_loader, unit='batch', total=len(data_loader), mininterval=1)
# mini-batch 학습을 시작합니다.
for idx, (txt, lbl) in enumerate(prograss_bar):
# txt, lbl 데이터를 device 에 올립니다. (cuda:0 혹은 cpu)
txt = txt.to(device)
lbl = lbl.to(device)
# 누적 Gradient를 초기화 합니다.
optimizer.zero_grad()
# LSTM Weight 초기화
model.init_hidden_and_cell_state(len(txt), device)
# Forward Propagation을 진행하여 결과를 얻습니다.
output = model(txt)
# 손실함수에 output, lbl 값을 대입하여 손실을 계산합니다.
loss = loss_fn(output, lbl)
# 오차역전파(Back Propagation)을 진행하여 미분 값을 계산합니다.
loss.backward()
# 계산된 Gradient를 업데이트 합니다.
optimizer.step()
# Probability Max index 를 구합니다.
output = output.argmax(dim=1)
# 정답 개수를 구합니다.
corr += (output == lbl).sum().item()
counts += len(lbl)
# batch 별 loss 계산하여 누적합을 구합니다.
running_loss += loss.item()
# 프로그레스바에 학습 상황 업데이트
prograss_bar.set_description(f"training loss: {running_loss/(idx+1):.5f}, training accuracy: {corr / counts:.5f}")
# 누적된 정답수를 전체 개수로 나누어 주면 정확도가 산출됩니다.
acc = corr / len(data_loader.dataset)
# 평균 손실(loss)과 정확도를 반환합니다.
# train_loss, train_acc
return running_loss / len(data_loader), acc
def model_evaluate(model, data_loader, loss_fn, device):
# model.eval()은 모델을 평가모드로 설정을 바꾸어 줍니다.
# dropout과 같은 layer의 역할 변경을 위하여 evaluation 진행시 꼭 필요한 절차 입니다.
model.eval()
# Gradient가 업데이트 되는 것을 방지 하기 위하여 반드시 필요합니다.
with torch.no_grad():
# loss와 accuracy 계산을 위한 임시 변수 입니다. 0으로 초기화합니다.
corr = 0
running_loss = 0
# 배치별 evaluation을 진행합니다.
for txt, lbl in data_loader:
# txt, lbl 데이터를 device 에 올립니다. (cuda:0 혹은 cpu)
txt = txt.to(device)
lbl = lbl.to(device)
# LSTM Weight 초기화
model.init_hidden_and_cell_state(len(txt), device)
# 모델에 Forward Propagation을 하여 결과를 도출합니다.
output = model(txt)
# 검증 손실을 구합니다.
loss = loss_fn(output, lbl)
# Probability Max index 를 구합니다.
output = output.argmax(dim=1)
# 정답 개수를 구합니다.
corr += (output == lbl).sum().item()
# batch 별 loss 계산하여 누적합을 구합니다.
running_loss += loss.item()
# validation 정확도를 계산합니다.
# 누적한 정답숫자를 전체 데이터셋의 숫자로 나누어 최종 accuracy를 산출합니다.
acc = corr / len(data_loader.dataset)
# 결과를 반환합니다.
# val_loss, val_acc
return running_loss / len(data_loader), acc
# 최대 Epoch을 지정합니다.
num_epochs = 10
# checkpoint로 저장할 모델의 이름을 정의 합니다.
model_name = 'LSTM-Text-Classification'
min_loss = np.inf
# Epoch 별 훈련 및 검증을 수행합니다.
for epoch in range(num_epochs):
# Model Training
# 훈련 손실과 정확도를 반환 받습니다.
train_loss, train_acc = model_train(model, train_loader, loss_fn, optimizer, device)
# 검증 손실과 검증 정확도를 반환 받습니다.
val_loss, val_acc = model_evaluate(model, valid_loader, loss_fn, device)
# val_loss 가 개선되었다면 min_loss를 갱신하고 model의 가중치(weights)를 저장합니다.
if val_loss < min_loss:
print(f'[INFO] val_loss has been improved from {min_loss:.5f} to {val_loss:.5f}. Saving Model!')
min_loss = val_loss
torch.save(model.state_dict(), f'{model_name}.pth')
# Epoch 별 결과를 출력합니다.
print(f'epoch {epoch+1:02d}, loss: {train_loss:.5f}, acc: {train_acc:.5f}, val_loss: {val_loss:.5f}, val_accuracy: {val_acc:.5f}')
training loss: 0.65784, training accuracy: 0.59891: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from inf to 0.59589. Saving Model! epoch 01, loss: 0.65784, acc: 0.59891, val_loss: 0.59589, val_accuracy: 0.67690
training loss: 0.54035, training accuracy: 0.72991: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from 0.59589 to 0.48574. Saving Model! epoch 02, loss: 0.54035, acc: 0.72991, val_loss: 0.48574, val_accuracy: 0.76507
training loss: 0.45321, training accuracy: 0.78827: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from 0.48574 to 0.43589. Saving Model! epoch 03, loss: 0.45321, acc: 0.78827, val_loss: 0.43589, val_accuracy: 0.79614
training loss: 0.40567, training accuracy: 0.81462: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from 0.43589 to 0.41093. Saving Model! epoch 04, loss: 0.40567, acc: 0.81462, val_loss: 0.41093, val_accuracy: 0.80794
training loss: 0.37570, training accuracy: 0.83072: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from 0.41093 to 0.40387. Saving Model! epoch 05, loss: 0.37570, acc: 0.83072, val_loss: 0.40387, val_accuracy: 0.81936
training loss: 0.35209, training accuracy: 0.84368: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from 0.40387 to 0.39869. Saving Model! epoch 06, loss: 0.35209, acc: 0.84368, val_loss: 0.39869, val_accuracy: 0.81524
training loss: 0.33078, training accuracy: 0.85407: 100%|█| 668/668 [00:02<00:00
[INFO] val_loss has been improved from 0.39869 to 0.38178. Saving Model! epoch 07, loss: 0.33078, acc: 0.85407, val_loss: 0.38178, val_accuracy: 0.82797
training loss: 0.32096, training accuracy: 0.85908: 100%|█| 668/668 [00:03<00:00
[INFO] val_loss has been improved from 0.38178 to 0.37504. Saving Model! epoch 08, loss: 0.32096, acc: 0.85908, val_loss: 0.37504, val_accuracy: 0.83134
training loss: 0.30628, training accuracy: 0.86737: 100%|█| 668/668 [00:03<00:00
epoch 09, loss: 0.30628, acc: 0.86737, val_loss: 0.37844, val_accuracy: 0.83377
training loss: 0.29536, training accuracy: 0.87200: 100%|█| 668/668 [00:02<00:00
epoch 10, loss: 0.29536, acc: 0.87200, val_loss: 0.37915, val_accuracy: 0.83077
저장한 가중치 로드
# 가중치 로드
model.load_state_dict(torch.load(f'{model_name}.pth'))
최종 검증손실 및 정확도 확인
# evaluation mode
model.eval()
with torch.no_grad():
val_loss, val_acc = model_evaluate(model, valid_loader, loss_fn, device)
print(f'loss: {val_loss:.5f}, accuracy: {val_acc:.5f}')
loss: 0.37504, accuracy: 0.83134
댓글남기기