🔥알림🔥
① 테디노트 유튜브 -
구경하러 가기!
② LangChain 한국어 튜토리얼
바로가기 👀
③ 랭체인 노트 무료 전자책(wikidocs)
바로가기 🙌
④ RAG 비법노트 LangChain 강의오픈
바로가기 🙌
⑤ 서울대 PyTorch 딥러닝 강의
바로가기 🙌
랭체인(langchain) + 허깅페이스(HuggingFace) 모델 사용법 (2)
이번 포스팅에서는 랭체인(LangChain) 을 활용하여 허깅페이스(HuggingFace) 허브 에 배포된 사전학습 모델을 활용하여 LLM 체인을 구성하는 방법에 대하여 다뤄보고자 합니다.
랭체인은 허깅페이스 허브의 앤드포인트(Endpoint) 추론을 활용할 수 있는 래퍼(wrapper) 객체 및 함수를 제공하고 있습니다. 우리는 이를 활용하여 보다 쉽게 허깅페이스 모델을 활용한 서비스를 제작할 수 있습니다.
OpenAI 사의 ChatGPT 비용이 크다면, 공개된 허깅페이스 모델을 활용하는 것도 하나의 대안일 수 있습니다.
(이전글) LangChain 튜토리얼
🌱 HuggingFace Hub 소개
- Hugging Face Hub는 120k 이상의 모델, 20k의 데이터셋, 그리고 50k의 데모 앱(Spaces)을 포함하는 플랫폼입니다.
- 모든 것은 오픈 소스이며 공개적으로 이용할 수 있습니다.
- 이 플랫폼에서 사람들은 쉽게 협업하고 함께 ML을 구축할 수 있습니다.
아래 예시는 Hugging Face Hub에 연결하는 방법과 다양한 모델을 사용하는 방법을 보여줍니다.
🌱 환경설정
① 라이브러리 설치
# 필요한 라이브러리 설치
# !pip install langchain
# !pip install huggingface_hub transformers datasets
② 허깅페이스 토큰 발급
허깅페이스(https://huggingface.co) 에 회원가입을 한 뒤, 아래의 주소에서 토큰 발급을 신청합니다.
- 토큰 발급주소: https://huggingface.co/docs/hub/security-tokens
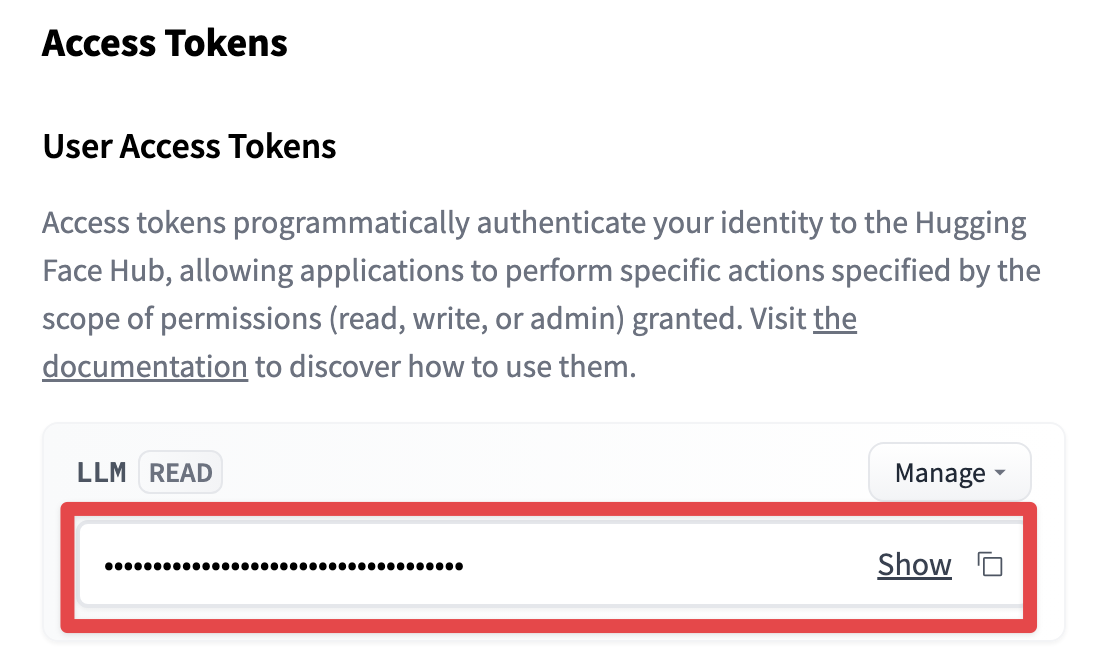
토큰을 발급받은 뒤 아래 주소에서 LLM 의 READ 키를 복사합니다.
