🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
Lasso, Ridge, ElasticNet-L1, L2규제를 적용한 선형 알고리즘
선형 알고리즘에 기반한 알고리즘에 대해서 알아보고 회귀 (Regression) 문제를 다뤄보도록 하겠습니다. 이번 선형 알고리즘에 기반한 회귀 문제를 다룰 때 L1, L2 규제의 개념이 등장합니다. L1, L2 규제는 딥러닝까지 쭉 이어지는 개념이고, 앞으로 머신러닝/딥러닝 학습시 과대 적합을 최대한 방지하기 위한 용도로 규제를 적용합니다.
최소제곱법에 근거한 선형 알고리즘인 Linear Regression에 L1, L2 규제를 적용한 알고리즘을 어떻게 scikit-learn 패키지에서 가져다 사용할 수 있는지놔 규제 계수인 alpha값의 변화에 따라 어떻게 모델의 성능이 달라지는지도 모니터링 해보도록 하겠습니다.
실습의 끝자락에는 Pipeline의 개념도 등장하며, PolynomialFeature를 활용한 feature 생성 그리고 StandardScaler와 MinMaxScaler를 활용한 전처리까지 바로 Pipeline을 활용하여 쉽게 적용해볼 수 있는 방법까지 알아보도록 하겠습니다.
코드

# 튜토리얼 진행을 위한 모듈 import
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
np.set_printoptions(suppress=True, precision=3)
회귀 (regression)
회귀 분석(regression analysis)은 관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한뒤 적합도를 측정해 내는 분석 방법입니다.
하나의 종속변수와 하나의 독립변수 사이의 관계를 분석할 경우를 단순회귀분석(simple regression analysis), 하나의 종속변수와 여러 독립변수 사이의 관계를 규명하고자 할 경우를 다중회귀분석(multiple regression analysis)이라고 합니다.
예시
- 주택 가격 예측
- 매출액 예측
- 주가 예측
- 온도 예측
대표적인 회귀 모델로는
- 최소제곱법(Ordinary Least Squares)을 활용한 LinearRegression
- 경사하강법(Gradient Descent)을 활용한 SGDRegressor
- 선형 회귀 모델에 L1, L2 규제를 더한 Lasso, Ridge, ElasticNet
등이 있습니다.
회귀 모델을 위한 평가 지표
def make_linear(w=0.5, b=0.8, size=50, noise=1.0):
x = np.arange(size)
y = w * x + b
noise = np.random.uniform(-abs(noise), abs(noise), size=y.shape)
yy = y + noise
plt.figure(figsize=(10, 7))
plt.plot(x, y, color='r', label=f'y = {w}*x + {b}')
plt.scatter(x, yy, label='data')
plt.legend(fontsize=20)
plt.show()
print(f'w: {w}, b: {b}')
return x, y, yy
x, y_true, y_pred = make_linear(size=50, w=1.5, b=0.8, noise=5.5)

