🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
[tensorflow] 가장 기본모델인 Vanilla GAN 구현하기
GAN 이 참 핫합니다. 이번에는 가장 시초격인 Vanila GAN을 구현해 보도록 하겠습니다.
이번 포스팅은 실습을 위한 내용만 다룹니다. GAN 에 대한 기본적인 개념정도는 이해하고 있다는 것을 전제로 합니다.
언어에는 BERT 그리고, 비전분야에서는 GAN이 최근 굉장이 핫한 딥러닝 분야로 떠올랐습니다.
이에 관련한 논문도 쏟아져 나왔습니다.
제 생각에는 연구 분야가 핫해지는 계기는 바로 상업성이 있어서가 아닐까요?
어찌됐건, GAN의 시초격인 Vanila GAN을 구현해 보도록 하겠습니다. 앞서 말씀드렸던 것처럼 개념 설명을 과감하게 건너 뜁니다!
실습 개요
소스코드는 아래 링크에서 다운로드 받을 수 있습니다.
실습은 tensorflow.keras.datasets에 있는 MNIST 데이터셋을 활용합니다.
MNIST 손글씨 데이터를 활용하여 학습한 뒤, GAN으로 가짜 손글씨 데이터를 생성해 내는 것이 이번 실습의 최종 목표입니다!
미리 결과를 보여드리자면, 아래와 같이 됩니다.
Epoch 1 (초기)

Epoch 50 (학습 후)

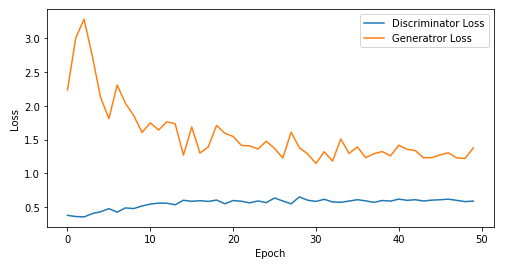
손실 그래프
Vanilla Gan Tutorial!
%%javascript
IPython.OutputArea.auto_scroll_threshold = 9999;
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
generator에서 tanh를 activation으로 활용합니다.
tanh를 활용하면 output이 -1 ~ 1 사이로 나오기 때문에 Normalize를 해줄 때 127.5로 나눈 뒤 1을 빼줍니다.
x_train = x_train / 127.5 - 1
x_test = x_test / 127.5 - 1
min 값과 max 값이 -1 ~ 1사이의 범위를 가져야 합니다.
x_train.min(), x_train.max()
x_train 값은 현재 28 * 28로 되어 있습니다. 이를 Flatten하게 펴줍니다.
x_train = x_train.reshape(-1, 784)
x_train.shape
필요한 모듈을 import 합니다.
from tensorflow.keras.layers import Dense, LeakyReLU, Dropout, Input
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.initializers import RandomNormal
import numpy as np
import matplotlib.pyplot as plt
Hyperparameters
NOISE_DIM을 정의 합니다.
NOISE_DIM은 자유롭게 설정할 수 있으며, generator의 input으로 들어갑니다.
# gan에 입력되는 noise에 대한 dimension
NOISE_DIM = 10
# adam optimizer 정의, learning_rate = 0.0002, beta_1로 줍니다.
# Vanilla Gan과 DCGAN에서 이렇게 셋팅을 해주는데
# 이렇게 해줘야 훨씬 학습을 잘합니다.
adam = Adam(lr=0.0002, beta_1=0.5)
Generator
generator를 정의합니다.
generator = Sequential([
Dense(256, input_dim=NOISE_DIM),
LeakyReLU(0.2),
Dense(512),
LeakyReLU(0.2),
Dense(1024),
LeakyReLU(0.2),
Dense(28*28, activation='tanh'),
])
generator.summary()
Discriminator
discriminator를 정의합니다.
discriminator = Sequential([
Dense(1024, input_shape=(784,), kernel_initializer=RandomNormal(stddev=0.02)),
LeakyReLU(0.2),
Dropout(0.3),
Dense(512),
LeakyReLU(0.2),
Dropout(0.3),
Dense(256),
LeakyReLU(0.2),
Dropout(0.3),
Dense(1, activation='sigmoid')
])
discriminator.summary()
반드시 dicriminator를 compile 해주어야 합니다.
discriminator.compile(loss='binary_crossentropy', optimizer=adam)
Gan
generator와 discriminator를 연결합니다.
# discriminator는 학습을 하지 않도록 하며, Gan 모델에서는 generator만 학습하도록 합니다.
discriminator.trainable = False
gan_input = Input(shape=(NOISE_DIM,))
x = generator(inputs=gan_input)
output = discriminator(x)
gan 모델을 정의합니다.
gan = Model(gan_input, output)
gan.summary()
Compile
gan.compile(loss='binary_crossentropy', optimizer=adam)
Batch
이미지 batch를 생성합니다. MNIST 이미지 batch가 차례대로 생성됩니다.
def get_batches(data, batch_size):
batches = []
for i in range(int(data.shape[0] // batch_size)):
batch = data[i * batch_size: (i + 1) * batch_size]
batches.append(batch)
return np.asarray(batches)
시각화를 위한 유틸 함수 정의
def visualize_training(epoch, d_losses, g_losses):
# 오차에 대한 시각화
plt.figure(figsize=(8, 4))
plt.plot(d_losses, label='Discriminator Loss')
plt.plot(g_losses, label='Generatror Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
print('epoch: {}, Discriminator Loss: {}, Generator Loss: {}'.format(epoch, np.asarray(d_losses).mean(), np.asarray(g_losses).mean()))
#샘플 데이터 생성 후 시각화
noise = np.random.normal(0, 1, size=(24, NOISE_DIM))
generated_images = generator.predict(noise)
generated_images = generated_images.reshape(-1, 28, 28)
plt.figure(figsize=(8, 4))
for i in range(generated_images.shape[0]):
plt.subplot(4, 6, i+1)
plt.imshow(generated_images[i], interpolation='nearest', cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()
학습
BATCH_SIZE = 128
EPOCHS= 50
# discriminator와 gan 모델의 loss 측정을 위한 list 입니다.
d_losses = []
g_losses = []
for epoch in range(1, EPOCHS + 1):
# 각 배치별 학습
for real_images in get_batches(x_train, BATCH_SIZE):
# 랜덤 노이즈 생성
input_noise = np.random.uniform(-1, 1, size=[BATCH_SIZE, NOISE_DIM])
# 가짜 이미지 데이터 생성
generated_images = generator.predict(input_noise)
# Gan에 학습할 X 데이터 정의
x_dis = np.concatenate([real_images, generated_images])
# Gan에 학습할 Y 데이터 정의
y_dis = np.zeros(2 * BATCH_SIZE)
y_dis[:BATCH_SIZE] = 0.9
# Discriminator 훈련
discriminator.trainable = True
d_loss = discriminator.train_on_batch(x_dis, y_dis)
# Gan 훈련
noise = np.random.uniform(-1, 1, size=[BATCH_SIZE, NOISE_DIM])
y_gan = np.ones(BATCH_SIZE)
# Discriminator의 판별 학습을 방지합니다
discriminator.trainable = False
g_loss = gan.train_on_batch(noise, y_gan)
d_losses.append(d_loss)
g_losses.append(g_loss)
if epoch == 1 or epoch % 5 == 0:
visualize_training(epoch, d_losses, g_losses)






















댓글남기기