🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
랭체인(langchain)의 OpenAI GPT 모델(ChatOpenAI) 사용법 (1)
언어 모델을 활용한 애플리케이션 개발을 돕는 프레임워크인 랭체인(LangChain) 에 대해 깊이 있게 다뤄보고자 합니다.
튜토리얼은 시리즈 형식으로 구성되어, 시리즈를 거듭하면서 랭체인(LangChain) 을 통해 언어 모델 기반의 애플리케이션 개발은 더욱 간결하고 효과적으로 이루어질 수 있습니다.
🌱 랭체인의 주요 기능
랭체인을 통해 다음과 같은 특징을 갖는 애플리케이션을 개발할 수 있습니다.
- 문맥 인식: 언어 모델과 다양한 문맥 소스(프롬프트 지시, 예제, 응답의 근거 내용 등)를 연동하며, 사용자의 문맥을 정확히 이해합니다.
- 추론 능력: 제공된 문맥에 기반하여 어떤 대답을 할지, 또는 어떠한 액션을 취할지에 대한 추론이 가능합니다.
랭체인의 가치
랭체인의 핵심적인 가치는 여러 가지가 있지만, 그 중에서도 두 가지 주요한 점을 꼽자면 다음과 같습니다.
- 구성 요소: 사용자는 언어 모델과의 상호작용을 위해 다양한 구성 요소와 추상화를 활용할 수 있습니다. 이러한 구성 요소는 개별적으로, 또는 랭체인 프레임워크 내에서 모듈식으로 쉽게 활용할 수 있습니다.
- 사용 준비된 체인: 특정 고수준 작업을 수행하기 위해 미리 조립된 구성 요소의 패키지입니다.
특히, 이러한 사용 준비된 체인은 초보자도 랭체인을 쉽게 시작할 수 있게 도와주며, 복잡한 애플리케이션을 계획하는 전문가들은 기존 체인을 손쉽게 커스터마이징하거나 새롭게 구축할 수 있게 도와줍니다.
🌱 환경설정
API KEY 발급
먼저, openai 의 API KEY 를 발급 받아야 합니다. 발급은 다음의 절차를 통해 진행할 수 있습니다.
https://platform.openai.com/account/api-keys 로 접속합니다.
Log in 버튼을 클릭 후 계정에 로그인 합니다. 계정이 아직 생성되지 않은 경우에는 Sign up 으로 회원가입 후 로그인 합니다.
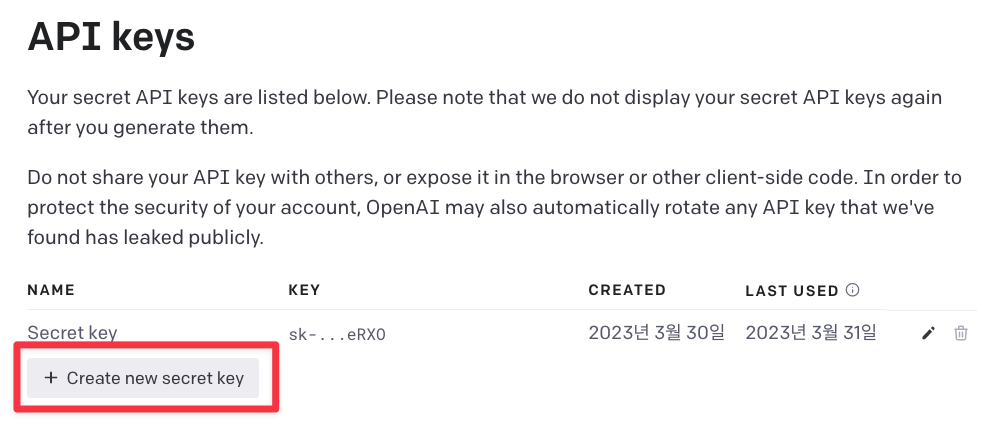
“Create new secret key” 버튼을 클릭하여 새로운 키를 발급합니다.