- LLM 키: https://huggingface.co/settings/tokens
import os
# 허깅페이스 LLM Read Key
# 이전 단계에서 복사한 Key를 아래에 붙혀넣기 합니다.
os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'HuggingFace LLM Read Key'
🔥 HuggingFaceHub 에 배포된 모델 추론(inference)
허깅페이스 허브에 업로드된 수 많은 모델 중 추론에 활용할 모델을 선택합니다.
선택 기준은 성능을 보통 우선시할 수 있으나, 모델의 크기가 너무 크면 추론 속도가 느릴 수 있습니다. 따라서, 개발목표에 맞는 적절한 모델을 선택하는 것이 중요합니다.
아래는 LLM 리더보드에 등록되어 있는 모델 리스트와 성능을 확인하는 방법 입니다.
① 추론에 활용할 모델 선택
- 허깅페이스 LLM 리더보드: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
LLM Leaderboard
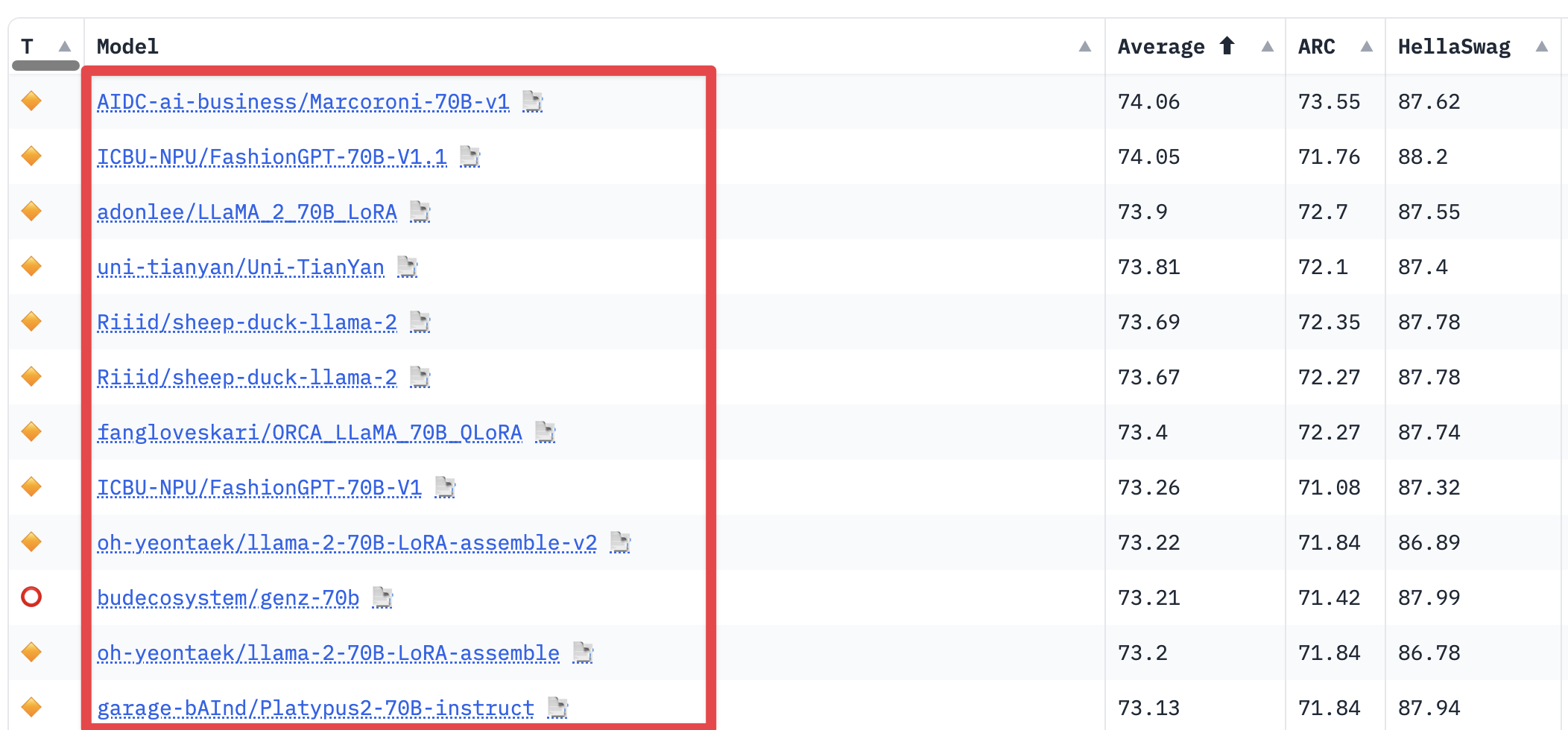
리더보드에 게재된 모델의 성능을 직접 확인할 수 있으며, 모델의 ID 만 알고 있으면 됩니다.