R2 Score (결정계수)
- 통계학 회귀분석에서 자주 쓰이는 회귀 평가 지표.
- 실제 값의 분산 대비 예측 값의 분산 비율을 나타냅니다.
- 1에 가까울 수록 좋은 모델, 0에 가까울 수록 나쁨, 음수가 나오면 잘못 평가 되었음을 의미합니다.
Image(url='https://miro.medium.com/max/2812/1*_HbrAW-tMRBli6ASD5Bttw.png', width=350)
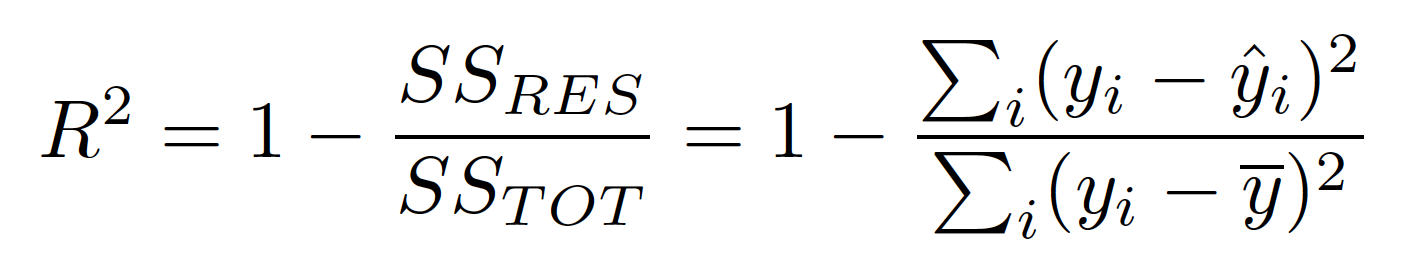
Python 코드로 위의 수식을 그대로 구현합니다.
r2 = 1 - ((y_true - y_pred)**2).sum() / ((y_true - y_true.mean())**2).sum()
print('r2 score = {:.3f}'.format(r2))
sklearn.metrics패키지에 r2_score로 구현
from sklearn.metrics import r2_score
r2_ = r2_score(y_true, y_pred)
print('r2 score = {:.3f}'.format(r2_))
MSE(Mean Squared Error)
- 예측 값과 실제 값의 차이에 대한 제곱에 대하여 평균을 낸 값
- MSE 오차가 작으면 작을수록 좋지만, 과대적합이 될 수 있음에 주의합니다.
- 예측 값과 실제 값보다 크게 예측이 되는지 작게 예측되는지 알 수 없습니다.
Image(url='https://blog.kakaocdn.net/dn/qJowI/btqBBUCMNDv/L7bfq2lu0hfsZzCSDx0E5k/img.png', width=300)
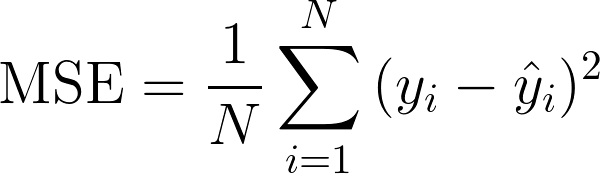
Python 코드로 위의 수식을 그대로 구현합니다.
mse = ((y_true - y_pred)**2).mean()
print('mse = {:.3f}'.format(mse))
sklearn.metrics 패키지에 mean_squared_error를 활용합니다.
from sklearn.metrics import mean_squared_error
mse_ = mean_squared_error(y_true, y_pred)
print('mse = {:.3f}'.format(mse_))
MAE (Mean Absolute Error)
- 예측값과 실제값의 차이에 대한 절대값에 대하여 평균을 낸 값
- 실제 값과 예측 값 차이를 절대 값으로 변환해 평균을 계산합니다. 작을수록 좋지만, 과대적합이 될 수 있음에 주의합니다.
- 스케일에 의존적입니다.
예를 들어, 아파트 집값은 10억, 20억으로 구성되어 있고, 과일 가격은 5000원, 10000원으로 구성되어 있을때,
예측하는 각각 모델의 MSE 가 똑같이 100 이 나왔다고 가정한다며,동일한 오차율이 아님에도 불구하고 동일하게 평가되어 지는 현상이 발생합니다. 이는 MSE 오차에서도 마찬가지 입니다.
Image(url='https://miro.medium.com/max/630/1*OVlFLnMwHDx08PHzqlBDag.gif')
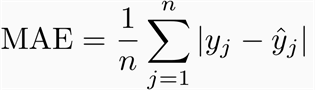
Python 코드로 위의 수식을 그대로 구현합니다.
mae = (np.abs(y_true - y_pred)).mean()
print('mae = {:.3f}'.format(mae))
sklearn.metrics 패키지에 mean_absolute_error를 활용합니다.
from sklearn.metrics import mean_absolute_error
mae_ = mean_absolute_error(y_true, y_pred)
print('mae = {:.3f}'.format(mae_))
RMSE (Root Mean Squared Error)
Image(url='https://miro.medium.com/max/966/1*lqDsPkfXPGen32Uem1PTNg.png', width=350)
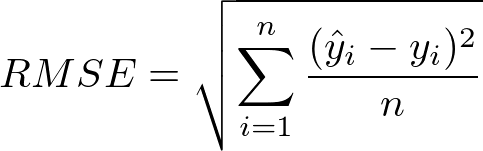
- 예측값과 실제값의 차이에 대한 제곱에 대하여 평균을 낸 뒤 루트를 씌운 값
- MSE의 장단점을 거의 그대로 따라갑니다.
- 제곱 오차에 대한 왜곡을 줄여줍니다.
Python 코드로 위의 수식을 그대로 구현합니다.
rmse = np.sqrt(mse)
print('mse = {:.3f}, rmse = {:.3f}'.format(mse, rmse))
sklearn.metrics 패키지에는 별도로 RMSE 평가지표는 없습니다.
회귀 모델 (Regression Models)
모델별 성능 확인을 위한 함수
import matplotlib.pyplot as plt
import seaborn as sns
my_predictions = {}
my_pred = None
my_actual = None
my_name = None
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato'
]
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True)
plt.figure(figsize=(11, 8))
plt.scatter(df.index, df['prediction'], marker='x', color='r')
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black')
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()
def mse_eval(name_, pred, actual):
global my_predictions, colors, my_pred, my_actual, my_name
my_name = name_
my_pred = pred
my_actual = actual
plot_predictions(name_, pred, actual)
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df) / 2
plt.figure(figsize=(9, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=12)
bars = ax.barh(np.arange(len(df)), df['mse'], height=0.3)
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=12, fontweight='bold', verticalalignment='center')
plt.title('MSE Error', fontsize=16)
plt.xlim(min_, max_)
plt.show()
def add_model(name_, pred, actual):
global my_predictions, my_pred, my_actual, my_name
my_name = name_
my_pred = pred
my_actual = actual
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
def remove_model(name_):
global my_predictions
try:
del my_predictions[name_]
except KeyError:
return False
return True
def plot_all():
global my_predictions, my_pred, my_actual, my_name
plot_predictions(my_name, my_pred, my_actual)
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df) / 2
plt.figure(figsize=(9, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=12)
bars = ax.barh(np.arange(len(df)), df['mse'], height=0.3)
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=12, fontweight='bold', verticalalignment='center')
plt.title('MSE Error', fontsize=16)
plt.xlim(min_, max_)
plt.show()
보스턴 집 값 데이터
데이터 로드 (load_boston)
from sklearn.datasets import load_boston
data = load_boston()
data['data']에는 X 데이터, data['feature_names']에는 컬럼 명입니다.
df = pd.DataFrame(data['data'], columns=data['feature_names'])
target 데이터도 Column 에 추가 합니다.
df['target'] = data['target']
df.head()
컬럼 소개
속성 수 : 13
- CRIM: 범죄율
- ZN: 25,000 평방 피트 당 주거용 토지의 비율
- INDUS: 비소매(non-retail) 비즈니스 면적 비율
- CHAS: 찰스 강 더미 변수 (통로가 하천을 향하면 1; 그렇지 않으면 0)
- NOX: 산화 질소 농도 (천만 분의 1)
- RM:주거 당 평균 객실 수
- AGE: 1940 년 이전에 건축된 자가 소유 점유 비율
- DIS: 5 개의 보스턴 고용 센터까지의 가중 거리
- RAD: 고속도로 접근성 지수
- TAX: 10,000 달러 당 전체 가치 재산 세율
- PTRATIO 도시 별 학생-교사 비율
- B: 1000 (Bk-0.63) ^ 2 여기서 Bk는 도시 별 검정 비율입니다.
- LSTAT: 인구의 낮은 지위
- target: 자가 주택의 중앙값 (1,000 달러 단위)
학습(train) / 테스트(test) 용 데이터를 분할 합니다.
from sklearn.model_selection import train_test_split
SEED=30
x_train, x_test, y_train, y_test = train_test_split(df.drop('target', 1), df['target'], random_state=SEED)
x_train.shape, x_test.shape
x_train.head()
LinearRegression
from sklearn.linear_model import LinearRegression
model = LinearRegression(n_jobs=-1)
- n_jobs: CPU코어의 사용
model.fit(x_train, y_train)
pred = model.predict(x_test)
mse_eval('LinearRegression', pred, y_test)