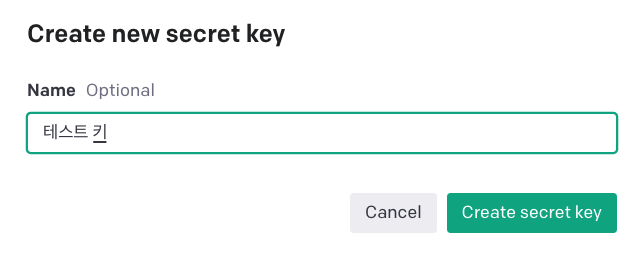
Name 에는 발급하는 키에 대한 별칭을 입력합니다.
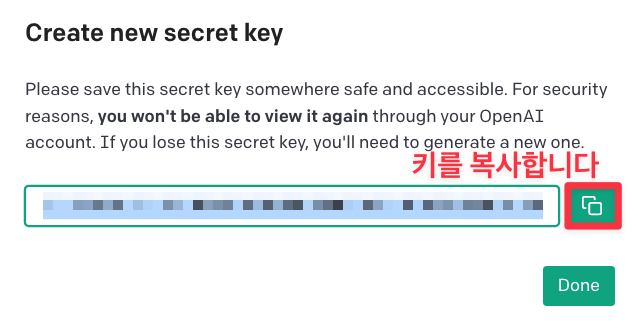
새롭게 발급한 키를 복사합니다. 잃어버리면 다시 발급하여야 하므로, 안전한 곳에 저장해 둡니다.
모듈 설치(openai, langchain)
pip 명령어로 모듈을 설치 합니다. 아나콘다 가상환경에서 설치해도 좋습니다.
# openai 파이썬 패키지 설치
pip install openai langchain
먼저, 설치한 openai 모듈을 import 한 뒤, 발급받은 API KEY를 다음과 같이 설정합니다.
import os
os.environ['OPENAI_API_KEY'] = 'OPENAI API KEY 입력'
사용 가능한 모델 리스트 출력
import openai
model_list = sorted([m['id'] for m in openai.Model.list()['data']])
for m in model_list:
print(m)
ada ada-code-search-code ada-code-search-text ada-search-document ada-search-query ada-similarity babbage babbage-002 babbage-code-search-code babbage-code-search-text babbage-search-document babbage-search-query babbage-similarity code-davinci-edit-001 code-search-ada-code-001 code-search-ada-text-001 code-search-babbage-code-001 code-search-babbage-text-001 curie curie-instruct-beta curie-search-document curie-search-query curie-similarity davinci davinci-002 davinci-instruct-beta davinci-search-document davinci-search-query davinci-similarity gpt-3.5-turbo gpt-3.5-turbo-0301 gpt-3.5-turbo-0613 gpt-3.5-turbo-16k gpt-3.5-turbo-16k-0613 gpt-3.5-turbo-instruct gpt-3.5-turbo-instruct-0914 gpt-4 gpt-4-0314 gpt-4-0613 text-ada-001 text-babbage-001 text-curie-001 text-davinci-001 text-davinci-002 text-davinci-003 text-davinci-edit-001 text-embedding-ada-002 text-search-ada-doc-001 text-search-ada-query-001 text-search-babbage-doc-001 text-search-babbage-query-001 text-search-curie-doc-001 text-search-curie-query-001 text-search-davinci-doc-001 text-search-davinci-query-001 text-similarity-ada-001 text-similarity-babbage-001 text-similarity-curie-001 text-similarity-davinci-001 whisper-1
🔥 ChatOpenAI
OpenAI 사의 채팅 전용 Large Language Model(llm) 입니다.
객체를 생성할 때 다음을 옵션 값을 지정할 수 있습니다. 옵션에 대한 상세 설명은 다음과 같습니다.
temperature
- 사용할 샘플링 온도는 0과 2 사이에서 선택합니다. 0.8과 같은 높은 값은 출력을 더 무작위하게 만들고, 0.2와 같은 낮은 값은 출력을 더 집중되고 결정론적으로 만듭니다.
max_tokens
- 채팅 완성에서 생성할 토큰의 최대 개수입니다.
model_name: 적용 가능한 모델 리스트
-
gpt-3.5-turbo
-
gpt-3.5-turbo-0301
-
gpt-3.5-turbo-0613
-
gpt-3.5-turbo-16k
-
gpt-3.5-turbo-16k-0613
-
gpt-3.5-turbo-instruct
-
gpt-3.5-turbo-instruct-0914
-
gpt-4
-
gpt-4-0314
-
gpt-4-0613
from langchain.chat_models import ChatOpenAI
# 객체 생성
llm = ChatOpenAI(temperature=0, # 창의성 (0.0 ~ 2.0)
max_tokens=2048, # 최대 토큰수
model_name='gpt-3.5-turbo', # 모델명
)
# 질의내용
question = '대한민국의 수도는 뭐야?'
