🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
scikit-learn 데이터 전처리
데이터 전처리는 데이터 분석 및 머신러닝 학습을 위해서 매우 중요한 단계 입니다. 실무 프로젝트에서는 전체 프로젝트 기간 중 평균 50~70% 이상 시간을 전처리 및 EDA에 투자한다고 합니다. 그만큼 좋은 전처리를 하면 할수록 좋은 성능을 내는 머신러닝 모델을 만들 수 있습니다.
이번 주제는 바로 전처리(pre-processing) 입니다.
scikit-learn 패키지를 활용한 전처리를 알아보도록 하겠습니다.
코드

scikit-learn 전처리
from IPython.display import Image
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
표준화 (Standardization)
표준화는 데이터의 평균을 0 분산 및 표준편차를 1로 만들어 줍니다.
표준화를 하는 이유
- 서로 다른 통계 데이터들을 비교하기 용이하기 때문입니다.
- 표준화를 하면 평균은 0, 분산과 표준편차는 1로 만들어 데이터의 분포를 단순화 시키고, 비교를 용이하게 합니다.
표준화 공식
Image(url='https://t1.daumcdn.net/cfile/tistory/999EC6335CDE8D8131', width=100)

샘플데이터
iris 붓꽃 샘플데이터를 가져옵니다.
from sklearn.datasets import load_iris
# iris 데이터를 가져옵니다.
iris = load_iris()
x = iris['data']
y = iris['target']
4개의 feature 데이터 중 1개의 feature만 임의로 선택합니다.
X = x[:, 0]
표준화 코드 구현
표준화를 Python으로 직접 구현하면 다음과 같습니다. 공식을 그대로 코드로 옮기면 됩니다.
X_ = (X - X.mean()) / X.std()
시각화
시각화로 표준화의 전과 후를 비교합니다.
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.distplot(X, bins=5, color='b')
plt.title('Original', fontsize=16)
plt.subplot(1, 2, 2)
sns.distplot(X_, bins=5, color='r')
plt.title('Standardization', fontsize=16)
plt.show()

iris 붓꽃 데이터 분포 시각화
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x[:,0], x[:, 1], hue=y, palette='muted')
plt.title('Sepal', fontsize=16)
plt.subplot(1, 2, 2)
sns.scatterplot(x[:,2], x[:, 3], hue=y, palette='muted')
plt.title('Petal', fontsize=16)
plt.show()

StandardScaler의 활용
sklearn.preprocesssing 에 StandardScaler로 표준화 (Standardization) 할 수 있습니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x)
x_scaled[:5]
round(x_scaled.mean(), 2), x_scaled.std()
Scale 전, 후 비교 (시각화)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x[:, 0], x[:, 1], hue=y, palette='muted')
plt.title('Sepal (Original)', fontsize=16)
plt.subplot(1, 2, 2)
sns.scatterplot(x_scaled[:, 0], x_scaled[:, 1], hue=y, palette='muted')
plt.title('Sepal (Scaled)', fontsize=16)
plt.show()

plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x[:, 2], x[:, 3], hue=y, palette='muted')
plt.title('Petal (Original)', fontsize=16)
plt.subplot(1, 2, 2)
sns.scatterplot(x_scaled[:, 2], x_scaled[:, 3], hue=y, palette='muted')
plt.title('Petal (Scaled)', fontsize=16)
plt.show()

정규화 (Normalization)
정규화 (Normalization)도 표준화와 마찬가지로 데이터의 스케일을 조정합니다.
정규화가 표준화와 다른 가장 큰 특징은 모든 데이터가 0 ~ 1 사이의 값을 가집니다.
즉, 최대값은 1, 최소값은 0으로 데이터의 범위를 조정합니다.
정규화 공식
Image(url='https://mblogthumb-phinf.pstatic.net/MjAxODA3MzFfMjgx/MDAxNTMzMDIxNzg5MTkz.odx32KoGhDrjwJHgjb_NslL1Nlmsp4veLz6OULb2q00g.5Ynl7GOds1YAgBgJ_TSiuWjHZfrNWPq3hsHtwCjvNP0g.PNG.angryking/image_4532734831533021765958.png?type=w800', width=200)
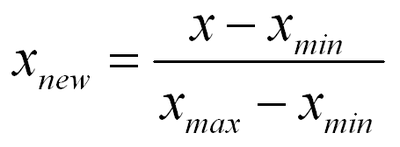 </img>
</img>정규화 코드 구현
# 샘플 데이터를 로드합니다.
X = x[:, 0]
X_ = (X - X.min()) / (X.max() - X.min())
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.distplot(X, bins=5, color='b')
plt.title('Original', fontsize=16)
plt.subplot(1, 2, 2)
sns.distplot(X_, bins=5, color='r')
plt.title('Standardization', fontsize=16)
plt.show()