규제 (Regularization)
학습이 과대적합 되는 것을 방지하고자 일종의 penalty를 부여하는 것
L2 규제 (L2 Regularization)
- 각 가중치 제곱의 합에 규제 강도(Regularization Strength) λ를 곱한다.
- λ를 크게 하면 가중치가 더 많이 감소되고(규제를 중요시함), λ를 작게 하면 가중치가 증가한다(규제를 중요시하지 않음).
L1 규제 (L1 Regularization)
- 가중치의 제곱의 합이 아닌 가중치의 합을 더한 값에 규제 강도(Regularization Strength) λ를 곱하여 오차에 더한다.
- 어떤 가중치(w)는 실제로 0이 된다. 즉, 모델에서 완전히 제외되는 특성이 생기는 것이다.
L2 규제가 L1 규제에 비해 더 안정적이라 일반적으로는 L2규제가 더 많이 사용된다
Ridge (L2 Regularization)
- L2 규제 계수를 적용합니다.
- 선형회귀에 가중치 (weight)들의 제곱합에 대한 최소화를 추가합니다.
주요 hyperparameter
alpha: 규제 계수
수식
$Error=MSE+αw^2$
from sklearn.linear_model import Ridge
규제 계수(alpha)를 정의합니다.
# 값이 커질 수록 큰 규제입니다.
alphas = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001]
for alpha in alphas:
ridge = Ridge(alpha=alpha, random_state=SEED)
ridge.fit(x_train, y_train)
pred = ridge.predict(x_test)
add_model('Ridge(alpha={})'.format(alpha), pred, y_test)
plot_all()