# 질의
print(f'[답변]: {llm.predict(question)}')
[답변]: 대한민국의 수도는 서울입니다.
🔥 프롬프트 템플릿의 활용
PromptTemplate
-
사용자의 입력 변수를 사용하여 완전한 프롬프트 문자열을 만드는 데 사용되는 템플릿입니다
-
사용법
-
template: 템플릿 문자열입니다. 이 문자열 내에서 중괄호{}는 변수를 나타냅니다. -
input_variables: 중괄호 안에 들어갈 변수의 이름을 리스트로 정의합니다.
-
input_variables
-
input_variables는 PromptTemplate에서 사용되는 변수의 이름을 정의하는 리스트입니다.
-
사용법: 리스트 형식으로 변수 이름을 정의합니다.
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 질문 템플릿 형식 정의
template = '{country}의 수도는 뭐야?'
# 템플릿 완성
prompt = PromptTemplate(template=template, input_variables=['country'])
LLMChain 객체
LLMChain
-
LLMChain은 특정 PromptTemplate와 연결된 체인 객체를 생성합니다
-
사용법
-
prompt: 앞서 정의한 PromptTemplate 객체를 사용합니다. -
llm: 언어 모델을 나타내며, 이 예시에서는 이미 어딘가에서 정의된 것으로 보입니다.
-
# 연결된 체인(Chain)객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
① run()
run() 함수로 템플릿 프롬프트 실행
# 체인 실행: run()
print(llm_chain.run(country='일본'))
일본의 수도는 도쿄입니다.
# 체인 실행: run()
print(llm_chain.run(country='캐나다'))
캐나다의 수도는 오타와(Ottawa)입니다.
② apply()
apply() 함수로 여러개의 입력을 한 번에 실행
input_list = [
{'country': '호주'},
{'country': '중국'},
{'country': '네덜란드'}
]
llm_chain.apply(input_list)
[{'text': '호주의 수도는 캔버라입니다.'},
{'text': '중국의 수도는 베이징(北京)입니다.'},
{'text': '네덜란드의 수도는 암스테르담(Amsterdam)입니다.'}]
text 키 값으로 결과 뭉치가 반환되었음을 확인할 수 있습니다.
이를 반복문으로 출력한다면 다음과 같습니다.
# input_list 에 대한 결과 반환
result = llm_chain.apply(input_list)
# 반복문으로 결과 출력
for res in result:
print(res['text'].strip())
호주의 수도는 캔버라입니다. 중국의 수도는 베이징(北京)입니다. 네덜란드의 수도는 암스테르담(Amsterdam)입니다.
③ generate()
generate() 는 문자열 대신에 LLMResult를 반환하는 점을 제외하고는 apply와 유사합니다.
LLMResult는 토큰 사용량과 종료 이유와 같은 유용한 생성 정보를 자주 포함하고 있습니다.
