🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
최근접 이웃 (KNN) 알고리즘을 활용한 분류
K-Nearest Neighbors 이른바, 최근접 이웃 분류 알고리즘을 활용한 간단한 머신러닝 분류 문제를 풀어보도록 하겠습니다. 알고리즘은 동작 원리는 매우 직관적이고 단순 합니다. 이해는 어렵지 않으나, 복잡한 분류 문제에 있어서는 모델의 성능에 대한 큰 기대를 하기 어렵습니다.
scikit-learn 내부에 구현된 알고리즘으로 손쉽게 머신러닝을 돌려볼 수 있습니다.
sklearn.neighbors 패키지 안에 KNeighborsClassifier 을 import 할 수 있습니다.
자세한 설명은 실습 코드 내에 기재해 놓았습니다. 핵심 hyperparameter는 n_neighbors 입니다.
코드

from IPython.display import Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
분류 (Classification)
K Nearest Neighbors (k-최근접 이웃 분류 알고리즘)
가장 중요한 hyperparameter인 K값은 근처에 참고(reference)할 이웃의 숫자
- k-최근접 이웃 분류 알고리즘
- 가장 고전적이고 직관적인 머신러닝 분류 알고리즘
- 기하학적 거리 분류기
- 가장 가깝게 위치하는 멤버로 분류하는 방식
Image(url='https://miro.medium.com/max/405/0*QyWp7J6eSz0tayc0.png', width=500)
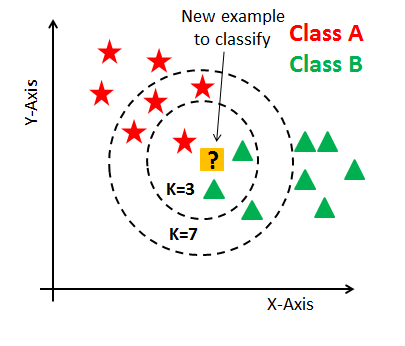
더미 데이터를 활용한 분류 원리 이해
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_classification
fig, axes = plt.subplots(3, 3)
fig.set_size_inches(15, 15)
for i in range(9):
# 더미 데이터 생성
X, y = make_classification(n_samples=50, n_features=2, n_informative=2, n_redundant=0, random_state=30)
blue = X[y==0]
red = X[y==1]
# 랜덤한 새로운 점 생성
newcomer = np.random.randn(1, 2)
# K
K = 3*(i//3+1)
axes[i//3, i%3].scatter(red[:,0], red[:, 1], 80, 'r', '^')
axes[i//3, i%3].scatter(blue[:,0], blue[:, 1], 80, 'b', '^')
axes[i//3, i%3].scatter(newcomer[:, 0], newcomer[:, 1], 80, 'g', 'o')
# n_neighbors=3
knn = KNeighborsClassifier(n_neighbors=3*(i//3+1))
knn.fit(X, y)
pred = knn.predict(newcomer)
# 표기
axes[i//3, i%3].annotate('red' if pred==1 else 'blue', xy=newcomer[0], xytext=(newcomer[0]), fontsize=12)
plt.tight_layout()
plt.show()

mnist (손글씨) 데이터셋을 활용한 분류
mnist (손글씨) 데이터셋을 활용하여 0~9까지 분류하는 분류기를 만듭니다.
sklearn.datasets 보다 고해상도 이미지이기 때문에 tensorflow.keras.datasets을 활용합니다.
from tensorflow.keras.datasets import mnist
(x_digit, y_digit), (_, _15) = mnist.load_data()
x_digit, y_digit = x_digit[:5000], y_digit[:5000]
x_digit = x_digit.reshape(-1, 28*28)
x_digit.shape
mnist (손글씨) 데이터 시각화
w, h = 2, 5
fig, axes = plt.subplots(w, h)
fig.set_size_inches(12, 6)
for i in range(w*h):
axes[i//h, i%h].imshow(x_digit[i].reshape(-1, 28))
axes[i//h, i%h].set_title(y_digit[i], fontsize=20)
axes[i//h, i%h].axis('off')
plt.tight_layout()
plt.show()

데이터 셋 분할
학습용(train) 데이터셋과 검증 (혹은 테스트)용 데이터 셋을 분할 합니다.
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(x_digit, y_digit, stratify=y_digit, random_state=30, test_size=0.1)
x_train.shape, x_valid.shape
모델 정의
KNeighborsClassifier를 정의 하고 핵심 hyperparameter 인 n_neighbors를 지정합니다.
임의로 5개의 이웃을 보도록 n_neighbors=5로 지정하겠습니다.
그리고, n_jobs 옵션은 학습에 사용할 코어의 숫자를 지정합니다. -1로 지정하면, 모든 코어를 사용하도록 합니다.
knn = KNeighborsClassifier(n_neighbors=5, n_jobs=-1)
학습 (fit)
knn.fit(x_train, y_train)
예측 (predict)
prediction = knn.predict(x_valid)
검증 (evaluation)
정확도 (Accuracy) 산출
(prediction == y_valid).mean()
knn.score(x_valid, y_valid)
최적의 n_neighbors 찾기
for k in range(1, 11):
knn = KNeighborsClassifier(n_neighbors=k, n_jobs=-1)
knn.fit(x_train, y_train)
score = knn.score(x_valid, y_valid)
print('k: %d, accuracy: %.2f' % (k, score*100))
Iris 붓꽃 데이터셋을 활용한 실습
필요한 데이터셋 불러오기 (load_iris)
from sklearn.datasets import load_iris
iris = load_iris()
데이터프레임 (DataFrame) 만들기
df = pd.DataFrame(iris['data'], columns=iris['feature_names'])
df['target'] = iris['target']
df.head()
데이터 셋 분할
학습용(train) 데이터셋과 검증 (혹은 테스트)용 데이터 셋을 분할 합니다.
x_train, x_valid, y_train, y_valid = train_test_split(df.iloc[:, :4], df['target'], stratify=df['target'], test_size=0.2, random_state=30)
잘 로드가 되었는지 shape를 확인하도록 합니다.
x_train.shape, y_train.shape
x_valid.shape, y_valid.shape
모델 정의
knn = KNeighborsClassifier()
학습 (fit)
knn.fit(x_train, y_train)
검증 (evaluation)
prediction = knn.predict(x_valid)
(prediction == y_valid).mean()
knn.score(x_valid, y_valid)
최적의 k 값 찾기
for k in range(1, 11):
knn = KNeighborsClassifier(n_neighbors=k, n_jobs=-1)
knn.fit(x_train, y_train)
score = knn.score(x_valid, y_valid)
print('k: %d, accuracy: %.2f' % (k, score*100))
댓글남기기