coef_는 feature의 가중치를 보여줍니다.
가중치(weight)를 토대로 회귀 예측시 어떤 feature가 주요하게 영향을 미쳤는지 보여 줍니다.
x_train.columns
ridge.coef_
DataFrame으로 feature별 가중치를 시각화 합니다.
pd.DataFrame(list(zip(x_train.columns, ridge.coef_)), columns=['features', 'importances']).sort_values('importances')
def plot_coef(columns, coef):
coef_df = pd.DataFrame(list(zip(columns, coef)))
coef_df.columns=['feature', 'coef']
coef_df = coef_df.sort_values('coef', ascending=False).reset_index(drop=True)
fig, ax = plt.subplots(figsize=(9, 7))
ax.barh(np.arange(len(coef_df)), coef_df['coef'])
idx = np.arange(len(coef_df))
ax.set_yticks(idx)
ax.set_yticklabels(coef_df['feature'])
fig.tight_layout()
plt.show()
plot_coef(x_train.columns, ridge.coef_)

이번에는, alpha 값에 따른 coef 의 차이를 확인해 봅시다
ridge_100 = Ridge(alpha=100)
ridge_100.fit(x_train, y_train)
ridge_pred_100 = ridge_100.predict(x_test)
ridge_001 = Ridge(alpha=0.001)
ridge_001.fit(x_train, y_train)
ridge_pred_001 = ridge_001.predict(x_test)
plot_coef(x_train.columns, ridge_100.coef_)

plot_coef(x_train.columns, ridge_001.coef_)