예를 들어, 위의 그림 기준으로 첫 번째 랭크되어 있는 모델의 ID 는 AIDC-ai-business/Marcoroni-70B-v1 입니다.
- 한글 LLM 리더보드: https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard
upstage의 한글 LLM Leaderboard
- 그밖에 모델 리스트: https://huggingface.co/models?pipeline_tag=text-generation&sort=trending
그밖에 업로드된 모델 리스트
② HuggingFaceHub
아래의 코드는 이전에 확인한 허깅페이스 모델 ID 를 활용하여 추론하는 코드입니다.
from langchain import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import HuggingFaceHub
# HuggingFace Repository ID
repo_id = 'mistralai/Mistral-7B-v0.1'
# 질의내용
question = "Who is Son Heung Min?"
# 템플릿
template = """Question: {question}
Answer: """
# 프롬프트 템플릿 생성
prompt = PromptTemplate(template=template, input_variables=["question"])
# HuggingFaceHub 객체 생성
llm = HuggingFaceHub(
repo_id=repo_id,
model_kwargs={"temperature": 0.2,
"max_length": 128}
)
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 실행
print(llm_chain.run(question=question))
26-year-old South Korean professional footballer who plays as a winger for Premier League
# HuggingFace Repository ID
repo_id = 'google/flan-t5-xxl'
# 질의내용
question = "who is Son Heung Min?"
# 템플릿
template = """Question: {question}
Answer: """
# 프롬프트 템플릿 생성
prompt = PromptTemplate(template=template, input_variables=["question"])
# HuggingFaceHub 객체 생성
llm = HuggingFaceHub(
repo_id=repo_id,
model_kwargs={"temperature": 0.2,
"max_length": 512}
)
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
# 실행
print(llm_chain.run(question=question))
South Korean footballer
③ 모델을 직접 다운로드 후 로컬(local)에서 추론
이전 방식은 허깅페이스 서버에서 선택된 모델로 추론하고, 이에 대한 답변을 반환받는 방식입니다.
추론 방식이 간편하지만, 서버의 성능에 따라 다르지만 추론 속도가 대체적으로 오래 걸리는 편입니다. 따라서, 결과를 받는데 시간이 오래 걸리거나, 혹은 답변의 지연시간이 긴 경우, Timeout 에러가 발생할 수 있습니다
만약, 좋은 성능의 GPU 를 탑재한 서버가 있다면, 로컬에 모델을 직접 다운로드 받아 GPU 부스트를 받아서 추론할 수 있습니다. 아래는 예시코드 입니다.
import os
# 허깅페이스 모델/토크나이저를 다운로드 받을 경로
# (예시)
# os.environ['HF_HOME'] = '/home/jovyan/work/tmp'
os.environ['HF_HOME'] = 'LLM 모델을 다운로드 받을 경로'
from langchain import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import HuggingFacePipeline
# HuggingFace Model ID
model_id = 'beomi/llama-2-ko-7b'
# HuggingFacePipeline 객체 생성
llm = HuggingFacePipeline.from_model_id(
model_id=model_id,
device=0, # -1: CPU(default), 0번 부터는 CUDA 디바이스 번호 지정시 GPU 사용하여 추론
task="text-generation", # 텍스트 생성
model_kwargs={"temperature": 0.1,
"max_length": 64},
)
# 템플릿
template = """질문: {question}
답변: """
# 프롬프트 템플릿 생성
prompt = PromptTemplate.from_template(template)
# LLM Chain 객체 생성
llm_chain = LLMChain(prompt=prompt, llm=llm)
실행예시
# 실행
question = "대한민국의 수도는 어디야?"
print(llm_chain.run(question=question))
서울입니다. 계획도시로 잘 만들어진 도시입니다.
실행예시
# 실행
question = "캐나다의 수도와 대한민국의 수도까지의 거리는 어떻게 돼?"
print(llm_chain.run(question=question))
캐나다의 수도는 오타와이고 대한민국의 수도는 서울입니다. 오타와에서 서울까지는 약 1100km 정도 됩니다.
✔️ 참고(References)
- 랭체인(langchain) - HugginfFace Hub: https://python.langchain.com/docs/integrations/llms/huggingface_hub
- 랭체인(langchain) - Hugging Face Local Pipelines: https://python.langchain.com/docs/integrations/llms/huggingface_pipelines
댓글남기기