# input_list 에 대한 결과 반환
generated_result = llm_chain.generate(input_list)
print(generated_result)
generations=[[ChatGeneration(text='호주의 수도는 캔버라입니다.', generation_info={'finish_reason': 'stop'}, message=AIMessage(content='호주의 수도는 캔버라입니다.', additional_kwargs={}, example=False))], [ChatGeneration(text='중국의 수도는 베이징(北京)입니다.', generation_info={'finish_reason': 'stop'}, message=AIMessage(content='중국의 수도는 베이징(北京)입니다.', additional_kwargs={}, example=False))], [ChatGeneration(text='네덜란드의 수도는 암스테르담(Amsterdam)입니다.', generation_info={'finish_reason': 'stop'}, message=AIMessage(content='네덜란드의 수도는 암스테르담(Amsterdam)입니다.', additional_kwargs={}, example=False))]] llm_output={'token_usage': {'prompt_tokens': 58, 'completion_tokens': 57, 'total_tokens': 115}, 'model_name': 'gpt-3.5-turbo'} run=[RunInfo(run_id=UUID('957a5369-a20e-470a-bcea-c325b3aafb4a')), RunInfo(run_id=UUID('f5f6f639-76f8-43e3-9103-03aa7eac6fe5')), RunInfo(run_id=UUID('f9c4ce3f-4e5d-47d5-86af-f20c077b754e'))]
# 답변 출력
generated_result.generations
[[ChatGeneration(text='호주의 수도는 캔버라입니다.', generation_info={'finish_reason': 'stop'}, message=AIMessage(content='호주의 수도는 캔버라입니다.', additional_kwargs={}, example=False))],
[ChatGeneration(text='중국의 수도는 베이징(北京)입니다.', generation_info={'finish_reason': 'stop'}, message=AIMessage(content='중국의 수도는 베이징(北京)입니다.', additional_kwargs={}, example=False))],
[ChatGeneration(text='네덜란드의 수도는 암스테르담(Amsterdam)입니다.', generation_info={'finish_reason': 'stop'}, message=AIMessage(content='네덜란드의 수도는 암스테르담(Amsterdam)입니다.', additional_kwargs={}, example=False))]]
# 토큰 사용량 출력
generated_result.llm_output
{'token_usage': {'prompt_tokens': 58,
'completion_tokens': 57,
'total_tokens': 115},
'model_name': 'gpt-3.5-turbo'}
# run ID 출력
generated_result.run
[RunInfo(run_id=UUID('957a5369-a20e-470a-bcea-c325b3aafb4a')),
RunInfo(run_id=UUID('f5f6f639-76f8-43e3-9103-03aa7eac6fe5')),
RunInfo(run_id=UUID('f9c4ce3f-4e5d-47d5-86af-f20c077b754e'))]
# 답변 출력
for gen in generated_result.generations:
print(gen[0].text.strip())
호주의 수도는 캔버라입니다. 중국의 수도는 베이징(北京)입니다. 네덜란드의 수도는 암스테르담(Amsterdam)입니다.
④ 2개 이상의 변수를 템플릿 안에 정의
2개 이상의 변수를 적용하여 템플릿을 생성할 수 있습니다.
이번에는 2개 이상의 변수(input_variables) 를 활용하여 템플릿 구성을 해보겠습니다.
# 질문 템플릿 형식 정의
template = '{area1} 와 {area2} 의 시차는 몇시간이야?'
# 템플릿 완성
prompt = PromptTemplate(template=template, input_variables=['area1', 'area2'])
# 연결된 체인(Chain)객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 체인 실행: run()
print(llm_chain.run(area1='서울', area2='파리'))
서울과 파리의 시차는 8시간입니다. 서울이 파리보다 8시간 앞서 있습니다.
input_list = [
{'area1': '파리', 'area2': '뉴욕'},
{'area1': '서울', 'area2': '하와이'},
{'area1': '켄버라', 'area2': '베이징'}
]
# 반복문으로 결과 출력
result = llm_chain.apply(input_list)
for res in result:
print(res['text'].strip())
파리와 뉴욕의 시차는 일반적으로 6시간입니다. 파리가 뉴욕보다 6시간 앞서 있습니다. 예를 들어, 파리가 오전 9시라면 뉴욕은 오전 3시입니다. 서울과 하와이의 시차는 서울이 하와이보다 19시간 빠릅니다. 예를 들어, 서울이 오전 9시라면 하와이는 전날 오후 2시입니다. 켄버라와 베이징의 시차는 2시간입니다. 켄버라는 오스트레일리아의 수도로 UTC+10 시간대에 위치하고, 베이징은 중국의 수도로 UTC+8 시간대에 위치합니다.
⑤ 스트리밍(streaming)
스트리밍 옵션은 질의에 대한 답변을 실시간으로 받을 때 유용합니다.
다음과 같이 streaming=True 로 설정하고 스트리밍으로 답변을 받기 위한 StreamingStdOutCallbackHandler() 을 콜백으로 지정합니다.
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# 객체 생성
llm = ChatOpenAI(temperature=0, # 창의성 (0.0 ~ 2.0)
max_tokens=2048, # 최대 토큰수
model_name='gpt-3.5-turbo', # 모델명
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()]
)
# 질의내용
question = '대한민국의 수도는 뭐야?'
# 스트리밍으로 답변 출력
response = llm.predict(question)
대한민국의 수도는 서울입니다.
댓글남기기