Lasso (L1 Regularization)
Lasso(Least Absolute Shrinkage and Selection Operator)
- 선형 회귀에 L1 규제 계수를 적용합니다.
- 가중치(weight)의 절대 값의 합을 최소화 하는 계수를 추가 합니다.
- 불필요한 회귀 계수를 급격히 감소, 0으로 만들어 제거합니다.
- 특성(Feature) 선택에 유리합니다.
주요 hyperparameter
alpha: L1 규제 계수
수식
$Error=MSE+α|w|$
from sklearn.linear_model import Lasso
# 값이 커질 수록 큰 규제입니다.
alphas = [100, 10, 1, 0.1, 0.01, 0.001, 0.0001]
for alpha in alphas:
lasso = Lasso(alpha=alpha)
lasso.fit(x_train, y_train)
pred = lasso.predict(x_test)
add_model('Lasso(alpha={})'.format(alpha), pred, y_test)
plot_all()


lasso_100 = Lasso(alpha=100)
lasso_100.fit(x_train, y_train)
lasso_pred_100 = lasso_100.predict(x_test)
lasso_001 = Lasso(alpha=0.001)
lasso_001.fit(x_train, y_train)
lasso_pred_001 = lasso_001.predict(x_test)
plot_coef(x_train.columns, lasso_001.coef_)

lasso_001.coef_
Lasso 모델에 너무 큰 alpha 계수를 적용하면 대부분의 feature들의 가중치가 0으로 수렴합니다.
plot_coef(x_train.columns, lasso_100.coef_)

lasso_100.coef_
ElasticNet
Elastic Net 회귀모형은 가중치의 절대값의 합(L1)과 제곱합(L2)을 동시에 제약 조건으로 가지는 모형입니다.
Image(url='https://miro.medium.com/max/1312/1*j_DDK7LbVrejTq0tfmavAA.png', width=500)
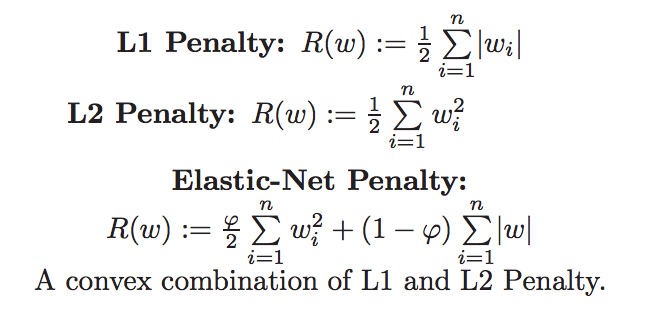
주요 hyperparameter
alpha: 규제 계수
l1_ratio (default=0.5)
- l1_ratio = 0 (L2 규제만 사용).
- l1_ratio = 1 (L1 규제만 사용).
- 0 < l1_ratio < 1 (L1 and L2 규제의 혼합사용)
from sklearn.linear_model import ElasticNet
alpha=0.01
ratios = [0.2, 0.5, 0.8]
for ratio in ratios:
elasticnet = ElasticNet(alpha=alpha, l1_ratio=ratio, random_state=SEED)
elasticnet.fit(x_train, y_train)
pred = elasticnet.predict(x_test)
add_model('ElasticNet(l1_ratio={})'.format(ratio), pred, y_test)
plot_all()


elsticnet_20 = ElasticNet(alpha=5, l1_ratio=0.2)
elsticnet_20.fit(x_train, y_train)
elasticnet_pred_20 = elsticnet_20.predict(x_test)
elsticnet_80 = ElasticNet(alpha=5, l1_ratio=0.8)
elsticnet_80.fit(x_train, y_train)
elasticnet_pred_80 = elsticnet_80.predict(x_test)
plot_coef(x_train.columns, elsticnet_20.coef_)

plot_coef(x_train.columns, elsticnet_80.coef_)