MinMaxScaler의 활용
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_scaled = scaler.fit_transform(x)
x_scaled[:5]
x_scaled.min(), x_scaled.max()
Scale 전, 후 비교 (시각화)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x[:, 0], x[:, 1], hue=y, palette='muted')
plt.title('Sepal (Original)', fontsize=16)
plt.subplot(1, 2, 2)
sns.scatterplot(x_scaled[:, 0], x_scaled[:, 1], hue=y, palette='muted')
plt.title('Sepal (Scaled)', fontsize=16)
plt.show()

plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.scatterplot(x[:, 2], x[:, 3], hue=y, palette='muted')
plt.title('Petal (Original)', fontsize=16)
plt.subplot(1, 2, 2)
sns.scatterplot(x_scaled[:, 2], x_scaled[:, 3], hue=y, palette='muted')
plt.title('Petal (Scaled)', fontsize=16)
plt.show()

Label Encoder
머신러닝 알고리즘은 문자열 데이터를 입력으로 받지 못합니다.
따라서, 데이터가 가지고 있는 범주형(Categorical) 데이터는 반드시 숫자형(Numerical)으로 변환해주어야 합니다.
LabelEncoder는 범주형(Categorical) 데이터를 수치형으로 인코딩(encoding) 합니다.
여기서 인코딩(encoding) 이란, 문자형 -> 숫자형 데이터로 변환 해주는 것을 의미합니다.
샘플 데이터 (tips)
tips = sns.load_dataset('tips')
tips.head()
tips['day'].value_counts()
plt.figure(figsize=(10, 5))
sns.countplot(tips['day'])
plt.title('Data Counts', fontsize=16)
plt.show()

만약 tips데이터의 day컬럼에서의 값(value)인 [Thur(목), Fri(금), Sat(토), Sun(일)] 을 인코딩(encoding) 해주지 않고 그대로 머신러닝 모델에 학습데이터로 feed한다면 error가 발생합니다.
apply를 활용한 인코딩(encoding)
아래와 같이 encoding이라는 함수를 정의한 후 변환하고자 하는 컬럼에 apply해줌으로써 인코딩을 진행합니다.
def encoding(data):
if data == 'Thur':
return 0
elif data == 'Fri':
return 1
elif data == 'Sat':
return 2
elif data == 'Sun':
return 3
converted = tips['day'].apply(encoding)
converted.value_counts()
인코딩 한 값을 간단히 시각화 해 볼 수 있습니다.
plt.figure(figsize=(10, 5))
sns.countplot(converted)
plt.title('(Encoded) Data Counts', fontsize=16)
plt.show()

LabelEncoder 활용
위와 같이 apply로 변환하고자 하는 컬럼 별로 인코딩을 해줄 수 있지만, sklearn.preprocessing.LabelEncoder를 활용하여 쉽게 인코딩할 수 있습니다.
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
encoded = encoder.fit_transform(tips['day'])
encoded
plt.figure(figsize=(10, 5))
sns.countplot(encoded, order=[3, 0, 1, 2])
plt.title('(Encoded) Data Counts', fontsize=16)
plt.show()

LabelEncoder를 사용하면 원래 class 의 label도 확인할 수 있습니다.
encoder.classes_
Inverse Transform(역변환)
머신러닝 학습을 위하여 어쩔 수 없이 범주형(Categorical) 데이터를 숫자형으로 변환하였다면, 이제 결과 확인을 위하여 다시 역변환이 필요합니다.
이는 LabelEncoder의 inverse_transform을 사용하여 쉽게 역변환할 수 있습니다.
inversed = encoder.inverse_transform(encoded)
inversed
plt.figure(figsize=(10, 5))
sns.countplot(inversed, order=['Thur', 'Fri', 'Sat', 'Sun'])
plt.title('(Inversed) Data Counts', fontsize=16)
plt.show()

댓글남기기