Scaler 적용
from sklearn.preprocessing import MinMaxScaler, StandardScaler
MinMaxScaler (정규화)
정규화 (Normalization)도 표준화와 마찬가지로 데이터의 스케일을 조정합니다.
정규화가 표준화와 다른 가장 큰 특징은 모든 데이터가 0 ~ 1 사이의 값을 가집니다.
즉, 최대값은 1, 최소값은 0으로 데이터의 범위를 조정합니다.
minmax_scaler = MinMaxScaler()
minmax_scaled = minmax_scaler.fit_transform(x_train)
round(pd.DataFrame(minmax_scaled).describe(), 2)
min값과 max값을 0~1사이로 정규화
minmax_scaler = MinMaxScaler()
minmax_scaled = minmax_scaler.fit_transform(x_train)
round(pd.DataFrame(minmax_scaled).describe(), 2)
StandardScaler (표준화)
표준화는 데이터의 평균을 0 분산 및 표준편차를 1로 만들어 줍니다.
표준화를 하는 이유
- 서로 다른 통계 데이터들을 비교하기 용이하기 때문입니다.
- 표준화를 하면 평균은 0, 분산과 표준편차는 1로 만들어 데이터의 분포를 단순화 시키고, 비교를 용이하게 합니다.
Image(url='https://t1.daumcdn.net/cfile/tistory/999EC6335CDE8D8131', width=100)

std_scaler = StandardScaler()
std_scaled = std_scaler.fit_transform(x_train)
round(pd.DataFrame(std_scaled).describe(), 2)
파이프라인 (pipeline)
scikit-learn의 전처리(pre-processing)용 모듈과 모델의 학습 기능을 파이프라인으로 합칠 수 있습니다.
- 파이프라인으로 결합된 모형은 원래의 모형이 가지는
fit,predict함수를 가집니다. - 파이프라인에 정의된 순서에 따라 전처리 모듈이 먼저 호출되어 전처리 과정을 거친 후 모델이 학습하게 됩니다.
from sklearn.pipeline import make_pipeline
pipeline = make_pipeline(
MinMaxScaler(),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)
pipeline.fit(x_train, y_train)
pipeline_pred = pipeline.predict(x_test)
mse_eval('MinMax ElasticNet', pipeline_pred, y_test)


pipeline = make_pipeline(
StandardScaler(),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)
pipeline.fit(x_train, y_train)
pipeline_pred = pipeline.predict(x_test)
mse_eval('Standard ElasticNet', pipeline_pred, y_test)


Polynomial Features
다항식의 계수간 상호작용을 통해 새로운 feature를 생성합니다.
예를들면, [a, b] 2개의 feature가 존재한다고 가정하고,
degree=2로 설정한다면, polynomial features 는 [1, a, b, a^2, ab, b^2] 가 됩니다.
주의
degree를 올리면, 기하급수적으로 많은 feature 들이 생겨나며, 학습 데이터에 지나치게 과대적합 될 수 있습니다.
주요 hyperparameter
degree: 차수include_bias: 1로 채운 컬럼 추가 여부
from sklearn.preprocessing import PolynomialFeatures
x = np.arange(5).reshape(-1, 1)
x
degree=2, include_bias=False 인 경우
poly = PolynomialFeatures(degree=2, include_bias=False)
x_poly = poly.fit_transform(x)
x_poly
degree=2, include_bias=True 인 경우
poly = PolynomialFeatures(degree=2, include_bias=True)
x_poly = poly.fit_transform(x)
x_poly
degree=3, include_bias=True 인 경우
poly = PolynomialFeatures(degree=3, include_bias=True)
x_poly = poly.fit_transform(x)
x_poly
보스톤 집 값 데이터의 features에 PolynomialFeatures를 적용합니다.
poly = PolynomialFeatures(degree=2, include_bias=False)
poly_features = poly.fit_transform(x_train)[0]
poly_features
PolynomialFeature도 파이프라인(pipeline)을 활용하여 전처리 해준다면, 손쉽게 구현 및 적용이 가능합니다.
poly_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False),
ElasticNet(alpha=0.1, l1_ratio=0.2)
)
poly_pipeline.fit(x_train, y_train)
poly_pred = poly_pipeline.predict(x_test)
mse_eval('Poly ElasticNet', poly_pred, y_test)


댓글남기기